tacotron2
1.0.0
Ce référentiel contient un exemple de code pour le tacotron 2, l'éclat d'onde avec des incorporations d'émotion multi-parole avec un script pour le prétraitement des données.
Les points de contrôle et le code proviennent des sources suivantes:
configs/experiments La section suivante répertorie les exigences afin de commencer à former les modèles Tacotron 2 et Wave Glow.
Clone le référentiel:
git clone https://github.com/ide8/tacotron2
cd tacotron2
PROJDIR= $( pwd )
export PYTHONPATH= $PROJDIR : $PYTHONPATHCe référentiel contient dockerfile qui étend le conteneur NGC Pytorch et résume certaines dépendances. Outre ces dépendances, assurez-vous que vous disposez des composants suivants:
Créez une image à partir du fichier docker:
docker build --tag taco .Exécutez le conteneur Docker:
docker run --shm-size=8G --runtime=nvidia -v /absolute/path/to/your/code:/app -v /absolute/path/to/your/training_data:/mnt/train -v /absolute/path/to/your/logs:/mnt/logs -v /absolute/path/to/your/raw-data:/mnt/raw-data -v /absolute/path/to/your/pretrained-checkpoint:/mnt/pretrained -detach taco sleep infVérifiez l'ID du conteneur:
docker ps Sélectionnez l'ID de conteneur de l'image avec TAG taco et connectez-vous au conteneur avec:
docker exec -it container_id bash
Les dossiers tacotron2 et waveglow ont des scripts pour le tacotron 2, les modèles d'éclairage d'onde et consistent à:
<model_name>/model.py - Architecture du modèle<model_name>/data_function.py - fonctions de chargement de données<model_name>/loss_function.py - Fonction de perte Le dossier common contient des couches communes pour les deux modèles ( common/layers.py ), les utils ( common/utils.py ) et le traitement audio ( common/audio_processing.py et common/stft.py ).
router de dossier est utilisé par le script d'entraînement pour sélectionner un modèle approprié
Dans le répertoire racine:
train.py - Script pour la formation du modèlepreprocess.py - effectue un traitement audio et crée des ensembles de données de formation et de validationinference.ipynb - cahier pour l'exécution de l'inférence configs de dossier contient __init__.py avec tous les paramètres nécessaires à la formation et au traitement des données. configs/experiments du dossier se compose de toutes les expériences. waveglow.py et tacotron2.py sont fournis comme exemples pour la lueur d'onde et le tacotron 2. Sur le démarrage de la formation ou du traitement des données, les paramètres sont copiés à partir de votre expérience (dans notre cas - de waveglow.py ou de tacotron2.py ) à __init__.py , à partir de laquelle ils sont utilisés par le système.
wavs et un fichier metadata.csv avec le format de ligne suivant: file_name.wav|text .configs/experiments/waveglow.py ou dans configs/experiments/tacotron2.py , dans la classe PreprocessingConfig .start_from_preprocessed Flag en false . preprocess.py effectue la coupe des fichiers audio jusqu'à PreprocessingConfig.top_db (coupe le silence au début et à la fin), applique la commande ffmpeg pour mono, faites le même taux d'échantillonnage et la même fréquence binaire pour toutes les vagues dans l'ensemble de données.wavs avec des fichiers audio traités et un fichier data.csv dans PreprocessingConfig.output_directory avec le format suivant: path|text|speaker_name|speaker_id|emotion|text_len|duration .process_audio est vraie . Les locuteurs avec Flag emotion_present sont faux , sont traités comme avec l'émotion neutral-normal .start_from_preprocessed = False une fois que vous avez terminé l'exécution du script de pré-traitement. Seule une exception en cas de nouvelles données brutes arrive.start_from_preprocessed est défini sur true , le script charge de fichier data.csv (créé par start_from_preprocessed = False run), et forms train.txt et val.txt out à partir de data.csv .PreprocessingConfig PRÉPROSSIONS:cpus - Définit le nombre de cœurs pour le générateur par lotssr - définit le rapport d'échantillon pour la lecture et l'écriture de l'audioemo_id_map - Dictionnaire pour le nom d'émotion à émotion_id mappagedata[{'path'}] - est le chemin du dossier nommé avec le nom du haut-parleur et contenant un dossier wavs et metadata.csv avec le format de ligne suivant: file_name.wav|text|emotion (optional)PreprocessingConfig.limit_by (cette étape est nécessaire pour une taille de lot appropriée)PreprocessingConfig.text_limit et PreprocessingConfig.dur_limit . La limite inférieure pour l'audio est définie par PreprocessingConfig.minimum_viable_durPreprocessingConfig.text_limit à linda_jonsontrain : val = 0.95 : 0.05PreprocessingConfig.n - les échantillons n lignestrain.txt et val.txt pour PreprocessingConfig.output_directoryemotion_coefficients.json et speaker_coefficients.json avec des coefficients pour l'équilibrage des pertes (utilisé par train.py ). Étant donné que les scripts waveglow.py et tacotron2.py contiennent le PreprocessingConfig de classe, l'ensemble de données de formation et de validation peut être produit en exécutant l'un d'eux:
python preprocess.py --exp tacotron2
ou
python preprocess.py --exp waveglow
Dans configs/experiment/tacotron2.py , dans le jeu Config de classe:
training_files et validation_files - Paths to train.txt , val.txt ;tacotron_checkpoint - Chemin vers Tacotron 2 pré-entraîné s'il existe (nous avons pu restaurer l'éclat d'onde de NVIDIA, mais le code Tacotron 2 a été modifié pour ajouter des haut-parleurs et des émotions, donc le tacotron 2 doit être formé à partir de zéro);speaker_coefficients - Chemin vers speaker_coefficients.json ;emotion_coefficients - Path to emotion_coefficients.json ;output_directory - chemin pour la rédaction de journaux et de points de contrôle;use_emotions - Flag indiquant l'utilisation des émotions;use_loss_coefficients - Flag indiquant la mise à l'échelle des pertes due à une éventuelle déchargement des données en termes de locuteurs et d'émotions; Pour équilibrer la perte, définissez des chemins sur JSON avec des coefficients dans emotion_coefficients et speaker_coefficients ;model_name - "Tacotron2" . python train.py --exp tacotron2
python -m multiproc train.py --exp tacotron2
Dans configs/experiment/waveglow.py , dans le jeu Config de classe:
training_files et validation_files - Paths to train.txt , val.txt ;waveglow_checkpoint - Chemin vers une lueur d'onde pré-entraînée, restaurée à partir de Nvidia. Télécharger CheckoPoint.output_directory - chemin pour la rédaction de journaux et de points de contrôle;use_emotions - false ;use_loss_coefficients - false ;model_name - "WaveGlow" . python train.py --exp waveglow
python -m multiproc train.py --exp waveglow
Une fois que vous avez fait commencer votre modèle, vous voudrez peut-être voir des progrès de la formation:
docker ps
Sélectionnez l'ID de conteneur de l'image avec TAG taco et EXAUCHE:
docker exec -it container_id bash
Démarrer Tensorboard:
tensorboard --logdir=path_to_folder_with_logs --host=0.0.0.0
La perte est écrite dans Tensorboard:
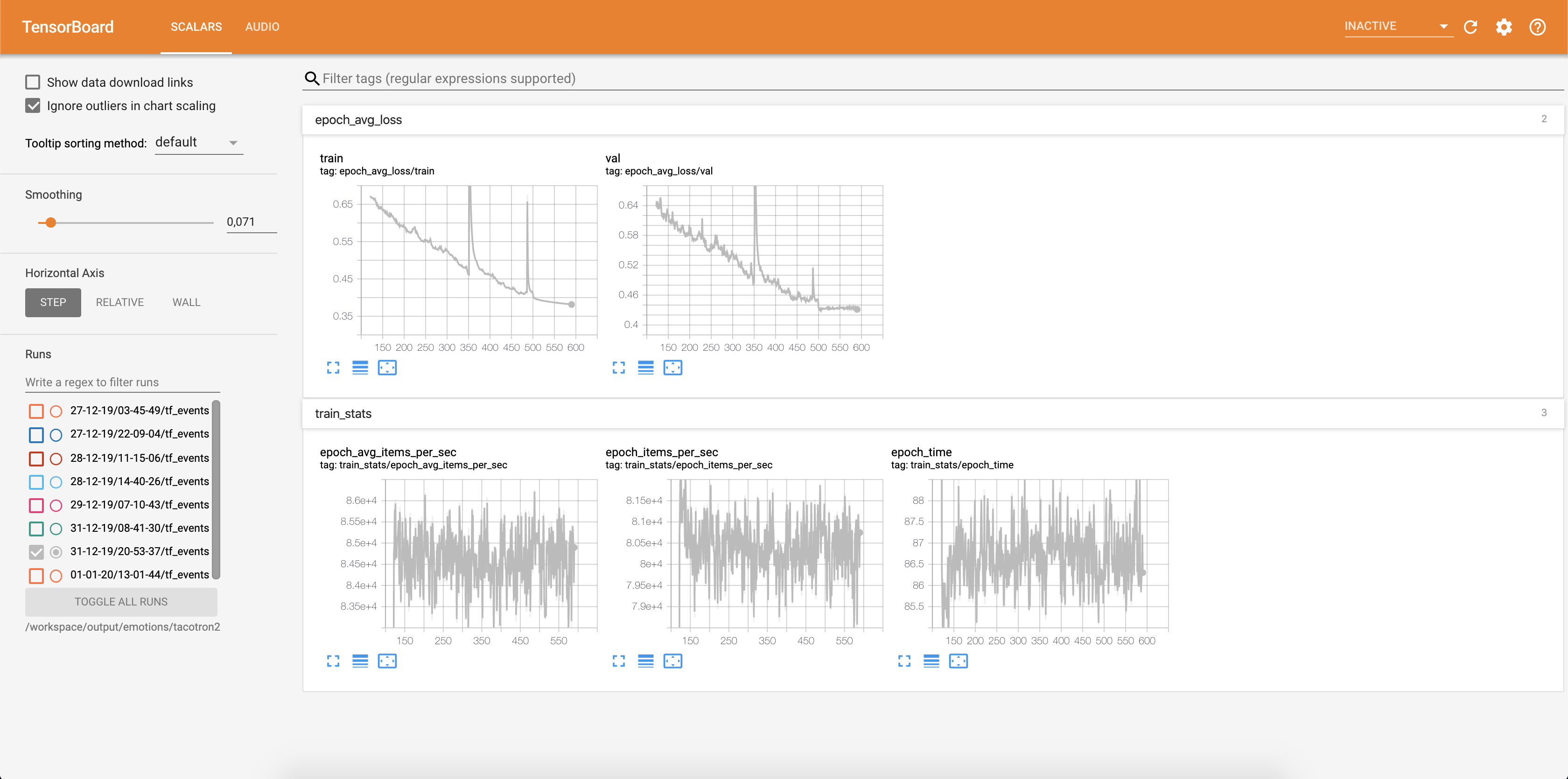
Les échantillons audio ainsi que les alignements d'attention sont enregistrés dans TensorBaord chaque Config.epochs_per_checkpoint . Les transcriptions des audios sont répertoriées dans Config.phrases
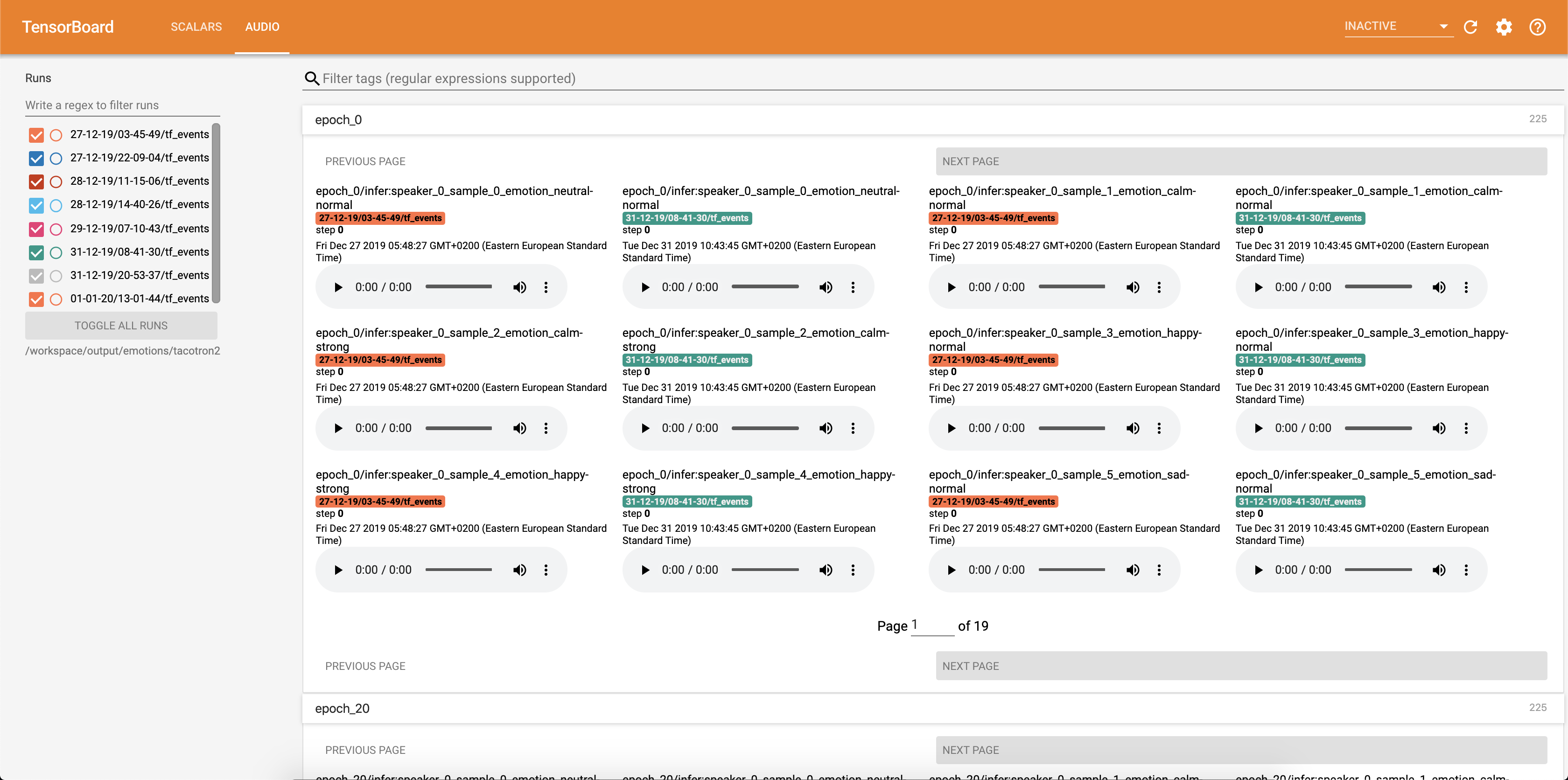
Exécution de l'inférence avec le cahier inference.ipynb .
Exécutez le cahier Jupyter:
jupyter notebook --ip 0.0.0.0 --port 6006 --no-browser --allow-root
sortir:
root@04096a19c266:/app# jupyter notebook --ip 0.0.0.0 --port 6006 --no-browser --allow-root
[I 09:31:25.393 NotebookApp] JupyterLab extension loaded from /opt/conda/lib/python3.6/site-packages/jupyterlab
[I 09:31:25.393 NotebookApp] JupyterLab application directory is /opt/conda/share/jupyter/lab
[I 09:31:25.395 NotebookApp] Serving notebooks from local directory: /app
[I 09:31:25.395 NotebookApp] The Jupyter Notebook is running at:
[I 09:31:25.395 NotebookApp] http://(04096a19c266 or 127.0.0.1):6006/?token=bbd413aef225c1394be3b9de144242075e651bea937eecce
[I 09:31:25.395 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 09:31:25.398 NotebookApp]
To access the notebook, open this file in a browser:
file:///root/.local/share/jupyter/runtime/nbserver-15398-open.html
Or copy and paste one of these URLs:
http://(04096a19c266 or 127.0.0.1):6006/?token=bbd413aef225c1394be3b9de144242075e651bea937eecce
Sélectionnez Adresse avec 127.0.0.1 et placez-le dans le navigateur. Dans ce cas: http://127.0.0.1:6006/?token=bbd413aef225c1394be3b9de144242075e651bea937eecce
Ce script prend du texte en entrée et exécute Tacotron 2, puis de l'inférence de l'éclairage des vagues pour produire un fichier audio. Il nécessite des points de contrôle pré-formés à partir de modèles Tacotron 2 et Wave Glow, Text d'entrée, Speaker_id et émotion_id.
Changer les chemins en points de contrôle du tacotron 2 pré-entraîné et l'éclat d'onde dans la cellule [2] de l' inference.ipynb .
Écrivez un texte à afficher dans la cellule [7] de l' inference.ipynb .
Dans cette section, nous énumérons les hyperparamètres les plus importants, ainsi que leurs valeurs par défaut qui sont utilisées pour former des modèles Tacotron 2 et Wave Glow.
epochs - Nombre d'époches (tacotron 2: 1501, éclairage d'ondes: 1001)learning-rate - Taux d'apprentissage (Tacotron 2: 1E-3, Glow Wave: 1E-4)batch-size - Taille du lot (Tacotron 2: 64, Glow Wave: 11)grad_clip_thresh - Clipping de gradient Treshold (0,1)sampling-rate à taux d'échantillonnage dans Hz de l'audio d'entrée et de sortie (22050)filter-length - (1024)hop-length - longueur de houblon pour FFT, c'est-à-dire, échantillon de foulée entre les FFT consécutives (256)win-length - Taille de la fenêtre pour FFT (1024)mel-fmin - Fréquence la plus basse en Hz (0,0)mel-fmax - Fréquence la plus élevée en Hz (8.000)anneal-steps - Epochs à laquelle recuire le taux d'apprentissage (500/1000/1500)anneal-factor - Facteur pour recuire le taux d'apprentissage (0,1) Ces deux paramètres sont utilisés pour changer le taux d'apprentissage aux points définis en anneal-steps selon:learning_rate = learning_rate * ( anneal_factor ** p) ,p = 0 à la première étape et incréments de 1 à chaque étape.segment-length - Longueur du segment de l'audio d'entrée traité par le réseau neuronal (8000). Avant de passer à l'entrée, l'audio est rembourré ou recadré à segment-length .wn_config - Dictionnaire avec paramètres des couches de couplage affine. Contient n_layers , n_chanels , kernel_size . Si vous avez toujours voulu contribuer à l'open source, et une grande cause, c'est maintenant votre chance!
Voir les documents contributifs pour plus d'informations


