tacotron2
1.0.0
이 저장소에는 Tacotron 2의 샘플 코드, 다중 스피커가있는 Waveglow, Emotion Embedding과 데이터 전처리 스크립트가 포함되어 있습니다.
검문소 및 코드는 다음 소스에서 비롯됩니다.
configs/experiments 폴더 아래에서 실험 구성 파일로 이동 다음 섹션에는 타코트론 2 및 웨이브 글로우 모델을 훈련하기위한 요구 사항이 나와 있습니다.
저장소 복제 :
git clone https://github.com/ide8/tacotron2
cd tacotron2
PROJDIR= $( pwd )
export PYTHONPATH= $PROJDIR : $PYTHONPATH이 저장소에는 Pytorch NGC 컨테이너를 확장하고 일부 종속성을 캡슐화하는 dockerfile이 포함되어 있습니다. 이러한 종속성 외에도 다음 구성 요소가 있는지 확인하십시오.
Docker 파일에서 이미지 구축 :
docker build --tag taco .도커 컨테이너 실행 :
docker run --shm-size=8G --runtime=nvidia -v /absolute/path/to/your/code:/app -v /absolute/path/to/your/training_data:/mnt/train -v /absolute/path/to/your/logs:/mnt/logs -v /absolute/path/to/your/raw-data:/mnt/raw-data -v /absolute/path/to/your/pretrained-checkpoint:/mnt/pretrained -detach taco sleep inf컨테이너 ID 확인 :
docker ps 태그 taco 로 이미지의 컨테이너 ID를 선택하고 다음과 같이 컨테이너에 로그인하십시오.
docker exec -it container_id bash
폴더 tacotron2 및 waveglow Tacotron 2, WaveGlow 모델 용 스크립트가 있으며 다음으로 구성됩니다.
<model_name>/model.py 모델 아키텍처<model_name>/data_function.py 데이터 로딩 함수<model_name>/loss_function.py 손실 함수 폴더 common 에는 두 모델 ( common/layers.py ), utils ( common/utils.py ) 및 오디오 처리 ( common/audio_processing.py 및 common/stft.py )에 대한 공통 계층이 포함됩니다.
폴더 router 교육 스크립트에서 적절한 모델을 선택하는 데 사용됩니다.
루트 디렉토리에서 :
train.py 모델 교육을위한 스크립트preprocess.py 오디오 처리를 수행하고 교육 및 검증 데이터 세트를 만듭니다.inference.ipynb 실행을위한 노트북 폴더 configs 에는 교육 및 데이터 처리에 필요한 모든 매개 변수와 함께 __init__.py 포함됩니다. 폴더 configs/experiments 모든 실험으로 구성됩니다. waveglow.py 및 tacotron2.py WaveGlow 및 Tacotron 2의 예로 제공됩니다. 교육 또는 데이터 처리 시작시 매개 변수는 실험에서 복사됩니다 (우리의 경우 waveglow.py 또는 tacotron2.py 에서 __init__.py 에서)에서 시스템에서 사용합니다.
file_name.wav|text 의 wavs 폴더 및 metadata.csv 파일을 포함하는 스피커 이름이있는 폴더가 있어야합니다.configs/experiments/waveglow.py 또는 configs/experiments/tacotron2.py , 클래스 PreprocessingConfig 에서 설정해야합니다.start_from_preprocessed 플래그를 False 로 설정하십시오. preprocess.py PreprocessingConfig.top_db 까지 오디오 파일을 트리밍하는 것을 수행하고 (시작과 끝의 침묵을 자르고) mono에 ffmpeg 명령을 적용하고 DataSet의 모든 WAV에 대해 동일한 샘플링 속도와 비트 속도를 작성합니다.PreprocessingConfig.output_directory 에서 처리 된 오디오 파일 및 data.csv 파일이 포함 된 폴더 wavs 저장합니다. path|text|speaker_name|speaker_id|emotion|text_len|duration .process_audio True 입니다. 깃발 emotion_present 가진 스피커는 거짓 이며 감정 neutral-normal 로 취급됩니다.start_from_preprocessed = False 필요하지 않습니다. 새로운 원시 데이터의 경우에만 예외가 발생합니다.start_from_preprocessed start_from_preprocessed = False true val.txt 설정되면 스크립트 train.txt 파일 data.csv data.csv 합니다.PreprocessingConfig 매개 변수 :cpus 배치 생성기의 코어 수를 정의합니다sr 오디오 읽기 및 쓰기에 대한 샘플 비율 정의emo_id_map 감정 이름에 감정 _ID 매핑에 대한 사전data[{'path'}] - 스피커 이름이 이름이 지정된 폴더의 경로는 다음 줄 형식으로 다음 줄 형식으로 wavs 폴더 및 metadata.csv 포함하는 폴더로 file_name.wav|text|emotion (optional) 경로입니다.PreprocessingConfig.limit_by 의 텍스트 길이가 적거나 동일합니다 (이 단계는 적절한 배치 크기에 필요합니다).PreprocessingConfig.text_limit 및 PreprocessingConfig.dur_limit 내에서 행을 선택합니다. 오디오의 하한은 PreprocessingConfig.minimum_viable_dur 로 정의됩니다PreprocessingConfig.text_limit linda_jonson 으로 설정하십시오.train : val = 0.95 : 0.05PreprocessingConfig.n 보다 큰 경우 n 행train.txt 및 val.txt PreprocessingConfig.output_directory 에 저장합니다train.py 에서 사용)에 대한 계수가있는 emotion_coefficients.json 및 speaker_coefficients.json 저장합니다. 두 스크립트 waveglow.py 및 tacotron2.py 는 클래스 PreprocessingConfig 포함하기 때문에 교육 및 검증 데이터 세트는 다음 중 하나를 실행하여 생성 할 수 있습니다.
python preprocess.py --exp tacotron2
또는
python preprocess.py --exp waveglow
configs/experiment/tacotron2.py 에서 클래스 Config 세트에서 :
training_files 및 validation_files train.txt , val.txt 로가는 경로;tacotron_checkpoint -PETHERAINED TACOTRON 2 로의 경로가 존재하는 경우 (우리는 NVIDIA에서 WaveGlow를 복원 할 수 있었지만 Tacotron 2 코드는 스피커와 감정을 추가하기 위해 편집되었으므로 Tacotron 2를 처음부터 훈련해야합니다);speaker_coefficients speaker_coefficients.json 으로가는 경로;emotion_coefficients _coefficients- emotion_coefficients.json 의 경로;output_directory 로그 및 체크 포인트를 작성하는 경로;use_emotions 감정 사용을 나타내는 플래그;use_loss_coefficients 스피커와 감정 모두에서 가능한 데이터 균형으로 인한 손실 스케일링을 나타내는 플래그; 손실 균형을 유지하려면 emotion_coefficients 및 speaker_coefficients 의 계수로 경로를 JSON으로 설정하십시오.model_name "Tacotron2" . python train.py --exp tacotron2
python -m multiproc train.py --exp tacotron2
configs/experiment/waveglow.py 에서 클래스 Config 세트에서 :
training_files 및 validation_files train.txt , val.txt 로가는 경로;waveglow_checkpoint NVIDIA에서 복원 된 사전 취사 WaveGlow로가는 경로. CheckoPoint를 다운로드하십시오.output_directory 로그 및 체크 포인트를 작성하는 경로;use_emotions -false ;use_loss_coefficients -false ;model_name "WaveGlow" . python train.py --exp waveglow
python -m multiproc train.py --exp waveglow
모델 교육을 시작한 후에는 교육의 진행 상황을보고 싶을 수도 있습니다.
docker ps
태그 taco 로 이미지의 컨테이너 ID를 선택하고 실행하십시오.
docker exec -it container_id bash
Tensorboard 시작 :
tensorboard --logdir=path_to_folder_with_logs --host=0.0.0.0
손실은 Tensorboard에 기록되고 있습니다.
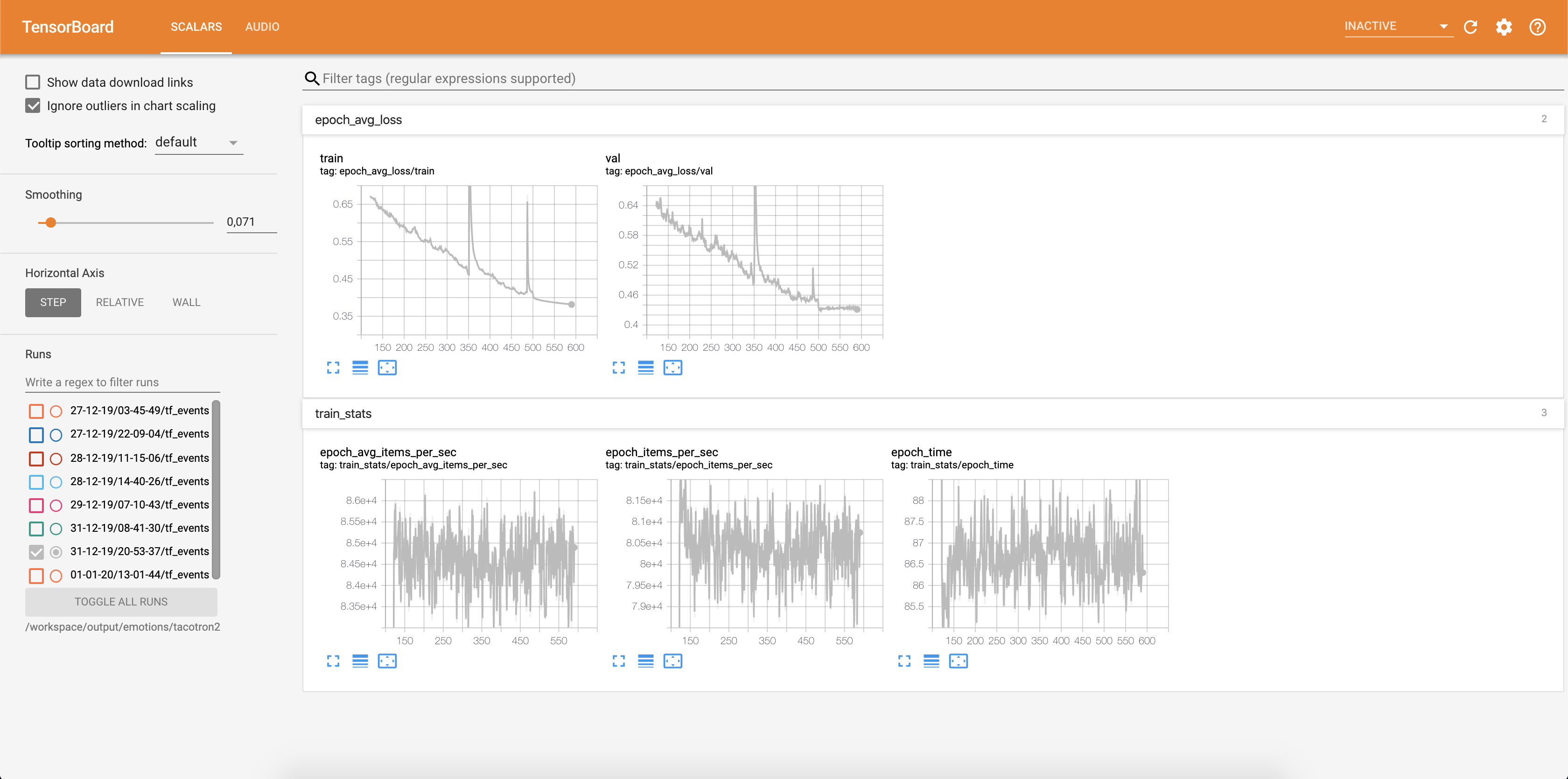
주의 정렬과 함께 오디오 샘플은 각 Config.epochs_per_checkpoint 각 텐서 바오드로 저장됩니다. 오디오의 전사는 Config.phrases 에 나열되어 있습니다
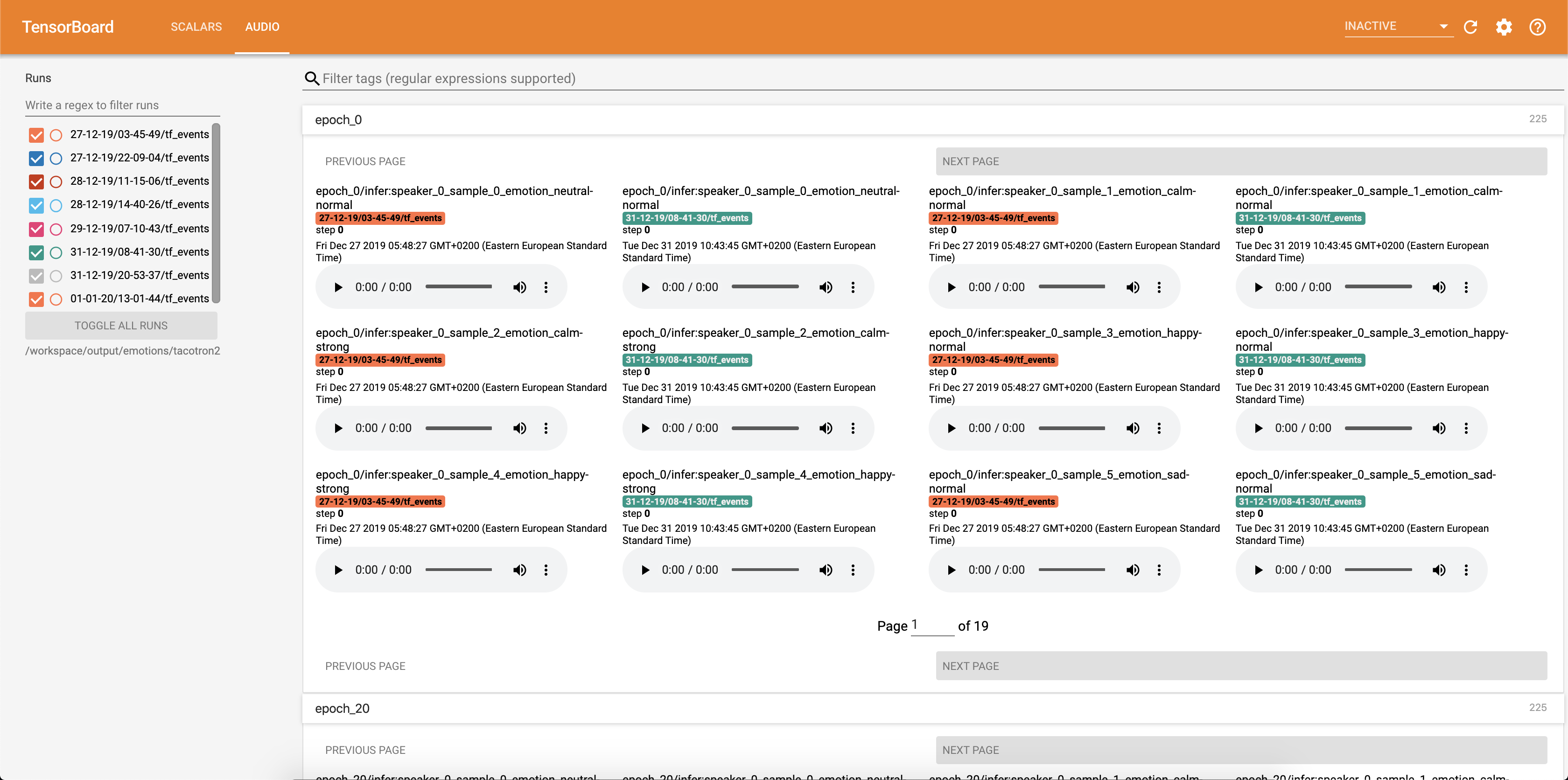
추론을 실행합니다 inference.ipynb 노트북.
Jupyter Notebook 실행 :
jupyter notebook --ip 0.0.0.0 --port 6006 --no-browser --allow-root
산출:
root@04096a19c266:/app# jupyter notebook --ip 0.0.0.0 --port 6006 --no-browser --allow-root
[I 09:31:25.393 NotebookApp] JupyterLab extension loaded from /opt/conda/lib/python3.6/site-packages/jupyterlab
[I 09:31:25.393 NotebookApp] JupyterLab application directory is /opt/conda/share/jupyter/lab
[I 09:31:25.395 NotebookApp] Serving notebooks from local directory: /app
[I 09:31:25.395 NotebookApp] The Jupyter Notebook is running at:
[I 09:31:25.395 NotebookApp] http://(04096a19c266 or 127.0.0.1):6006/?token=bbd413aef225c1394be3b9de144242075e651bea937eecce
[I 09:31:25.395 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 09:31:25.398 NotebookApp]
To access the notebook, open this file in a browser:
file:///root/.local/share/jupyter/runtime/nbserver-15398-open.html
Or copy and paste one of these URLs:
http://(04096a19c266 or 127.0.0.1):6006/?token=bbd413aef225c1394be3b9de144242075e651bea937eecce
127.0.0.1로 Adress를 선택하고 브라우저에 넣으십시오. 이 경우 : http://127.0.0.1:6006/?token=bbd413aef225c1394be3b9de144242075e651bea937eecce
이 스크립트는 텍스트를 입력으로 취하고 Tacotron 2를 실행 한 다음 WaveGlow 추론을 실행하여 오디오 파일을 생성합니다. Tacotron 2 및 WaveGlow 모델, 입력 텍스트, speeger_id 및 extent_id에서 미리 훈련 된 체크 포인트가 필요합니다.
inference.ipynb 의 세포 [2]에서 사전 재해 타코트론 2 및 웨이브 글로우의 체크 포인트로의 경로를 변경합니다.
inference.ipynb 의 셀 [7]에 표시 할 텍스트를 작성하십시오.
이 섹션에서는 Tacotron 2 및 Waveglow 모델을 훈련시키는 데 사용되는 기본값과 함께 가장 중요한 하이퍼 파라미터를 나열합니다.
epochs - 에포크 수 (Tacotron 2 : 1501, Waveglow : 1001)learning-rate -학습 속도 (Tacotron 2 : 1E-3, Waveglow : 1E-4)batch-size - 배치 크기 (타코트론 2 : 64, 웨이브 글로우 : 11)grad_clip_thresh 그라디언트 클리핑 트레 시드 (0.1)sampling-rate - 입력 및 출력 오디오 Hz의 샘플링 속도 (22050)filter-length - (1024)hop-length - 홉 길이, 즉 연속 FFT 사이의 샘플 보폭 (256)win-length - FFT의 창 크기 (1024)mel-fmin HZ에서 가장 낮은 주파수 (0.0)mel-fmax HZ에서 가장 높은 주파수 (8.000)anneal-steps - 학습 속도를 어닐링하는 에포크 (500/ 1000/ 1500)anneal-factor -학습 속도를 어닐링하는 요인 (0.1)이 두 매개 변수는 다음에 따라 anneal-steps 로 정의 된 지점에서 학습 속도를 변경하는 데 사용됩니다.learning_rate = learning_rate * ( anneal_factor ** p) ,p = 0 , 각 단계마다 1 증가합니다.segment-length - 신경망 (8000)에 의해 처리 된 입력 오디오의 세그먼트 길이. 입력으로 전달하기 전에 오디오는 패딩되거나 segment-length 로 자릅니다.wn_config 아핀 커플 링 층의 매개 변수가있는 사전. n_layers , n_chanels , kernel_size 포함되어 있습니다. 오픈 소스와 큰 원인에 기여하고 싶었다면 이제는 기회입니다!
자세한 내용은 기고 문서를 참조하십시오


