tacotron2
1.0.0
该存储库包含用于Tacotron 2的示例代码,带有多演讲者的WaveLow,情感嵌入以及用于数据预处理的脚本。
检查点和代码来自以下来源:
configs/experiments文件夹下的实验配置文件中以下一节列出了要求,以便开始训练Tacotron 2和Wavellow模型。
克隆存储库:
git clone https://github.com/ide8/tacotron2
cd tacotron2
PROJDIR= $( pwd )
export PYTHONPATH= $PROJDIR : $PYTHONPATH该存储库包含dockerfile,它扩展了Pytorch NGC容器并封装了一些依赖关系。除这些依赖性外,请确保您有以下组件:
从Docker文件构建图像:
docker build --tag taco .运行Docker容器:
docker run --shm-size=8G --runtime=nvidia -v /absolute/path/to/your/code:/app -v /absolute/path/to/your/training_data:/mnt/train -v /absolute/path/to/your/logs:/mnt/logs -v /absolute/path/to/your/raw-data:/mnt/raw-data -v /absolute/path/to/your/pretrained-checkpoint:/mnt/pretrained -detach taco sleep inf检查容器ID:
docker ps选择带有标签taco的图像的容器ID,然后登录到容器中:
docker exec -it container_id bash
文件夹tacotron2和waveglow具有用于Tacotron 2的脚本,WaveLow模型,包括:
<model_name>/model.py模型体系结构<model_name>/data_function.py数据加载功能<model_name>/loss_function.py损失功能文件夹common包含两个模型( common/layers.py ),utils( common/utils.py )和音频处理( common/audio_processing.py和common/stft.py )的公共层。
文件夹router由训练脚本使用来选择适当的模型
在根目录中:
train.py模型培训的脚本preprocess.py执行音频处理并创建培训和验证数据集inference.ipynb用于运行推理的笔记本文件夹configs包含__init__.py ,其中包含培训和数据处理所需的所有参数。文件夹configs/experiments包括所有实验。提供了waveglow.py和tacotron2.py作为浪潮和tacotron 2的示例。在训练或数据处理开始时,从您的实验中复制参数(在我们的情况下 - 从waveglow.py或tacotron2.py或从tacotron2.py )到__init__.py 。
wavs文件夹和metadata.csv file_name.wav|text 。configs/experiments/waveglow.py或configs/experiments/tacotron2.py中设置,在类PreprocessingConfig中。start_from_preprocessed标志设置为false 。 preprocess.py在PreprocessingConfig.top_db上执行修剪音频文件(在开始和结束时剪切静音),应用ffmpeg命令以进行单声道,对数据集中的所有wav进行相同的采样率和比特率。PreprocessingConfig.output_directory中使用处理后的音频文件和data.csv保存一个文件夹wavs ,并使用以下格式: path|text|speaker_name|speaker_id|emotion|text_len|duration 。process_audio为true 。具有旗帜emotion_present扬声器是错误的,被视为情绪neutral-normal 。start_from_preprocessed = False 。如果有新的原始数据出现,则只有例外。start_from_preprocessed设置为true ,脚本将加载文件data.csv (由start_from_preprocessed = False Run创建),并从data.csv中添加train.txt和val.txt 。PreprocessingConfig参数参数:cpus定义批处理生成器的核心数sr定义读写音频的样本比率emo_id_map情感名称to情感映射的词典data[{'path'}] - 是通往使用扬声器名称的文件夹的路径,并包含wavs文件夹和metadata.csv带有以下行格式: file_name.wav|text|emotion (optional)PreprocessingConfig.limit_by (适当的批次大小需要此步骤)PreprocessingConfig.text_limit和PreprocessingConfig.dur_limit中选择行。音频的下限由PreprocessingConfig.minimum_viable_dur定义PreprocessingConfig.text_limit设置为linda_jonsontrain : val = 0.95 : 0.05PreprocessingConfig.n样品n行train.txt和val.txt到PreprocessingConfig.output_directoryemotion_coefficients.json and speaker_coefficients.json具有损失平衡系数(由train.py使用)。由于两个脚本waveglow.py和tacotron2.py都包含类PreprocessingConfig ,因此可以通过运行任何一个来生成培训和验证数据集:
python preprocess.py --exp tacotron2
或者
python preprocess.py --exp waveglow
在configs/experiment/tacotron2.py中,在类Config集中:
training_files and validation_files train.txt的路径, val.txt ;tacotron_checkpoint如果存在预计的Tacotron 2的路径(我们能够恢复NVIDIA的浪潮,但是Tacotron 2代码被编辑以添加扬声器和情感,因此需要从头开始训练Tacotron 2);speaker_coefficients speaker_coefficients.json的路径;emotion_coefficients emotion_coefficients.json的路径;output_directory编写日志和检查点的路径;use_emotions指示情绪使用的标志;use_loss_coefficients标志,指示损失缩放,这是由于扬声器和情绪而言可能的数据失调;为了平衡损失,请在emotion_coefficients和speaker_coefficients中为JSON设定途径;model_name "Tacotron2" 。 python train.py --exp tacotron2
python -m multiproc train.py --exp tacotron2
在configs/experiment/waveglow.py中,在类Config集中:
training_files and validation_files train.txt的路径, val.txt ;waveglow_checkpoint从NVIDIA恢复的经过验证的WaveLow的路径。下载CheckOpoint。output_directory编写日志和检查点的路径;use_emotions false ;use_loss_coefficients false ;model_name "WaveGlow" 。 python train.py --exp waveglow
python -m multiproc train.py --exp waveglow
一旦您进行了模型开始培训,您可能希望看到一些培训的进展:
docker ps
使用标签taco选择图像的容器ID并运行:
docker exec -it container_id bash
启动张板:
tensorboard --logdir=path_to_folder_with_logs --host=0.0.0.0
损失被写入张板中:
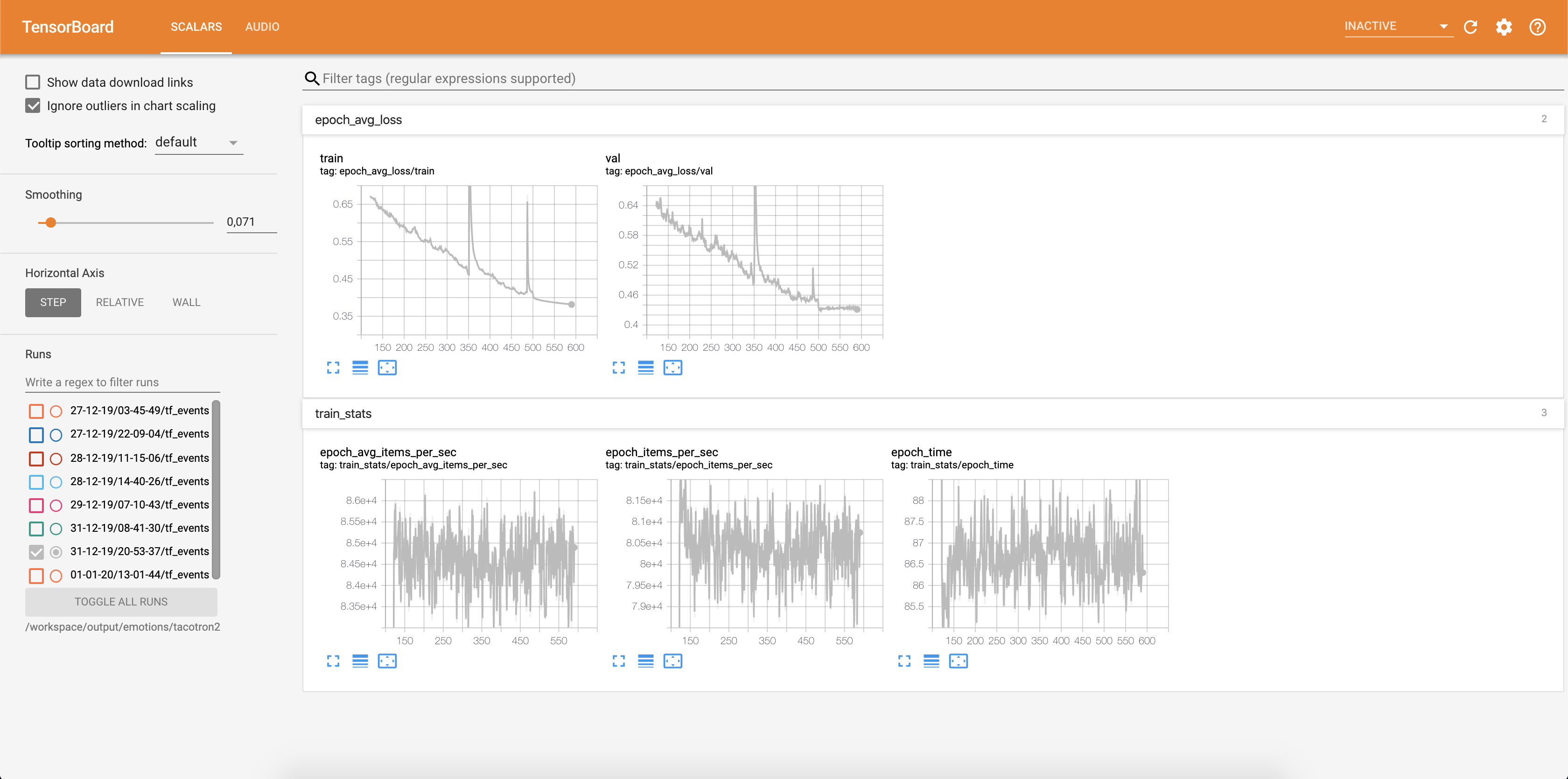
音频样本和注意对齐都可以保存到每个Config.epochs_per_checkpoint中。音频的成绩单在Config.phrases中列出
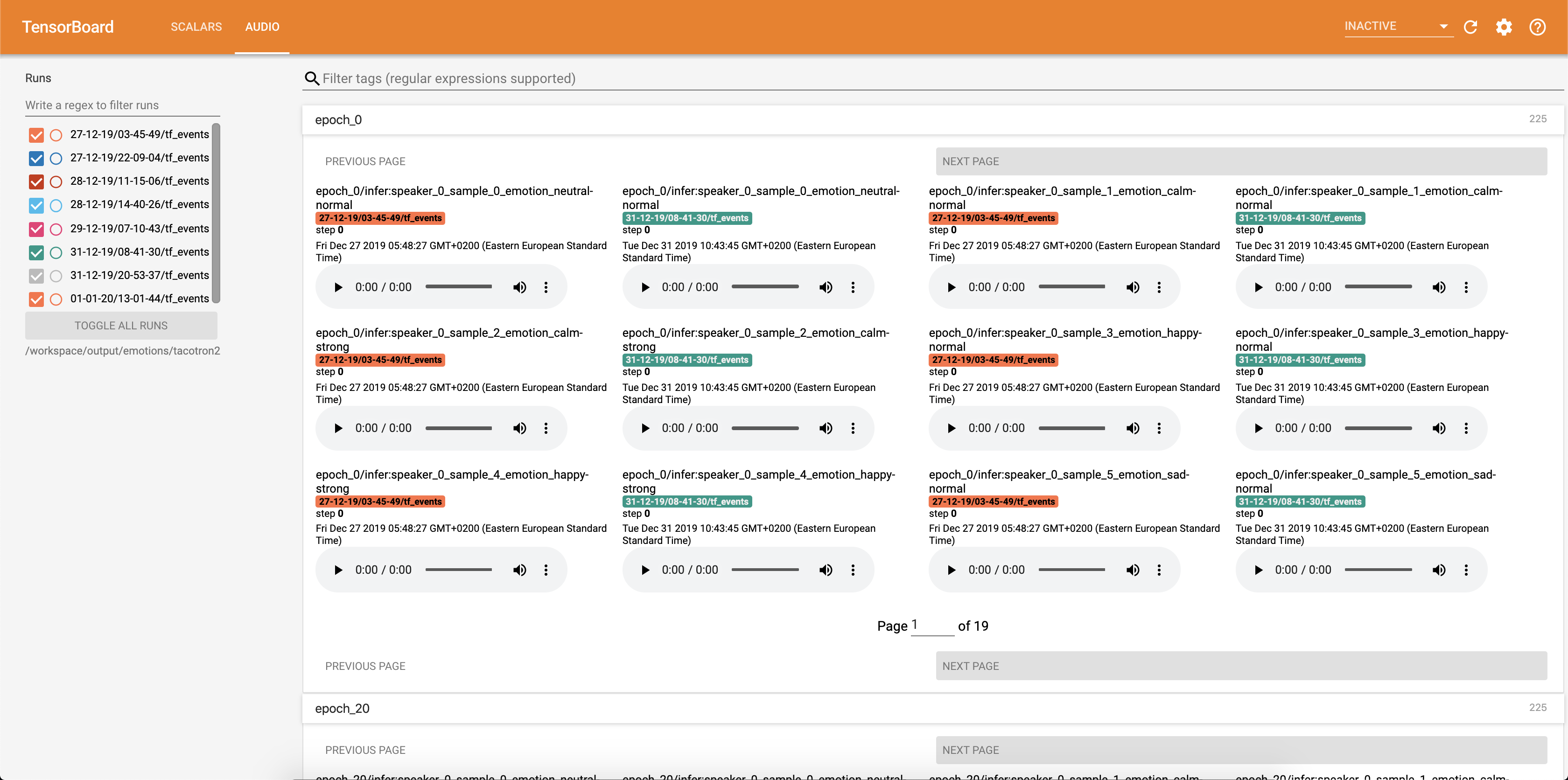
使用the the the the the inference.ipynb笔记本运行推理。
运行Jupyter笔记本:
jupyter notebook --ip 0.0.0.0 --port 6006 --no-browser --allow-root
输出:
root@04096a19c266:/app# jupyter notebook --ip 0.0.0.0 --port 6006 --no-browser --allow-root
[I 09:31:25.393 NotebookApp] JupyterLab extension loaded from /opt/conda/lib/python3.6/site-packages/jupyterlab
[I 09:31:25.393 NotebookApp] JupyterLab application directory is /opt/conda/share/jupyter/lab
[I 09:31:25.395 NotebookApp] Serving notebooks from local directory: /app
[I 09:31:25.395 NotebookApp] The Jupyter Notebook is running at:
[I 09:31:25.395 NotebookApp] http://(04096a19c266 or 127.0.0.1):6006/?token=bbd413aef225c1394be3b9de144242075e651bea937eecce
[I 09:31:25.395 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 09:31:25.398 NotebookApp]
To access the notebook, open this file in a browser:
file:///root/.local/share/jupyter/runtime/nbserver-15398-open.html
Or copy and paste one of these URLs:
http://(04096a19c266 or 127.0.0.1):6006/?token=bbd413aef225c1394be3b9de144242075e651bea937eecce
选择使用127.0.0.1的地址,然后将其放入浏览器中。在这种情况下: http://127.0.0.1:6006/?token=bbd413aef225c1394be3b9de144242075e651bea937eecce 6006/?token=bbd413aef225C1394BE3B9DE144242075E651BEA937EECCE
该脚本以文本为输入并运行Tacotron 2,然后WaveGlow推断以产生音频文件。它需要从Tacotron 2和Wavellow模型,输入文本,Speaker_ID和Emotion_id的预训练检查点。
将路径更改为预处理的TACOTRON 2的检查点,并在the the the the the the the the inference.ipynb的细胞[2]中将路径更改。
写一个要显示在the the the the the the the the the the the the the the inference.ipynb中的文本。
在本节中,我们列出了最重要的超参数及其默认值,这些值用于训练TaCotron 2和Wavellow模型。
epochs - 时期数(Tacotron 2:1501,Wavelow:1001)learning-rate - 学习率(TACOTRON 2:1E-3,WAVEGLOW:1E-4)batch-size - 批量尺寸(Tacotron 2:64,WaveLow:11)grad_clip_thresh渐变剪辑treshold(0.1)sampling-rate - 输入和输出音频Hz中的采样率(22050)filter-length - (1024)hop-length - hop长度为FFT,即连续FFT之间的样品步幅(256)win-length FFT的窗口尺寸(1024)mel-fmin Hz的最低频率(0.0)mel-fmax Hz中的最高频率(8.000)anneal-steps - 退火率的时期(500/1000/1500)anneal-factor - 通过以下情况,使用这两个参数来退火率(0.1)来改变学习率的因素(0.1 anneal-steps 。learning_rate = learning_rate * ( anneal_factor ** p) ,p = 0在第一步,每个步骤增加1个。segment-length - 由神经网络处理的输入音频的段长度(8000)。在传递输入之前,音频被填充或裁剪为segment-length 。wn_config具有仿射耦合层参数的字典。包含n_layers , n_chanels , kernel_size 。 如果您曾经想为开源而做出贡献,这是您的机会,现在是您的机会!
有关更多信息,请参见贡献文档


