tacotron2
1.0.0
Este repositorio contiene un código de muestra para Tacotron 2, Glow con múltiples altavoces, incrustaciones de emoción junto con un script para el preprocesamiento de datos.
Los puntos de control y el código se originan en las siguientes fuentes:
configs/experiments La siguiente sección enumera los requisitos para comenzar a capacitar los modelos Tacotron 2 y Wavlow.
Clon el repositorio:
git clone https://github.com/ide8/tacotron2
cd tacotron2
PROJDIR= $( pwd )
export PYTHONPATH= $PROJDIR : $PYTHONPATHEste repositorio contiene DockerFile que extiende el contenedor Pytorch NGC y encapsula algunas dependencias. Además de estas dependencias, asegúrese de tener los siguientes componentes:
Cree una imagen desde el archivo Docker:
docker build --tag taco .Ejecutar el contenedor Docker:
docker run --shm-size=8G --runtime=nvidia -v /absolute/path/to/your/code:/app -v /absolute/path/to/your/training_data:/mnt/train -v /absolute/path/to/your/logs:/mnt/logs -v /absolute/path/to/your/raw-data:/mnt/raw-data -v /absolute/path/to/your/pretrained-checkpoint:/mnt/pretrained -detach taco sleep infVerifique la identificación del contenedor:
docker ps Seleccione ID de contenedor de la imagen con la etiqueta taco e inicie sesión en contenedor con:
docker exec -it container_id bash
Carpetas tacotron2 y waveglow tienen scripts para Tacotron 2, modelos de Glow y consisten en:
<model_name>/model.py - Arquitectura de modelos<model_name>/data_function.py - Funciones de carga de datos<model_name>/loss_function.py - Función de pérdida La carpeta common contiene capas comunes para ambos modelos ( common/layers.py ), Utils ( common/utils.py ) y Procesamiento de audio ( common/audio_processing.py y common/stft.py ).
router de carpetas se utiliza mediante el script de entrenamiento para seleccionar un modelo apropiado
En el directorio raíz:
train.py - Script para el entrenamiento modelopreprocess.py : realiza el procesamiento de audio y crea conjuntos de datos de capacitación y validacióninference.ipynb - cuaderno para ejecutar inferencia configs de carpetas contiene __init__.py con todos los parámetros necesarios para la capacitación y el procesamiento de datos. configs/experiments de carpetas consiste en todos los experimentos. waveglow.py y tacotron2.py se proporcionan como ejemplos para WaveGlow y Tacotron 2. En el inicio de entrenamiento o procesamiento de datos, los parámetros se copian de su experimento (en nuestro caso, desde waveglow.py o de tacotron2.py ) a __init__.py , desde el cual el sistema usa el sistema.
wavs y el archivo metadata.csv con el siguiente formato de línea: file_name.wav|text .configs/experiments/waveglow.py o en configs/experiments/tacotron2.py , en la clase PreprocessingConfig .start_from_preprocessed en False . preprocess.py realiza el recorte de archivos de audio hasta PreprocessingConfig.top_db (corta el silencio al principio y al final), aplica el comando FFMPEG para mono, hacer la misma velocidad de muestreo y tasa de bits para todos los Wavs en el conjunto de datos.wavs con archivos de audio procesados y archivo data.csv en PreprocessingConfig.output_directory con el siguiente formato: path|text|speaker_name|speaker_id|emotion|text_len|duration .process_audio es verdadero . Los altavoces con bandera emotion_present son falsos , se tratan como con emoción neutral-normal .start_from_preprocessed = False una vez que termine de ejecutar el script de preprocesamiento. La única excepción en caso de nuevos datos sin procesar.start_from_preprocessed se establece en True , Script Loads File data.csv (creado por start_from_preprocessed = False Run), y forma train.txt y val.txt de data.csv .PreprocessingConfig :cpus : define el número de núcleos para el generador de lotessr - Define la relación de muestra para leer y escribir audioemo_id_map - Diccionario para el nombre de la emoción a la mapeo de emoción_iddata[{'path'}] : es una ruta a la carpeta llamada con el nombre del altavoz y que contiene la carpeta wavs y metadata.csv con el siguiente formato de línea: file_name.wav|text|emotion (optional)PreprocessingConfig.limit_by de altavoces (este paso es necesario para el tamaño de lote adecuado)PreprocessingConfig.text_limit y PreprocessingConfig.dur_limit . El límite inferior para el audio se define mediante PreprocessingConfig.minimum_viable_durPreprocessingConfig.text_limit en linda_jonsontrain : val = 0.95 : 0.05PreprocessingConfig.n - muestras n filastrain.txt y val.txt a PreprocessingConfig.output_directoryemotion_coefficients.json y speaker_coefficients.json con coeficientes para el equilibrio de pérdidas (utilizada por train.py ). Dado que ambos scripts waveglow.py y tacotron2.py contienen la clase PreprocessingConfig , el conjunto de datos de entrenamiento y validación se puede producir ejecutando cualquiera de ellos:
python preprocess.py --exp tacotron2
o
python preprocess.py --exp waveglow
En configs/experiment/tacotron2.py , en el conjunto Config de clase:
training_files y validation_files - rutas a train.txt , val.txt ;tacotron_checkpoint - ruta hacia el tacotrón 2 previos al detenido si existe (pudimos restaurar el resplandor de onda de Nvidia, pero el código Tacotron 2 se editó para agregar altavoces y emociones, por lo que Tacotron 2 necesita ser entrenado desde cero);speaker_coefficients - ruta a speaker_coefficients.json ;emotion_coefficients - camino a emotion_coefficients.json ;output_directory - ruta para escribir registros y puntos de control;use_emotions - indicando el uso de emociones;use_loss_coefficients : indicando la escala de pérdida debido a la posible desbalance de datos en términos de altavoces y emociones; Para la pérdida de equilibrio, establezca caminos en JSON con coeficientes en emotion_coefficients y speaker_coefficients ;model_name - "Tacotron2" . python train.py --exp tacotron2
python -m multiproc train.py --exp tacotron2
En configs/experiment/waveglow.py , en el conjunto Config de clase:
training_files y validation_files - rutas a train.txt , val.txt ;waveglow_checkpoint - Ruta al Glow de onda previamente pretrados, restaurado desde NVIDIA. Descargar checkopoint.output_directory - ruta para escribir registros y puntos de control;use_emotions - falso ;use_loss_coefficients - falso ;model_name - "WaveGlow" . python train.py --exp waveglow
python -m multiproc train.py --exp waveglow
Una vez que haya hecho que su modelo comience la capacitación, es posible que desee ver algún progreso de la capacitación:
docker ps
Seleccione ID de contenedor de la imagen con TAG taco y Ejecutar:
docker exec -it container_id bash
Iniciar TensorBoard:
tensorboard --logdir=path_to_folder_with_logs --host=0.0.0.0
La pérdida se está escribiendo en Tensorboard:
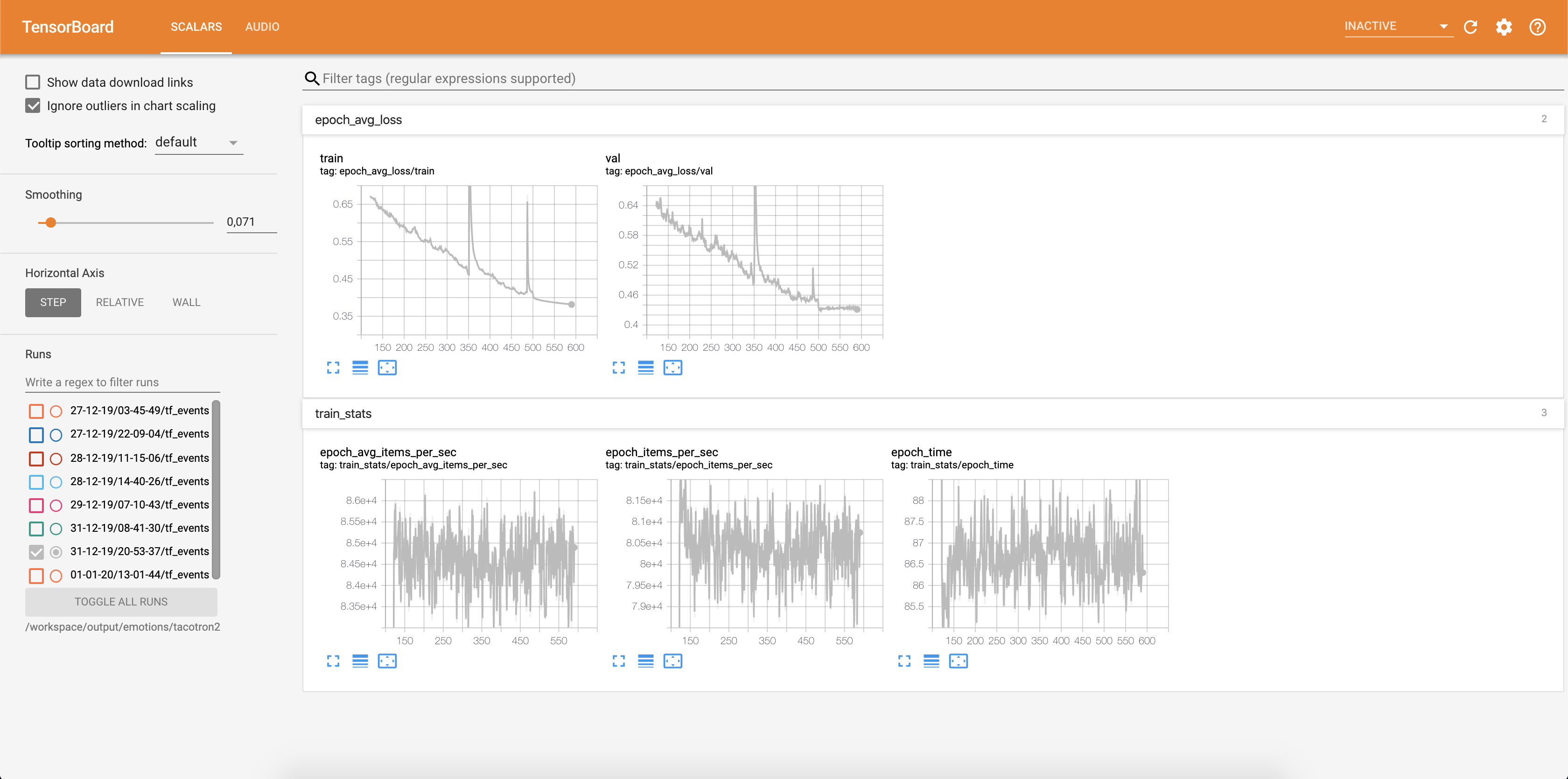
Las muestras de audio junto con las alineaciones de atención se guardan en Tensorbaord cada Config.epochs_per_checkpoint . Las transcripciones para audios se enumeran en Config.phrases
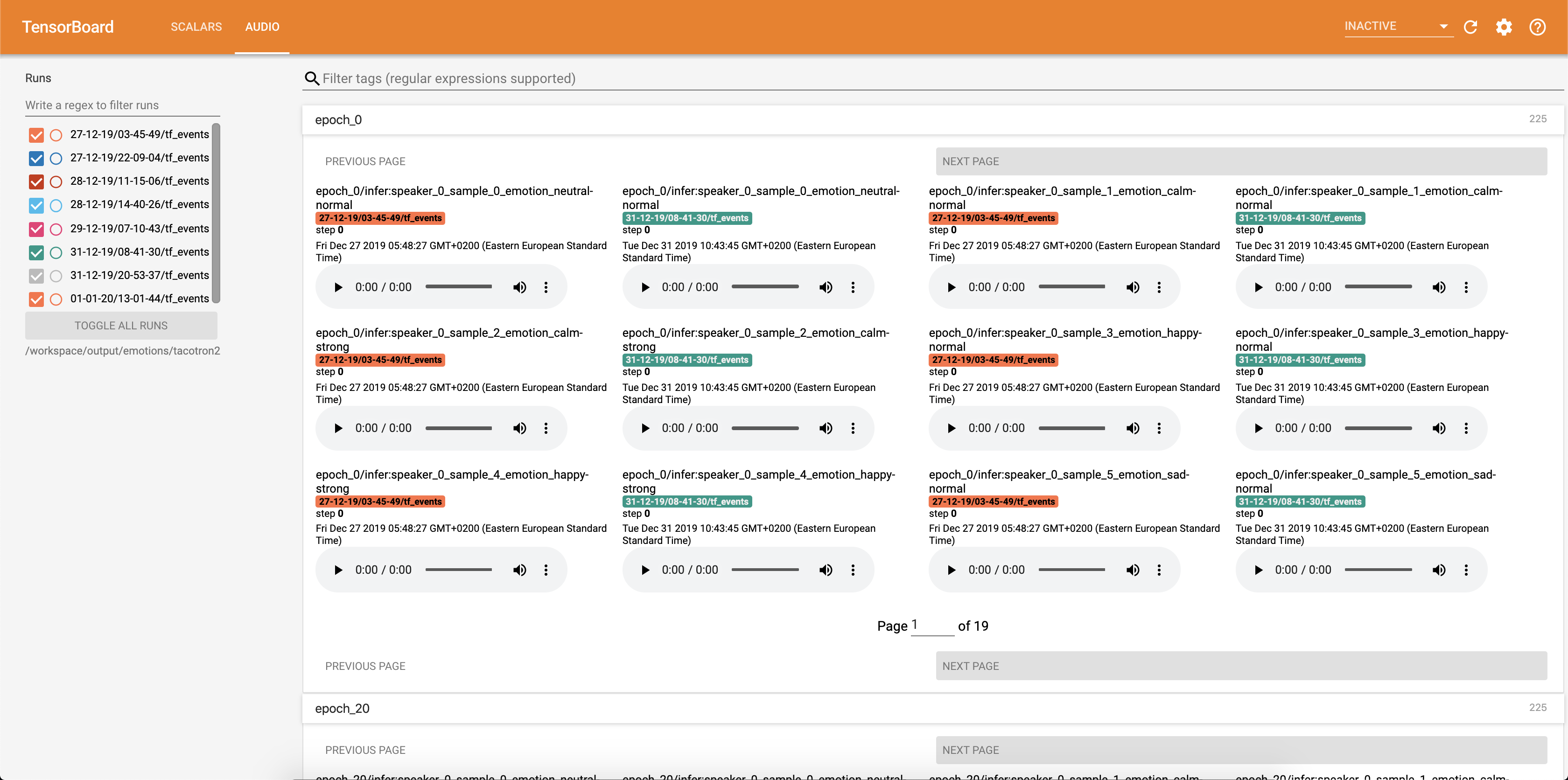
Ejecutando inferencia con la inference.ipynb cuaderno.
Ejecutar el cuaderno Jupyter:
jupyter notebook --ip 0.0.0.0 --port 6006 --no-browser --allow-root
producción:
root@04096a19c266:/app# jupyter notebook --ip 0.0.0.0 --port 6006 --no-browser --allow-root
[I 09:31:25.393 NotebookApp] JupyterLab extension loaded from /opt/conda/lib/python3.6/site-packages/jupyterlab
[I 09:31:25.393 NotebookApp] JupyterLab application directory is /opt/conda/share/jupyter/lab
[I 09:31:25.395 NotebookApp] Serving notebooks from local directory: /app
[I 09:31:25.395 NotebookApp] The Jupyter Notebook is running at:
[I 09:31:25.395 NotebookApp] http://(04096a19c266 or 127.0.0.1):6006/?token=bbd413aef225c1394be3b9de144242075e651bea937eecce
[I 09:31:25.395 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 09:31:25.398 NotebookApp]
To access the notebook, open this file in a browser:
file:///root/.local/share/jupyter/runtime/nbserver-15398-open.html
Or copy and paste one of these URLs:
http://(04096a19c266 or 127.0.0.1):6006/?token=bbd413aef225c1394be3b9de144242075e651bea937eecce
Seleccione direccionar con 127.0.0.1 y colóquela en el navegador. En este caso: http://127.0.0.1:6006/?token=bbd413aef225c1394be3b9de144242075e651bea937eecce
Este script toma el texto como entrada y ejecuta Tacotron 2 y luego la inferencia de globo de onda para producir un archivo de audio. Requiere puntos de control previamente capacitados de Tacotron 2 y modelos de Glow, texto de entrada, Speaker_id y emoción_id.
Cambiar las rutas a los puntos de control del tacotrón 2 y el brillo de onda en la célula [2] de la inference.ipynb .
Escriba un texto que se muestre en la celda [7] de la inference.ipynb .
En esta sección, enumeramos los hiperparámetros más importantes, junto con sus valores predeterminados que se utilizan para entrenar a los modelos Tacotron 2 y Wavlow.
epochs - Número de épocas (Tacotron 2: 1501, Glow: 1001)learning-rate -Tasa de aprendizaje (Tacotron 2: 1e-3, Glow de onda: 1e-4)batch-size - tamaño por lotes (Tacotron 2: 64, Glowwow: 11)grad_clip_thresh - Trestaldo de recorte de gradiente (0.1)sampling-rate : velocidad de muestreo en Hz de audio de entrada y salida (22050)filter-length - (1024)hop-length - longitud de lúpulo para FFT, es decir, paso de muestra entre FFT consecutivos (256)win-length para FFT (1024)mel-fmin : la frecuencia más baja en Hz (0.0)mel-fmax - La mayor frecuencia en Hz (8.000)anneal-steps : épocas en las cuales recocir la tasa de aprendizaje (500/1000/ 1500)anneal-factor : factor por el cual recocir la tasa de aprendizaje (0.1) Estos dos parámetros se utilizan para cambiar la tasa de aprendizaje en los puntos definidos en anneal-steps según:learning_rate = learning_rate * ( anneal_factor ** p) ,p = 0 en el primer paso e incrementos en 1 cada paso.segment-length : longitud del segmento del audio de entrada procesado por la red neuronal (8000). Antes de pasar a la entrada, el audio está acolchado o recortado a segment-length .wn_config - Diccionario con parámetros de capas de acoplamiento afín. Contiene n_layers , n_chanels , kernel_size . Si alguna vez has querido contribuir a un código abierto, y una gran causa, ¡ahora es tu oportunidad!
Consulte los documentos contribuyentes para obtener más información


