tacotron2
1.0.0
Este repositório contém um código de amostra para o Tacotron 2, Waveglow com incorporações de emoções multi-falantes, juntamente com um script para pré-processamento de dados.
Pontos de verificação e código são originários das seguintes fontes:
configs/experiments A seção a seguir lista os requisitos para começar a treinar os modelos Tacotron 2 e Waveglow.
Clone o repositório:
git clone https://github.com/ide8/tacotron2
cd tacotron2
PROJDIR= $( pwd )
export PYTHONPATH= $PROJDIR : $PYTHONPATHEste repositório contém o DockerFile, que estende o contêiner Pytorch NGC e encapsula algumas dependências. Além dessas dependências, verifique se você possui os seguintes componentes:
Crie uma imagem a partir do arquivo do docker:
docker build --tag taco .Run Docker Container:
docker run --shm-size=8G --runtime=nvidia -v /absolute/path/to/your/code:/app -v /absolute/path/to/your/training_data:/mnt/train -v /absolute/path/to/your/logs:/mnt/logs -v /absolute/path/to/your/raw-data:/mnt/raw-data -v /absolute/path/to/your/pretrained-checkpoint:/mnt/pretrained -detach taco sleep infVerifique o ID do contêiner:
docker ps Selecione ID de contêiner de imagem com tag taco e faça login no contêiner com:
docker exec -it container_id bash
Pastas tacotron2 e waveglow têm scripts para o Tacotron 2, modelos Waveglow e consistem em:
<model_name>/model.py - arquitetura de modelo<model_name>/data_function.py - Funções de carregamento de dados<model_name>/loss_function.py - Função de perda A pasta common contém camadas comuns para os modelos ( common/layers.py ), Utils ( common/utils.py ) e processamento de áudio ( common/audio_processing.py e common/stft.py ).
router de pastas é usado por script de treinamento para selecionar um modelo apropriado
No diretório raiz:
train.py - Script para treinamento de modelopreprocess.py - executa processamento de áudio e cria conjuntos de dados de treinamento e validaçãoinference.ipynb - Notebook para a inferência de execução configs de pasta contém __init__.py com todos os parâmetros necessários para treinamento e processamento de dados. configs/experiments de pastas consistem em todos os experimentos. waveglow.py e tacotron2.py são fornecidos como exemplos para o Waveglow e Tacotron 2. No treinamento de treinamento ou processamento de dados, os parâmetros são copiados do seu experimento (no nosso caso - do waveglow.py ou de tacotron2.py ) a __init__.py , do qual são usados pelo sistema.
wavs e o arquivo metadata.csv com o próximo formato de linha: file_name.wav|text .configs/experiments/waveglow.py ou em configs/experiments/tacotron2.py , na classe PreprocessingConfig .start_from_preprocessed como false . preprocess.py executa o corte de arquivos de áudio para PreprocessingConfig.top_db (corta o silêncio no início e no final), aplica o comando ffmpeg para mono, fazer a mesma taxa de amostragem e taxa de bits para todos os wavs no conjunto de dados.wavs com arquivos de áudio processados e arquivo de data.csv no PreprocessingConfig.output_directory com o seguinte formato: path|text|speaker_name|speaker_id|emotion|text_len|duration .process_audio é verdadeiro . Os palestrantes com bandeira emotion_present são falsos , são tratados como com a emoção neutral-normal .start_from_preprocessed = False quando terminar de executar o script de pré -processamento. Somente exceção no caso de novos dados brutos entram.start_from_preprocessed for definido como true , o script carrega o arquivo data.csv (criado pelo start_from_preprocessed = False ) e forms train.txt e val.txt fora do data.csv .PreprocessingConfig :cpus - define o número de núcleos para gerador de lotesr - Define a proporção de amostra para leitura e escrita de áudioemo_id_map - DICIONÁRIO PARA NOME DE EMOÇÃO TO EMOUN_ID MAPPINGdata[{'path'}] - é o caminho para a pasta nomeada com o nome do alto -falante e contendo pasta wavs e metadata.csv com o seguinte formato de linha: file_name.wav|text|emotion (optional)PreprocessingConfig.limit_by (esta etapa é necessária para o tamanho adequado do lote)PreprocessingConfig.text_limit e PreprocessingConfig.dur_limit . O limite inferior para o áudio é definido pelo PreprocessingConfig.minimum_viable_durPreprocessingConfig.text_limit para linda_jonsontrain : val = 0.95 : 0.05PreprocessingConfig.n - amostras n linhastrain.txt e val.txt para PreprocessingConfig.output_directoryemotion_coefficients.json e speaker_coefficients.json com coeficientes para balanceamento de perdas (usado por train.py ). Como os scripts waveglow.py e tacotron2.py contêm o conjunto de dados PreprocessingConfig de classe, o conjunto de dados de treinamento e validação pode ser produzido executando qualquer um deles:
python preprocess.py --exp tacotron2
ou
python preprocess.py --exp waveglow
Em configs/experiment/tacotron2.py , no conjunto Config de classe:
training_files and validation_files - Caminhos para train.txt , val.txt ;tacotron_checkpoint - Caminho para o Tacotron 2 pré -criado se existir (fomos capazes de restaurar o Waveglow da NVIDIA, mas o código Tacotron 2 foi editado para adicionar alto -falantes e emoções, de modo que o Tacotron 2 precisa ser treinado do zero);speaker_coefficients - PATH para speaker_coefficients.json ;emotion_coefficients - Caminho para emotion_coefficients.json ;output_directory - caminho para escrever logs e pontos de verificação;use_emotions - sinalizador indicando o uso de emoções;use_loss_coefficients - Sinalizador indicando escala de perda devido ao possível desequilíbrio de dados em termos de alto -falantes e emoções; Para equilibrar a perda, defina caminhos para JSONs com coeficientes em emotion_coefficients e speaker_coefficients ;model_name - "Tacotron2" . python train.py --exp tacotron2
python -m multiproc train.py --exp tacotron2
Em configs/experiment/waveglow.py , no conjunto Config de classe:
training_files and validation_files - Caminhos para train.txt , val.txt ;waveglow_checkpoint - caminho para o Waveglow pré -criado, restaurado da NVIDIA. Faça o download do ponto de verificação.output_directory - caminho para escrever logs e pontos de verificação;use_emotions - false ;use_loss_coefficients - false ;model_name - "WaveGlow" . python train.py --exp waveglow
python -m multiproc train.py --exp waveglow
Depois de fazer seu modelo começar a treinar, convém ver algum progresso do treinamento:
docker ps
Selecione ID de contêiner da imagem com tag taco e execute:
docker exec -it container_id bash
Iniciar o Tensorboard:
tensorboard --logdir=path_to_folder_with_logs --host=0.0.0.0
A perda está sendo gravada em Tensorboard:
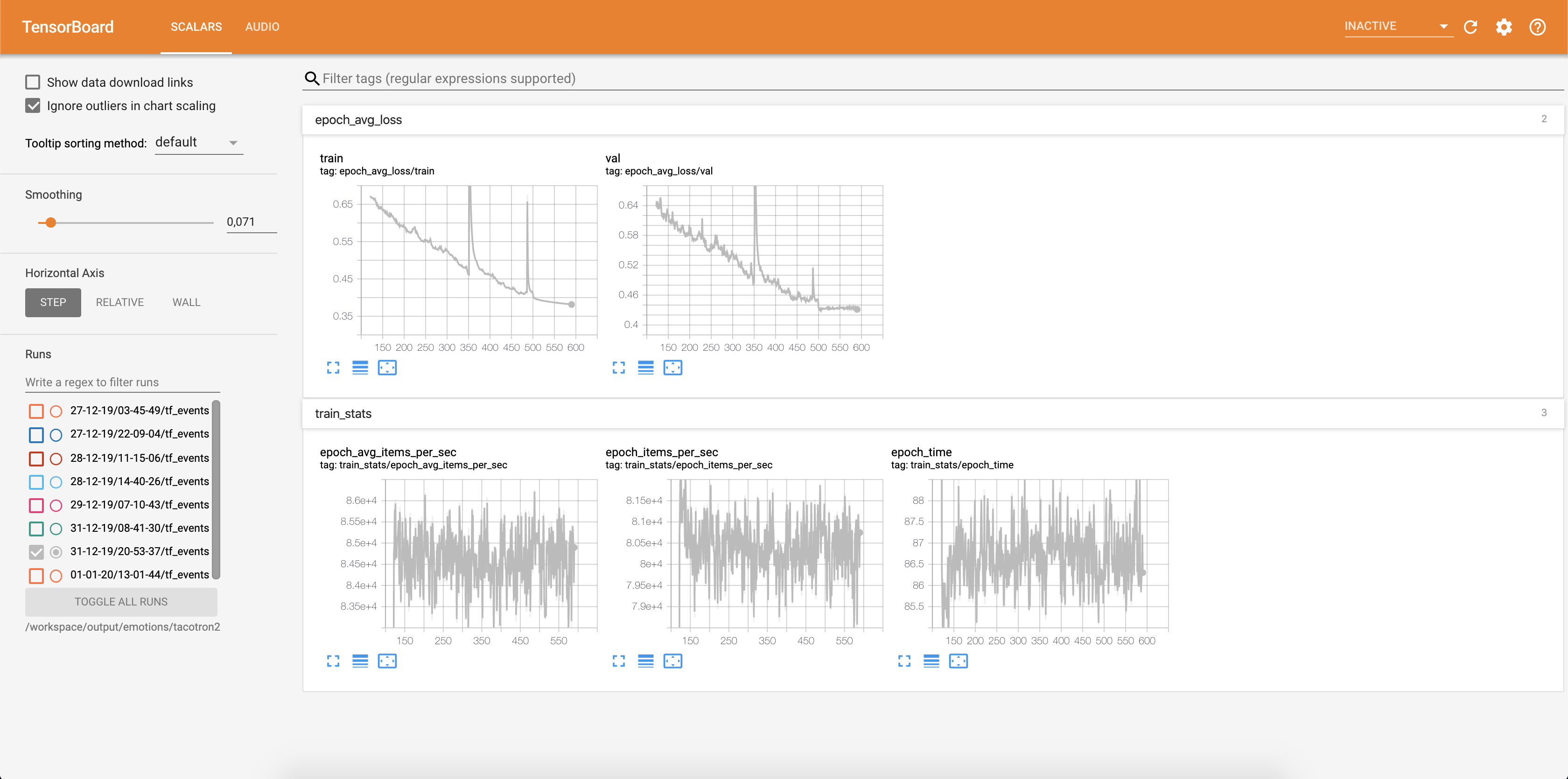
As amostras de áudio, juntamente com os alinhamentos de atenção, são salvas em tensorbaord cada Config.epochs_per_checkpoint . As transcrições para áudios estão listadas em Config.phrases
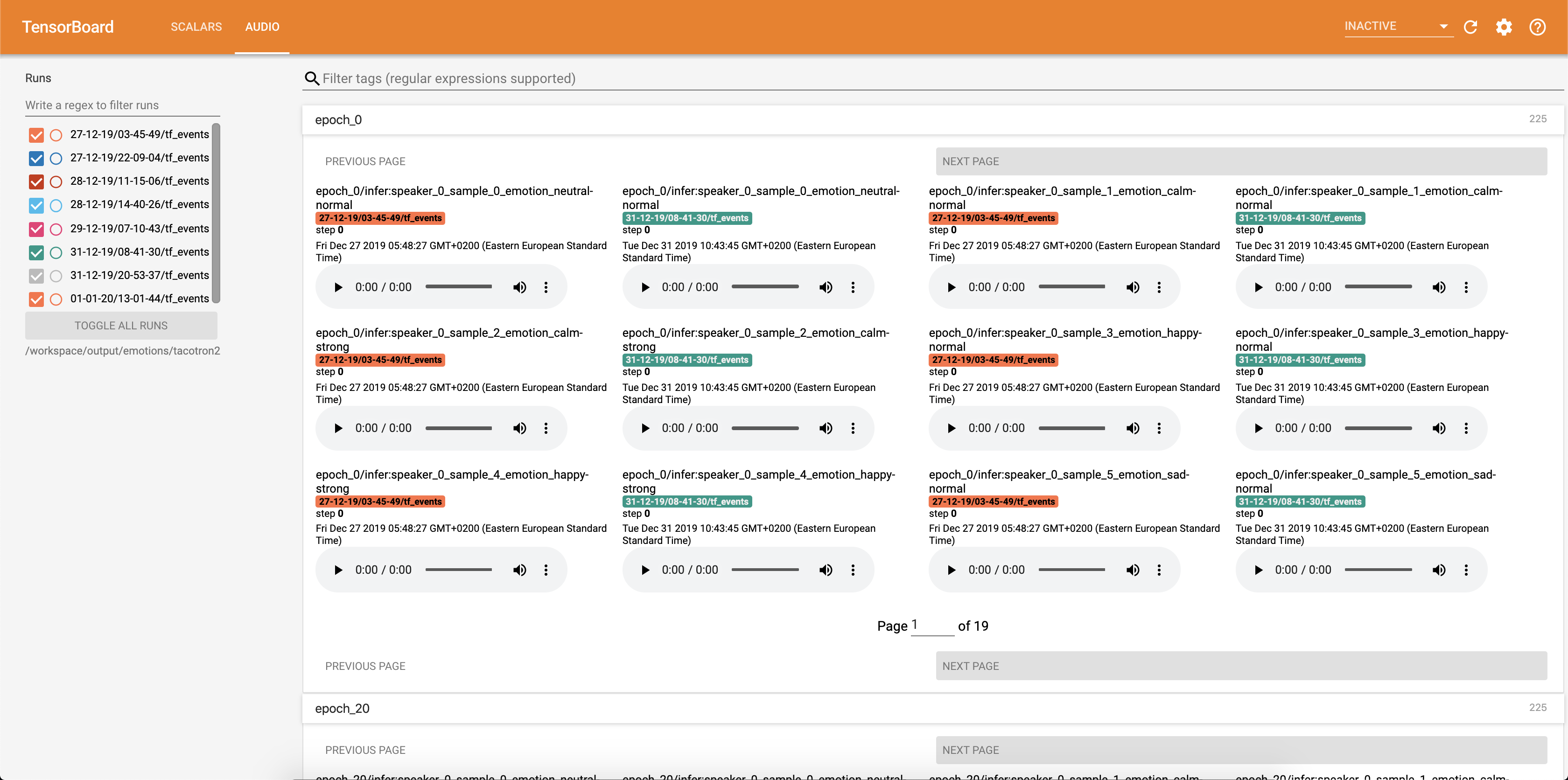
Execução de inferência no notebook inference.ipynb .
Run Jupyter Notebook:
jupyter notebook --ip 0.0.0.0 --port 6006 --no-browser --allow-root
saída:
root@04096a19c266:/app# jupyter notebook --ip 0.0.0.0 --port 6006 --no-browser --allow-root
[I 09:31:25.393 NotebookApp] JupyterLab extension loaded from /opt/conda/lib/python3.6/site-packages/jupyterlab
[I 09:31:25.393 NotebookApp] JupyterLab application directory is /opt/conda/share/jupyter/lab
[I 09:31:25.395 NotebookApp] Serving notebooks from local directory: /app
[I 09:31:25.395 NotebookApp] The Jupyter Notebook is running at:
[I 09:31:25.395 NotebookApp] http://(04096a19c266 or 127.0.0.1):6006/?token=bbd413aef225c1394be3b9de144242075e651bea937eecce
[I 09:31:25.395 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 09:31:25.398 NotebookApp]
To access the notebook, open this file in a browser:
file:///root/.local/share/jupyter/runtime/nbserver-15398-open.html
Or copy and paste one of these URLs:
http://(04096a19c266 or 127.0.0.1):6006/?token=bbd413aef225c1394be3b9de144242075e651bea937eecce
Selecione o endereço com 127.0.0.1 e coloque -o no navegador. Nesse caso: http://127.0.0.1:6006/?token=bbd413aef225c1394be3b9de144242075e651bea937eecce
Este script pega o texto como entrada e executa o Tacotron 2 e, em seguida, a inferência de waveglow para produzir um arquivo de áudio. Requer pontos de verificação pré-treinados dos modelos Tacotron 2 e Waveglow, texto de entrada, Speaker_id e Emotion_id.
Altere os caminhos para os pontos de verificação do tacotron 2 pré -terenciado e o globo da onda na célula [2] da inference.ipynb .
Escreva um texto a ser exibido na célula [7] da inference.ipynb .
Nesta seção, listamos os hiperparâmetros mais importantes, juntamente com seus valores padrão que são usados para treinar os modelos Tacotron 2 e Wave Glow.
epochs - Número de épocas (Tacotron 2: 1501, Waveglow: 1001)learning-rate -Taxa de aprendizagem (Tacotron 2: 1e-3, Waveglow: 1e-4)batch-size - tamanho do lote (Tacotron 2: 64, Waveglow: 11)grad_clip_thresh - recorte de gradiente (0,1)sampling-rate - Taxa de amostragem em Hz de áudio de entrada e saída (22050)filter-length - (1024)hop-length - comprimento do salto para fft, ou seja, passo de amostra entre FFTs consecutivos (256)win-length - Tamanho da janela para FFT (1024)mel-fmin - Frequência mais baixa em Hz (0,0)mel-fmax - Frequência mais alta em Hz (8.000)anneal-steps - épocas para recozinhar a taxa de aprendizagem (500/1000/1500)anneal-factor -fator pelo qual recozinhar a taxa de aprendizagem (0,1) Esses dois parâmetros são usados para alterar a taxa de aprendizado nos pontos definidos nas anneal-steps de acordo com:learning_rate = learning_rate * ( anneal_factor ** p)p = 0 na primeira etapa e incrementos em 1 cada etapa.segment-length - comprimento do segmento do áudio de entrada processado pela rede neural (8000). Antes de passar para a entrada, o áudio é acolchoado ou cultivado para o segment-length .wn_config - Dicionário com parâmetros de camadas de acoplamento afim. Contém n_layers , n_chanels , kernel_size . Se você já quis contribuir para o código aberto, e uma grande causa, agora é sua chance!
Veja os documentos contribuintes para obter mais informações


