ChatGLM Tuning
1.0.0
A affordable chatgpt implementation solution, finetune based on Tsinghua's ChatGLM-6B + LoRA.
Dataset: alpaca
Students with colab can try it directly on colab:
Official ptuning code
Convert alpaca dataset to jsonl
python cover_alpaca2jsonl.py
--data_path data/alpaca_data.json
--save_path data/alpaca_data.jsonl
tokenization
python tokenize_dataset_rows.py
--jsonl_path data/alpaca_data.jsonl
--save_path data/alpaca
--max_seq_length 200
--skip_overlength False
--chatglm_path model_path/chatglm
--version v1
--jsonl_path fine-tuned data path, format jsonl, encode the ['context'] and ['target'] fields of each row--save_path output path--max_seq_length sample maximum length--chatglm_path to import the model's path (you can choose different paths of chatglm or chatglm2)--version model version (v1 refers to chatglm, v2 refers to chatglm2)python finetune.py
--dataset_path data/alpaca
--lora_rank 8
--per_device_train_batch_size 6
--gradient_accumulation_steps 1
--max_steps 52000
--save_steps 1000
--save_total_limit 2
--learning_rate 1e-4
--fp16
--remove_unused_columns false
--logging_steps 50
--output_dir output
--chatglm_path model_path/chat_glmReference infer.ipynb
After using the Alpaca dataset to perform better on the Alpaca dataset:
Answer: It is the output of the model#### Answer: It's the original answer 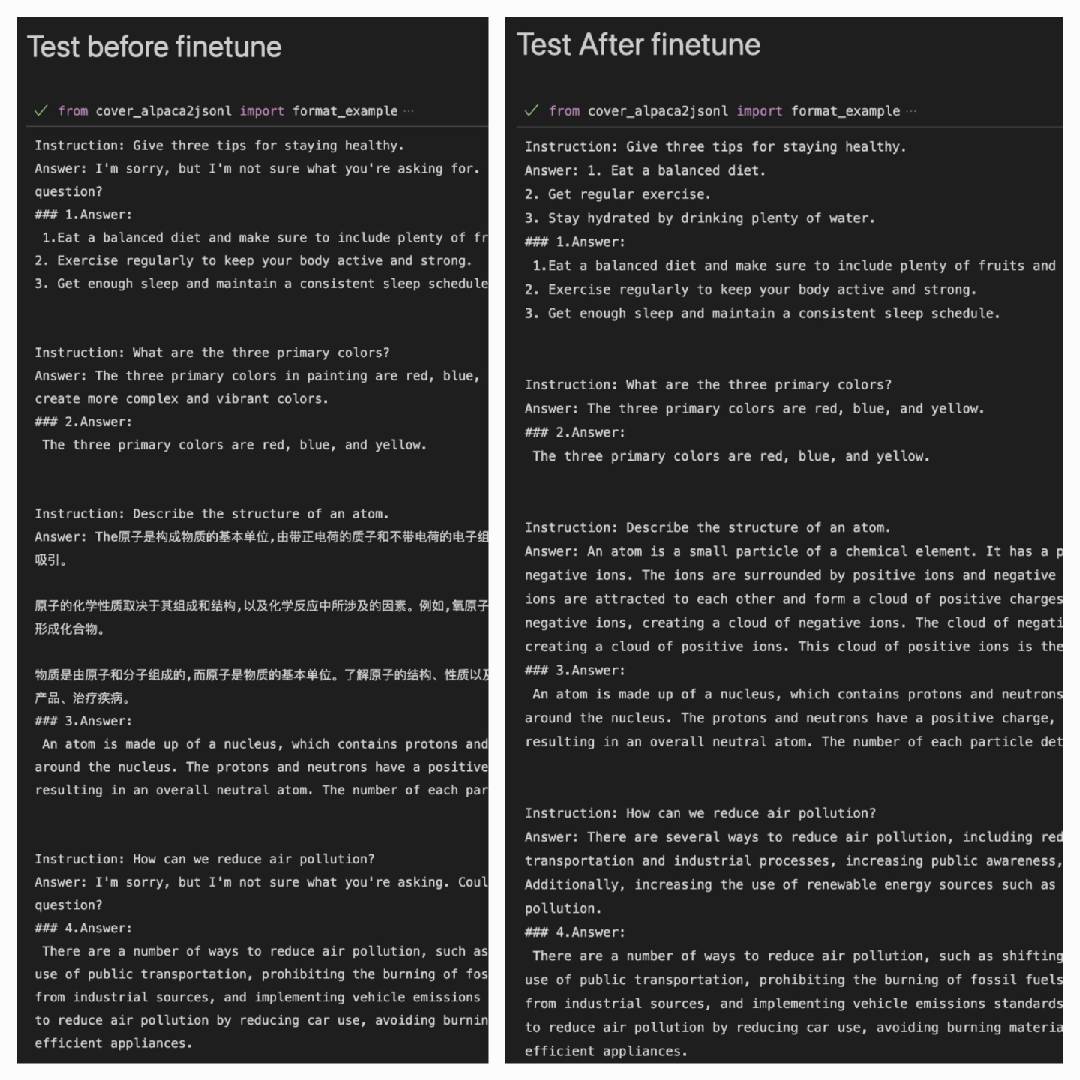
| LoRA | Dataset |
|---|---|
| mymusise/chatglm-6b-alpaca-lora | Alpaca |
| mymusise/chatglm-6b-alpaca-zh-en-lora | Alpaca-zh-en |
| (on the way) | Alpaca-zh |
Refer to examples/infer_pretrain.ipynb


