tacotron2
1.0.0
يحتوي هذا المستودع على رمز عينة لـ Tacotron 2 ، WaveGlow مع Multi-Speaker ، تضمينات العاطفة مع برنامج نصي للمعالجة المسبقة للبيانات.
تنشأ نقاط التفتيش والرمز من المصادر التالية:
configs/experiments يسرد القسم التالي المتطلبات من أجل البدء في تدريب نماذج Tacotron 2 و WaveGlow.
استنساخ المستودع:
git clone https://github.com/ide8/tacotron2
cd tacotron2
PROJDIR= $( pwd )
export PYTHONPATH= $PROJDIR : $PYTHONPATHيحتوي هذا المستودع على Dockerfile الذي يمتد حاوية Pytorch NGC ويغلف بعض التبعيات. بصرف النظر عن هذه التبعيات ، تأكد من أن لديك المكونات التالية:
قم بإنشاء صورة من ملف Docker:
docker build --tag taco .تشغيل حاوية Docker:
docker run --shm-size=8G --runtime=nvidia -v /absolute/path/to/your/code:/app -v /absolute/path/to/your/training_data:/mnt/train -v /absolute/path/to/your/logs:/mnt/logs -v /absolute/path/to/your/raw-data:/mnt/raw-data -v /absolute/path/to/your/pretrained-checkpoint:/mnt/pretrained -detach taco sleep infتحقق من معرف الحاوية:
docker ps حدد معرف الحاوية من الصورة مع TAG taco وتسجيل الدخول إلى حاوية مع:
docker exec -it container_id bash
المجلدات tacotron2 و waveglow لها نصوص ل Tacotron 2 ، ونماذج WaveGlow وتتألف من:
<model_name>/model.py - بنية النموذج<model_name>/data_function.py - وظائف تحميل البيانات<model_name>/loss_function.py - وظيفة الخسارة يحتوي المجلد common على طبقات مشتركة لكلا النموذجين ( common/layers.py ) ، و utils ( common/utils.py ) ومعالجة الصوت ( common/audio_processing.py و common/stft.py ).
يتم استخدام router المجلد عن طريق تدريب البرنامج النصي لتحديد نموذج مناسب
في دليل الجذر:
train.py - البرنامج النصي للتدريب على النماذجpreprocess.py - يؤدي معالجة الصوت وإنشاء مجموعات بيانات التدريب والتحقق من الصحةinference.ipynb . يحتوي المجلد configs __init__.py مع جميع المعلمات اللازمة للتدريب ومعالجة البيانات. يتكون configs/experiments المجلد من جميع التجارب. يتم توفير waveglow.py و tacotron2.py كأمثلة لـ WaveGlow و Tacotron 2. عند بدء التدريب أو معالجة البيانات ، يتم نسخ المعلمات من تجربتك (في حالتنا - من waveglow.py أو من tacotron2.py ) إلى __init__.py ، والتي يتم استخدامها من قبل النظام.
wavs وملف metadata.csv مع تنسيق السطر التالي: file_name.wav|text .configs/experiments/waveglow.py أو في configs/experiments/tacotron2.py ، في الفئة PreprocessingConfig .start_from_preprocessed إلى FALSE . preprocess.py يؤدي تقليص ملفات الصوت حتى PreprocessingConfig.top_db .wavs مع ملفات صوتية معالجة وملف data.csv في PreprocessingConfig.output_directory مع التنسيق التالي: path|text|speaker_name|speaker_id|emotion|text_len|duration .process_audio Flag_Audio صحيحة . المتحدثون مع emotion_present العاطفي هو خاطئ ، يتم التعامل معها كما هو الحال مع العاطفة neutral-normal .start_from_preprocessed = False بمجرد الانتهاء من تشغيل البرنامج النصي المسبق للمعالجة. استثناء فقط في حالة البيانات الخام الجديدة يأتي.val.txt تعيين start_from_preprocessed على true start_from_preprocessed = False train.txt البرنامج النصي بتحميل data.csv الملف data.csvPreprocessingConfig :cpus - تحدد عدد النوى لمولد الدُفعاتsr - يحدد نسبة العينة لقراءة وكتابة الصوتemo_id_map - قاموس اسم العاطفة إلى رسم الخرائط العاطفيةdata[{'path'}] - مسار إلى مجلد اسمه اسم المتحدث ويحتوي على مجلد wavs و metadata.csv بتنسيق السطر التالي: file_name.wav|text|emotion (optional)PreprocessingConfig.limit_by .PreprocessingConfig.text_limit PreprocessingConfig.dur_limit . يتم تعريف الحد الأدنى للصوت بواسطة PreprocessingConfig.minimum_viable_durPreprocessingConfig.text_limit إلى linda_jonsontrain : val = 0.95 : 0.05PreprocessingConfig.n - عينات n صفوفtrain.txt و val.txt إلى PreprocessingConfig.output_directoryemotion_coefficients.json و speaker_coefficients.json مع معاملات موازنة الخسارة (المستخدمة بواسطة train.py ). نظرًا لأن كلا البرامج النصية waveglow.py و tacotron2.py تحتويان على الفئة PreprocessingConfig ، يمكن إنتاج مجموعة بيانات التدريب والتحقق من خلال تشغيل أي منها:
python preprocess.py --exp tacotron2
أو
python preprocess.py --exp waveglow
في configs/experiment/tacotron2.py ، في مجموعة Config الفئة:
training_files and validation_files - مسارات إلى train.txt ، val.txt ؛tacotron_checkpoint - مسار إلى Tacotron 2 pretrained إذا كان موجودًا (تمكنا من استعادة Waveglow من Nvidia ، ولكن تم تحرير رمز Tacotron 2 لإضافة مكبرات الصوت والعواطف ، لذلك يجب تدريب Tacotron 2 من الصفر) ؛speaker_coefficients - path to speaker_coefficients.json ؛emotion_coefficients - طريق إلى emotion_coefficients.json ؛output_directory - مسار لكتابة سجلات ونقاط التفتيش ؛use_emotions - العلم الذي يشير إلى استخدام العواطف ؛use_loss_coefficients - علامة تشير إلى تحجيم الخسارة بسبب عدم توازن البيانات المحتمل من حيث كل من السماعات والعواطف ؛ لموازنة الخسارة ، قم بتعيين مسارات على Jsons مع معاملات في emotion_coefficients و speaker_coefficients ؛model_name - "Tacotron2" . python train.py --exp tacotron2
python -m multiproc train.py --exp tacotron2
في configs/experiment/waveglow.py ، في مجموعة Config الفئة:
training_files and validation_files - مسارات إلى train.txt ، val.txt ؛waveglow_checkpoint - مسار إلى WaveGlow المسبق ، تم ترميمه من Nvidia. قم بتنزيل checkopoint.output_directory - مسار لكتابة سجلات ونقاط التفتيش ؛use_emotions - false ؛use_loss_coefficients - false ؛model_name - "WaveGlow" . python train.py --exp waveglow
python -m multiproc train.py --exp waveglow
بمجرد أن تجعل نموذجك يبدأ التدريب ، قد ترغب في رؤية بعض التقدم في التدريب:
docker ps
حدد معرف حاوية الصورة مع TAG taco وتشغيله:
docker exec -it container_id bash
ابدأ Tensorboard:
tensorboard --logdir=path_to_folder_with_logs --host=0.0.0.0
تتم كتابة الخسارة في Tensorboard:
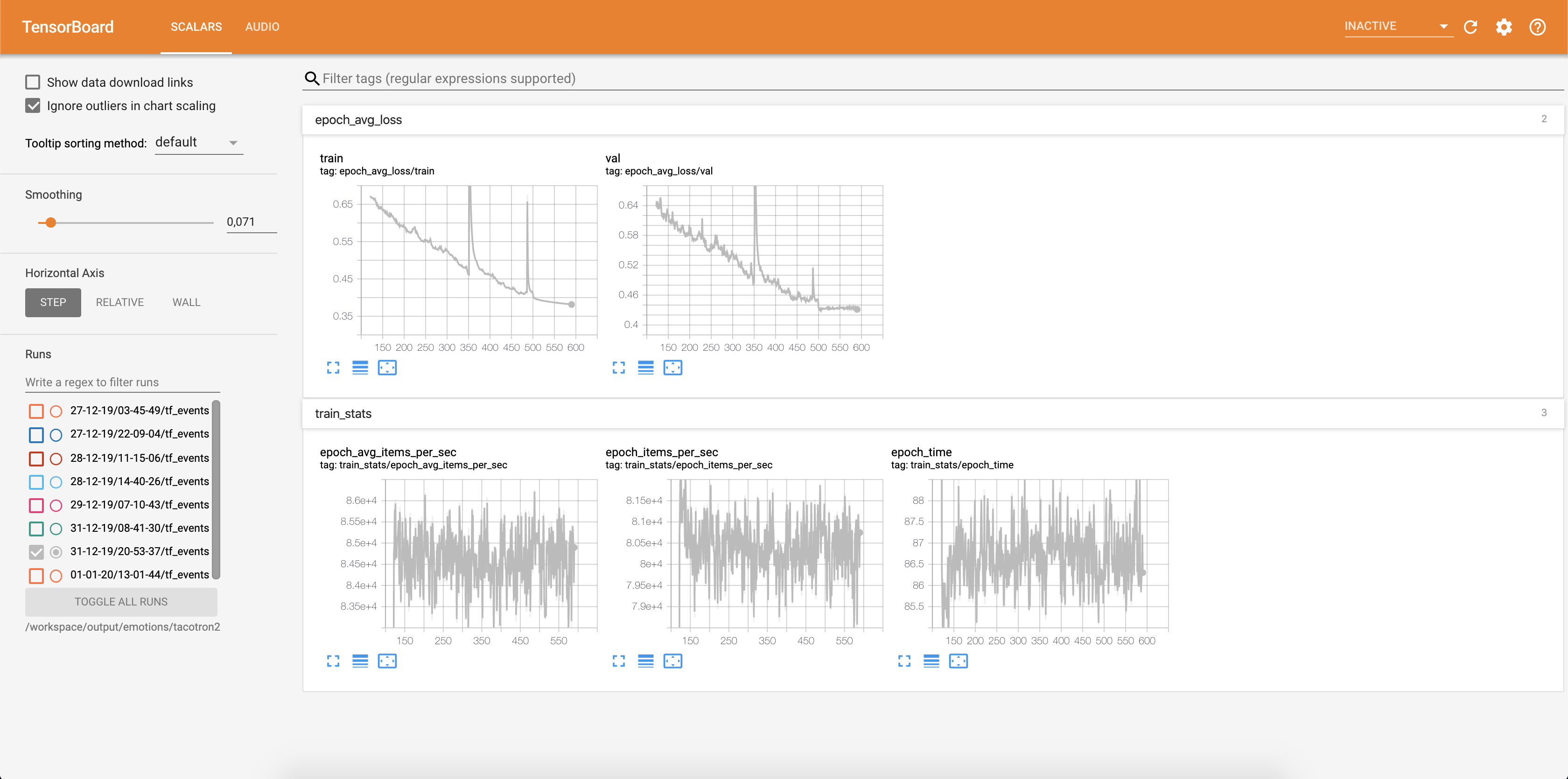
يتم حفظ عينات الصوت مع محاذاة الانتباه في TensorBaord كل Config.epochs_per_checkpoint . يتم سرد النصوص لـ Audios في Config.phrases
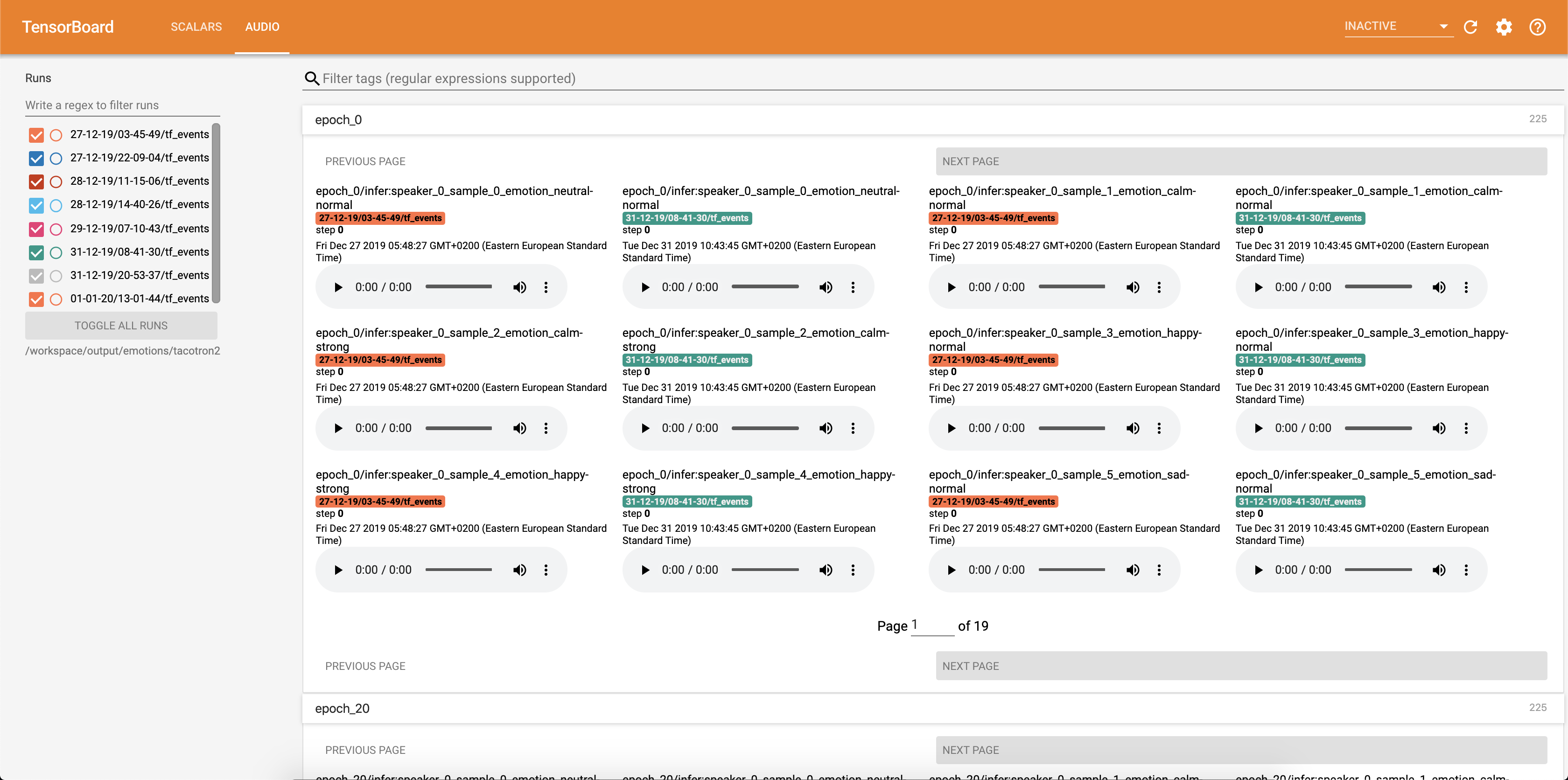
تشغيل الاستدلال مع دفتر inference.ipynb .
Run Jupyter Notebook:
jupyter notebook --ip 0.0.0.0 --port 6006 --no-browser --allow-root
الإخراج:
root@04096a19c266:/app# jupyter notebook --ip 0.0.0.0 --port 6006 --no-browser --allow-root
[I 09:31:25.393 NotebookApp] JupyterLab extension loaded from /opt/conda/lib/python3.6/site-packages/jupyterlab
[I 09:31:25.393 NotebookApp] JupyterLab application directory is /opt/conda/share/jupyter/lab
[I 09:31:25.395 NotebookApp] Serving notebooks from local directory: /app
[I 09:31:25.395 NotebookApp] The Jupyter Notebook is running at:
[I 09:31:25.395 NotebookApp] http://(04096a19c266 or 127.0.0.1):6006/?token=bbd413aef225c1394be3b9de144242075e651bea937eecce
[I 09:31:25.395 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 09:31:25.398 NotebookApp]
To access the notebook, open this file in a browser:
file:///root/.local/share/jupyter/runtime/nbserver-15398-open.html
Or copy and paste one of these URLs:
http://(04096a19c266 or 127.0.0.1):6006/?token=bbd413aef225c1394be3b9de144242075e651bea937eecce
حدد Adress مع 127.0.0.1 ووضعه في المتصفح. في هذه الحالة: http://127.0.0.1:6006/?token=bbd413aef225c1394be3b9de144242075e651bea937eecce
يأخذ هذا البرنامج النصي نصًا كمدخلات ويقوم بتشغيل Tacotron 2 ثم استنتاج WaveGlow لإنتاج ملف صوتي. إنه يتطلب نقاط تفتيش مدربة مسبقًا من نماذج Tacotron 2 ونماذج WaveGlow ونص الإدخال و Skeper_id و Emotion_id.
تغيير المسارات إلى نقاط التفتيش من tacotron 2 و waveglow في الخلية [2] من inference.ipynb .
اكتب نصًا ليتم عرضه في الخلية [7] من inference.ipynb .
في هذا القسم ، ندرج أهم أجهزة HyperParameters ، إلى جانب قيمها الافتراضية المستخدمة لتدريب نماذج Tacotron 2 و WaveGlow.
epochs - عدد الحقبة (Tacotron 2: 1501 ، WaveGlow: 1001)learning-rate -معدل التعلم (Tacotron 2: 1E-3 ، WaveGlow: 1E-4)batch-size - حجم الدُفعة (Tacotron 2: 64 ، WaveGlow: 11)grad_clip_thresh - treshold لقطات التدرج (0.1)sampling-rate - معدل أخذ العينات في هرتز من الصوت والمخرجات (22050)filter-length - (1024)hop-length - طول قفزة لـ FFT ، أي خطوة عينة بين FFTS متتالية (256)win-length - حجم النافذة لـ FFT (1024)mel-fmin - أدنى تردد في هرتز (0.0)mel-fmax - أعلى تردد في HZ (8.000)anneal-steps - عصر لتصل إلى معدل التعلم (500/1000/ 1500)anneal-factor -العامل الذي يمكن من خلاله تلبيس معدل التعلم (0.1) يتم استخدام هاتين المعلمتين لتغيير معدل التعلم في النقاط المحددة في anneal-steps وفقًا لما يلي:learning_rate = learning_rate * ( anneal_factor ** p) ،p = 0 في الخطوة الأولى والزيادة بمقدار 1 كل خطوة.segment-length - طول قطاع الصوت الإدخال المعالج بواسطة الشبكة العصبية (8000). قبل الانتقال إلى الإدخال ، يكون الصوت مبطنًا أو محصوراً إلى segment-length .wn_config - قاموس مع معلمات طبقات اقتران AFFINE. يحتوي على n_layers ، n_chanels ، kernel_size . إذا كنت ترغب في المساهمة في مفتوح المصدر ، وسبب رائع ، فإن فرصتك الآن!
انظر المستندات المساهمة لمزيد من المعلومات


