tacotron2
1.0.0
ที่เก็บนี้มีรหัสตัวอย่างสำหรับ Tacotron 2, Waveglow ที่มีหลายลำโพง, Emotion Embeddings พร้อมกับสคริปต์สำหรับการประมวลผลข้อมูลล่วงหน้า
จุดตรวจและรหัสมาจากแหล่งข้อมูลต่อไปนี้:
configs/experiments ส่วนต่อไปนี้แสดงรายการข้อกำหนดเพื่อเริ่มการฝึกอบรมโมเดล Tacotron 2 และ Waveglow
โคลนที่เก็บ:
git clone https://github.com/ide8/tacotron2
cd tacotron2
PROJDIR= $( pwd )
export PYTHONPATH= $PROJDIR : $PYTHONPATHที่เก็บนี้มี DockerFile ซึ่งขยายคอนเทนเนอร์ Pytorch NGC และห่อหุ้มการพึ่งพาบางอย่าง นอกเหนือจากการพึ่งพาเหล่านี้ตรวจสอบให้แน่ใจว่าคุณมีส่วนประกอบดังต่อไปนี้:
สร้างภาพจากไฟล์ Docker:
docker build --tag taco .เรียกใช้คอนเทนเนอร์ Docker:
docker run --shm-size=8G --runtime=nvidia -v /absolute/path/to/your/code:/app -v /absolute/path/to/your/training_data:/mnt/train -v /absolute/path/to/your/logs:/mnt/logs -v /absolute/path/to/your/raw-data:/mnt/raw-data -v /absolute/path/to/your/pretrained-checkpoint:/mnt/pretrained -detach taco sleep infตรวจสอบ ID คอนเทนเนอร์:
docker ps เลือก ID container ของภาพด้วยแท็ก taco และเข้าสู่คอนเทนเนอร์ด้วย:
docker exec -it container_id bash
โฟลเดอร์ tacotron2 และ waveglow มีสคริปต์สำหรับ TACOTRON 2 แบบจำลอง WAWGLOW และประกอบด้วย::
<model_name>/model.py - สถาปัตยกรรมรุ่น<model_name>/data_function.py - ฟังก์ชั่นการโหลดข้อมูล<model_name>/loss_function.py - ฟังก์ชั่นการสูญเสีย โฟลเดอร์ common ประกอบด้วยเลเยอร์ทั่วไปสำหรับทั้งสองรุ่น ( common/layers.py ), utils ( common/utils.py ) และการประมวลผลเสียง ( common/audio_processing.py และ common/stft.py )
router โฟลเดอร์ถูกใช้โดยสคริปต์การฝึกอบรมเพื่อเลือกรุ่นที่เหมาะสม
ในไดเรกทอรีราก:
train.py - สคริปต์สำหรับการฝึกอบรมแบบจำลองpreprocess.py - ดำเนินการประมวลผลเสียงและสร้างชุดข้อมูลการฝึกอบรมและการตรวจสอบความถูกต้องinference.ipynb - สมุดบันทึกสำหรับการอนุมาน configs โฟลเดอร์ประกอบด้วย __init__.py พร้อมพารามิเตอร์ทั้งหมดที่จำเป็นสำหรับการฝึกอบรมและการประมวลผลข้อมูล โฟลเดอร์ configs/experiments ประกอบด้วยการทดลองทั้งหมด waveglow.py และ tacotron2.py มีให้เป็นตัวอย่างสำหรับ WAWGLOW และ TACOTRON 2. ในการฝึกอบรมหรือเริ่มต้นการประมวลผลข้อมูลพารามิเตอร์จะถูกคัดลอกมาจากการทดลองของคุณ (ในกรณีของเรา - จาก waveglow.py หรือจาก tacotron2.py ) ถึง __init__.py
wavs และไฟล์ metadata.csv พร้อมรูปแบบบรรทัดถัดไป: file_name.wav|textconfigs/experiments/waveglow.py หรือใน configs/experiments/tacotron2.py ในคลาส PreprocessingConfigstart_from_preprocessed เป็น เท็จ preprocess.py ทำการตัดแต่งไฟล์เสียงจนถึง PreprocessingConfig.top_db (ตัดความเงียบในตอนต้นและจุดสิ้นสุด) ใช้คำสั่ง FFMPEG เพื่อโมโนสร้างอัตราการสุ่มตัวอย่างและอัตราบิตเดียวกันสำหรับ WAV ทั้งหมดในชุดข้อมูลwavs ด้วยไฟล์เสียงที่ประมวลผลและไฟล์ data.csv ใน PreprocessingConfig.output_directory ด้วยรูปแบบต่อไปนี้: path|text|speaker_name|speaker_id|emotion|text_len|durationprocess_audio เป็น จริง ลำโพงที่มี Flag emotion_present เป็น เท็จได้ รับการปฏิบัติเช่นเดียวกับอารมณ์ความรู้สึก neutral-normalstart_from_preprocessed = False เมื่อคุณเรียกใช้สคริปต์การประมวลผลล่วงหน้าเสร็จแล้ว ข้อยกเว้นเฉพาะในกรณีของข้อมูลดิบใหม่เข้ามาstart_from_preprocessed เป็น จริง สคริปต์โหลด data.csv (สร้างโดย start_from_preprocessed = False run) และแบบฟอร์ม train.txt และ val.txt จาก data.csvPreprocessingConfig หลัก:cpus - กำหนดจำนวนคอร์สำหรับเครื่องกำเนิดแบทช์sr - กำหนดอัตราส่วนตัวอย่างสำหรับการอ่านและการเขียนเสียงemo_id_map - พจนานุกรมสำหรับชื่ออารมณ์เพื่อการแมป Emotion_IDdata[{'path'}] - เป็นเส้นทางไปยังโฟลเดอร์ที่ชื่อด้วยชื่อลำโพงและมีโฟลเดอร์ wavs และ metadata.csv พร้อมรูปแบบบรรทัดต่อไปนี้: file_name.wav|text|emotion (optional)PreprocessingConfig.limit_by (ขั้นตอนนี้จำเป็นสำหรับขนาดแบทช์ที่เหมาะสม)PreprocessingConfig.text_limit และ PreprocessingConfig.dur_limit ขีด จำกัด ล่างสำหรับเสียงถูกกำหนดโดย PreprocessingConfig.minimum_viable_durPreprocessingConfig.text_limit เป็น linda_jonsontrain : val = 0.95 : 0.05PreprocessingConfig.n - ตัวอย่าง n แถวtrain.txt และ val.txt เพื่อ PreprocessingConfig.output_directoryemotion_coefficients.json และ speaker_coefficients.json ด้วยค่าสัมประสิทธิ์สำหรับการปรับสมดุลการสูญเสีย (ใช้โดย train.py ) เนื่องจากสคริปต์ทั้งสอง waveglow.py และ tacotron2.py มีคลาส PreprocessingConfig , ชุดข้อมูลการฝึกอบรมและการตรวจสอบความถูกต้องสามารถผลิตได้โดยการเรียกใช้ใด ๆ :
python preprocess.py --exp tacotron2
หรือ
python preprocess.py --exp waveglow
ใน configs/experiment/tacotron2.py ในชุด Config คลาส:
training_files and validation_files - เส้นทางสู่ train.txt , val.txt ;tacotron_checkpoint - เส้นทางสู่ Tacotron 2 ที่ผ่านการฝึกฝนก่อนหน้านี้ (เราสามารถกู้คืน Waveglow จาก Nvidia ได้ แต่รหัส Tacotron 2 ได้รับการแก้ไขเพื่อเพิ่มลำโพงและอารมณ์ดังนั้น Tacotron 2 จึงจำเป็นต้องได้รับการฝึกฝนตั้งแต่เริ่มต้น);speaker_coefficients - Path to speaker_coefficients.json ;emotion_coefficients - เส้นทางสู่ emotion_coefficients.json ;output_directory - เส้นทางสำหรับการเขียนบันทึกและจุดตรวจuse_emotions - การตั้งค่าสถานะการใช้อารมณ์การใช้งาน;use_loss_coefficients - ตั้งค่าสถานะการปรับสเกลการสูญเสียเนื่องจากความไม่สมดุลของข้อมูลที่เป็นไปได้ในแง่ของทั้งลำโพงและอารมณ์ สำหรับการสร้างความสมดุลให้ตั้งเส้นทางไปยัง JSONS ด้วยค่าสัมประสิทธิ์ใน emotion_coefficients และ speaker_coefficients ;model_name - "Tacotron2" python train.py --exp tacotron2
python -m multiproc train.py --exp tacotron2
ใน configs/experiment/waveglow.py ในชุด Config คลาส:
training_files and validation_files - เส้นทางสู่ train.txt , val.txt ;waveglow_checkpoint - PATH TO TO TO PRETRANTED WAWGLOW ได้รับการฟื้นฟูจาก NVIDIA ดาวน์โหลด CheckOpointoutput_directory - เส้นทางสำหรับการเขียนบันทึกและจุดตรวจuse_emotions - FALSE ;use_loss_coefficients - false ;model_name - "WaveGlow" python train.py --exp waveglow
python -m multiproc train.py --exp waveglow
เมื่อคุณทำการฝึกอบรมแบบจำลองของคุณแล้วคุณอาจต้องการเห็นความคืบหน้าของการฝึกอบรม:
docker ps
เลือก ID คอนเทนเนอร์ของภาพด้วยแท็ก taco แล้วเรียกใช้:
docker exec -it container_id bash
เริ่มต้น Tensorboard:
tensorboard --logdir=path_to_folder_with_logs --host=0.0.0.0
การสูญเสียกำลังเขียนลงใน Tensorboard:
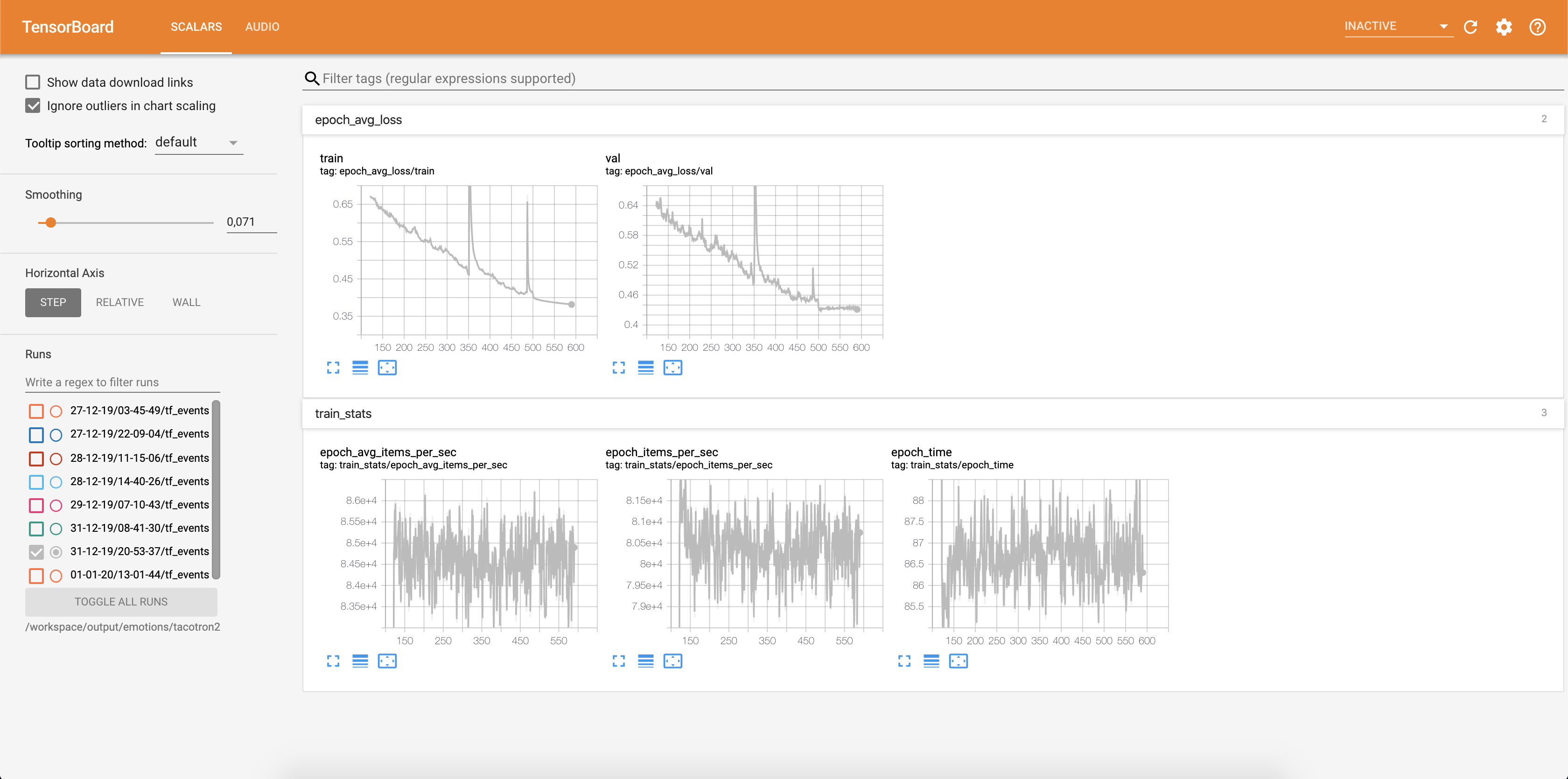
ตัวอย่างเสียงพร้อมกับการจัดตำแหน่งความสนใจจะถูกบันทึกลงใน tensorbaord แต่ละ Config.epochs_per_checkpoint การถอดเสียงสำหรับเสียงแสดงอยู่ใน Config.phrases
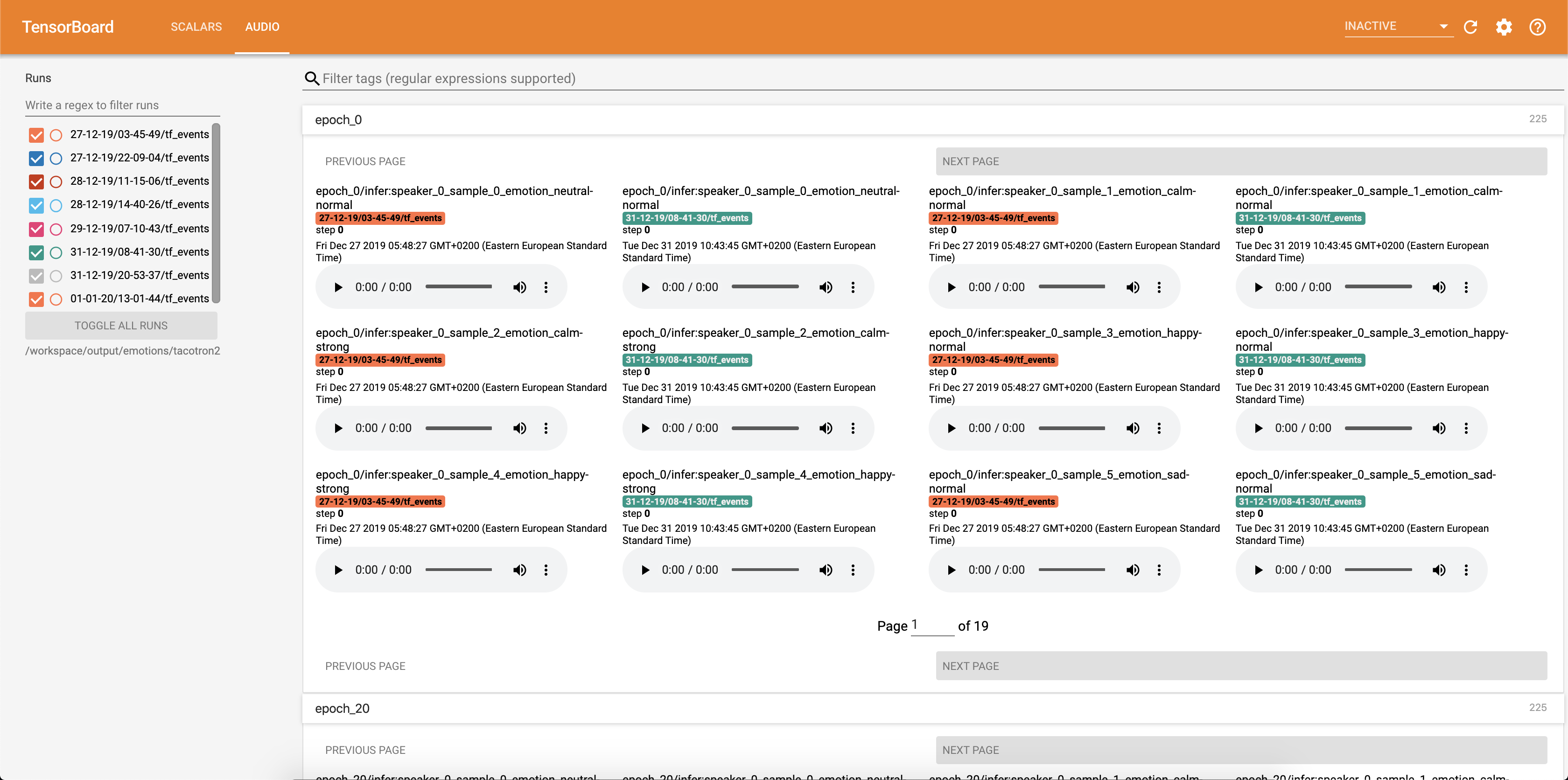
เรียกใช้การอนุมานกับสมุด inference.ipynb
เรียกใช้สมุดบันทึก Jupyter:
jupyter notebook --ip 0.0.0.0 --port 6006 --no-browser --allow-root
เอาท์พุท:
root@04096a19c266:/app# jupyter notebook --ip 0.0.0.0 --port 6006 --no-browser --allow-root
[I 09:31:25.393 NotebookApp] JupyterLab extension loaded from /opt/conda/lib/python3.6/site-packages/jupyterlab
[I 09:31:25.393 NotebookApp] JupyterLab application directory is /opt/conda/share/jupyter/lab
[I 09:31:25.395 NotebookApp] Serving notebooks from local directory: /app
[I 09:31:25.395 NotebookApp] The Jupyter Notebook is running at:
[I 09:31:25.395 NotebookApp] http://(04096a19c266 or 127.0.0.1):6006/?token=bbd413aef225c1394be3b9de144242075e651bea937eecce
[I 09:31:25.395 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 09:31:25.398 NotebookApp]
To access the notebook, open this file in a browser:
file:///root/.local/share/jupyter/runtime/nbserver-15398-open.html
Or copy and paste one of these URLs:
http://(04096a19c266 or 127.0.0.1):6006/?token=bbd413aef225c1394be3b9de144242075e651bea937eecce
เลือกที่อยู่ด้วย 127.0.0.1 และใส่ไว้ในเบราว์เซอร์ ในกรณีนี้: http://127.0.0.1:6006/?token=bbd413aef225c1394be3b9de144242075e651bea937eecce
สคริปต์นี้ใช้ข้อความเป็นอินพุตและเรียกใช้ Tacotron 2 จากนั้นการอนุมาน Waveglow เพื่อสร้างไฟล์เสียง ต้องใช้จุดตรวจสอบที่ผ่านการฝึกอบรมมาล่วงหน้าจากรุ่น Tacotron 2 และ Waveglow, ข้อความอินพุต, Speaker_id และ Emotion_id
เปลี่ยนเส้นทางไปยังจุดตรวจของ Tacotron 2 และ Waveglow ในเซลล์ [2] ของ inference.ipynb ipynb
เขียนข้อความที่จะแสดงในเซลล์ [7] ของ inference.ipynb .ipynb
ในส่วนนี้เราแสดงรายการไฮเปอร์พารามิเตอร์ที่สำคัญที่สุดพร้อมกับค่าเริ่มต้นของพวกเขาที่ใช้ในการฝึกอบรม Tacotron 2 และรุ่น Waveglow
epochs - จำนวนยุค (Tacotron 2: 1501, Waveglow: 1001)learning-rate -อัตราการเรียนรู้ (Tacotron 2: 1E-3, Waveglow: 1E-4)batch-size - ขนาดแบทช์ (Tacotron 2: 64, Waveglow: 11)grad_clip_thresh - การไล่ระดับสี treshold (0.1)sampling-rate - อัตราการสุ่มตัวอย่างใน Hz ของเสียงอินพุตและเอาต์พุต (22050)filter-length - (1024)hop-length - ความยาวฮอปสำหรับ FFT, IE, ตัวอย่างก้าวย่างระหว่าง FFTs ติดต่อกัน (256)win-length - ขนาดหน้าต่างสำหรับ FFT (1024)mel-fmin - ความถี่ต่ำสุดใน Hz (0.0)mel-fmax - ความถี่สูงสุดใน Hz (8.000)anneal-steps - ยุคที่จะทำให้อัตราการเรียนรู้ (500/1000/1500) หลอมละลายanneal-factor ปัจจัยที่จะทำให้อัตราการเรียนรู้ (0.1) พารามิเตอร์ทั้งสองนี้ใช้เพื่อเปลี่ยนอัตราการเรียนรู้ ณ จุดที่กำหนดไว้ใน anneal-steps ตาม::learning_rate = learning_rate * ( anneal_factor ** p)p = 0 ในขั้นตอนแรกและเพิ่มขึ้น 1 ขั้นตอนsegment-length - ความยาวส่วนของเสียงอินพุตที่ประมวลผลโดยเครือข่ายประสาท (8000) ก่อนที่จะส่งผ่านไปยังอินพุตเสียงจะมีเบาะหรือครอบตัดเป็น segment-lengthwn_config - พจนานุกรมที่มีพารามิเตอร์ของเลเยอร์การเชื่อมต่อแบบเลียนแบบ มี n_layers , n_chanels , kernel_size หากคุณต้องการมีส่วนร่วมในโอเพ่นซอร์สและเป็นสาเหตุที่ดีตอนนี้เป็นโอกาสของคุณ!
ดูเอกสารที่มีส่วนร่วมสำหรับข้อมูลเพิ่มเติม


