tacotron2
1.0.0
Dieses Repository enthält einen Beispielcode für Tacotron 2, Wellenlow mit mehrsprachigem, Emotionsbettendings sowie ein Skript für die Datenvorverarbeitung.
Kontrollpunkte und Code stammen aus folgenden Quellen:
configs/experiments Der folgende Abschnitt listet die Anforderungen auf, um die Modelle Tacotron 2 und WaveGlow zu starten.
Klonen Sie das Repository:
git clone https://github.com/ide8/tacotron2
cd tacotron2
PROJDIR= $( pwd )
export PYTHONPATH= $PROJDIR : $PYTHONPATHDieses Repository enthält Dockerfile, das den Pytorch -NGC -Container erweitert und einige Abhängigkeiten enthält. Stellen Sie abgesehen von diesen Abhängigkeiten sicher, dass Sie die folgenden Komponenten haben:
Erstellen Sie ein Bild aus der Docker -Datei:
docker build --tag taco .Docker -Container ausführen:
docker run --shm-size=8G --runtime=nvidia -v /absolute/path/to/your/code:/app -v /absolute/path/to/your/training_data:/mnt/train -v /absolute/path/to/your/logs:/mnt/logs -v /absolute/path/to/your/raw-data:/mnt/raw-data -v /absolute/path/to/your/pretrained-checkpoint:/mnt/pretrained -detach taco sleep infContainer -ID überprüfen:
docker ps Wählen Sie Container -ID des Bildes mit Tag taco aus und melden Sie sich in Container an, mit:
docker exec -it container_id bash
Ordner tacotron2 und waveglow haben Skripte für Tacotron 2, Wellenlow -Modelle und bestehen aus:
<model_name>/model.py - Modellarchitektur<model_name>/data_function.py - Datenladefunktionen<model_name>/loss_function.py - Verlustfunktion Ordner common enthält gemeinsame Ebenen für beide Modelle ( common/layers.py ), Utils ( common/utils.py ) und Audio -Verarbeitung ( common/audio_processing.py und common/stft.py ).
Der router wird vom Trainingsskript verwendet, um ein geeignetes Modell auszuwählen
Im Root -Verzeichnis:
train.py - Skript für Modelltrainingpreprocess.py - führt Audioverarbeitung durch und erstellt Schulungs- und Validierungsdatensätzeinference.ipynb - Notizbuch zum Ausführen von Inferenz configs enthält __init__.py mit allen für die Schulung und Datenverarbeitung erforderlichen Parametern. configs/experiments bestehen aus allen Experimenten. waveglow.py und tacotron2.py werden als Beispiele für Wellenlow und Tacotron bereitgestellt. Bei Trainings- oder Datenverarbeitungsstart werden Parameter aus Ihrem Experiment (in unserem Fall - von waveglow.py oder von tacotron2.py ) bis __init__.py kopiert.
wavs -Ordner und metadata.csv -Datei mit dem nächsten Zeilenformat enthalten: file_name.wav|text .configs/experiments/waveglow.py oder in configs/experiments/tacotron2.py in der PreprocessingConfig eingestellt werden.start_from_preprocessed Flag auf False . preprocess.py führt die Trimmen von Audio -Dateien bis zur PreprocessingConfig.top_db durch (schneidet die Stille am Anfang und am Ende), wendet FFMPEG -Befehl an, um mono zu mono, und erstellen Sie die gleiche Abtastrate und die Bitrate für alle Wellen im Datensatz.wavs mit verarbeiteten Audio -Dateien und data.csv -Datei in PreprocessingConfig.output_directory mit dem folgenden Format: path|text|speaker_name|speaker_id|emotion|text_len|duration .process_audio wahr ist. Sprecher mit Flagge emotion_present sind falsch und werden wie bei neutral-normal behandelt.start_from_preprocessed = False benötigen, wenn Sie das raufende Vorverarbeitungsskript fertiggestellt haben. Nur eine Ausnahme bei neuen Rohdaten kommt ins Spiel.start_from_preprocessed auf true eingestellt ist, lädt Skript data.csv (erstellt von start_from_preprocessed = False run) und forms train.txt und val.txt aus data.csv .PreprocessingConfig :cpus - definiert die Anzahl der Kerne für den Stapelgeneratorsr - Definiert ein Beispielverhältnis zum Lesen und Schreiben von Audioemo_id_map - Wörterbuch für den Emotionsnamen zum Emotion_ID -Zuordnungdata[{'path'}] - ist Pfad zum Ordner, der mit dem Sprechernamen benannt ist und wavs -Ordner und metadata.csv mit dem folgenden Zeilenformat enthält: file_name.wav|text|emotion (optional)PreprocessingConfig.limit_by der Lautsprechervorverarbeitung.PreprocessingConfig.text_limit und PreprocessingConfig.dur_limit aus. Die untere Grenze für Audio wird durch PreprocessingConfig.minimum_viable_dur definiert.PreprocessingConfig.text_limit auf linda_jonson fest.text_limittrain : val = 0.95 : 0.05n größer ist als PreprocessingConfig.ntrain.txt und val.txt in PreprocessingConfig.output_directoryemotion_coefficients.json und speaker_coefficients.json mit Koeffizienten für den Verlustausgleich (von train.py ). Da beide Skripte waveglow.py und tacotron2.py den PreprocessingConfig enthalten, können das Trainings- und Validierungsdatensatz durch Ausführen eines von ihnen erstellt werden:
python preprocess.py --exp tacotron2
oder
python preprocess.py --exp waveglow
In configs/experiment/tacotron2.py im Config :
training_files und validation_files - Pfade zu train.txt , val.txt ;tacotron_checkpoint - Pfad zu Tacotron 2, wenn es vorhanden ist (wir konnten den Wellenlow von Nvidia wiederherstellen, aber der Tacotron 2 -Code wurde bearbeitet, um Lautsprecher und Emotionen hinzuzufügen, sodass Tacotron 2 von Grund auf neu trainiert werden muss);speaker_coefficients - Pfad zu speaker_coefficients.json ;emotion_coefficients - Pfad zu emotion_coefficients.json ;output_directory - Pfad zum Schreiben von Protokollen und Kontrollpunkten;use_emotions - Flag, die die Verwendung von Emotionen angibt;use_loss_coefficients - Flag, das die Verlustskalierung aufgrund eines möglichen Datenimalance in Bezug auf Sprecher und Emotionen angibt; Setzen Sie zum Ausgleich von Verlusten Wege zu Jsons mit Koeffizienten in emotion_coefficients und speaker_coefficients ;model_name - "Tacotron2" . python train.py --exp tacotron2
python -m multiproc train.py --exp tacotron2
In configs/experiment/waveglow.py im Config :
training_files und validation_files - Pfade zu train.txt , val.txt ;waveglow_checkpoint - Pfad zum vorgenannten Wellenlow, restauriert von Nvidia. Checkopoint herunterladen.output_directory - Pfad zum Schreiben von Protokollen und Kontrollpunkten;use_emotions - false ;use_loss_coefficients - false ;model_name - "WaveGlow" . python train.py --exp waveglow
python -m multiproc train.py --exp waveglow
Sobald Ihr Modell mit dem Training beginnt, möchten Sie vielleicht einige Fortschritte beim Training sehen:
docker ps
Wählen Sie Container -ID des Bildes mit Tag taco aus und rennen Sie:
docker exec -it container_id bash
Tensorboard starten:
tensorboard --logdir=path_to_folder_with_logs --host=0.0.0.0
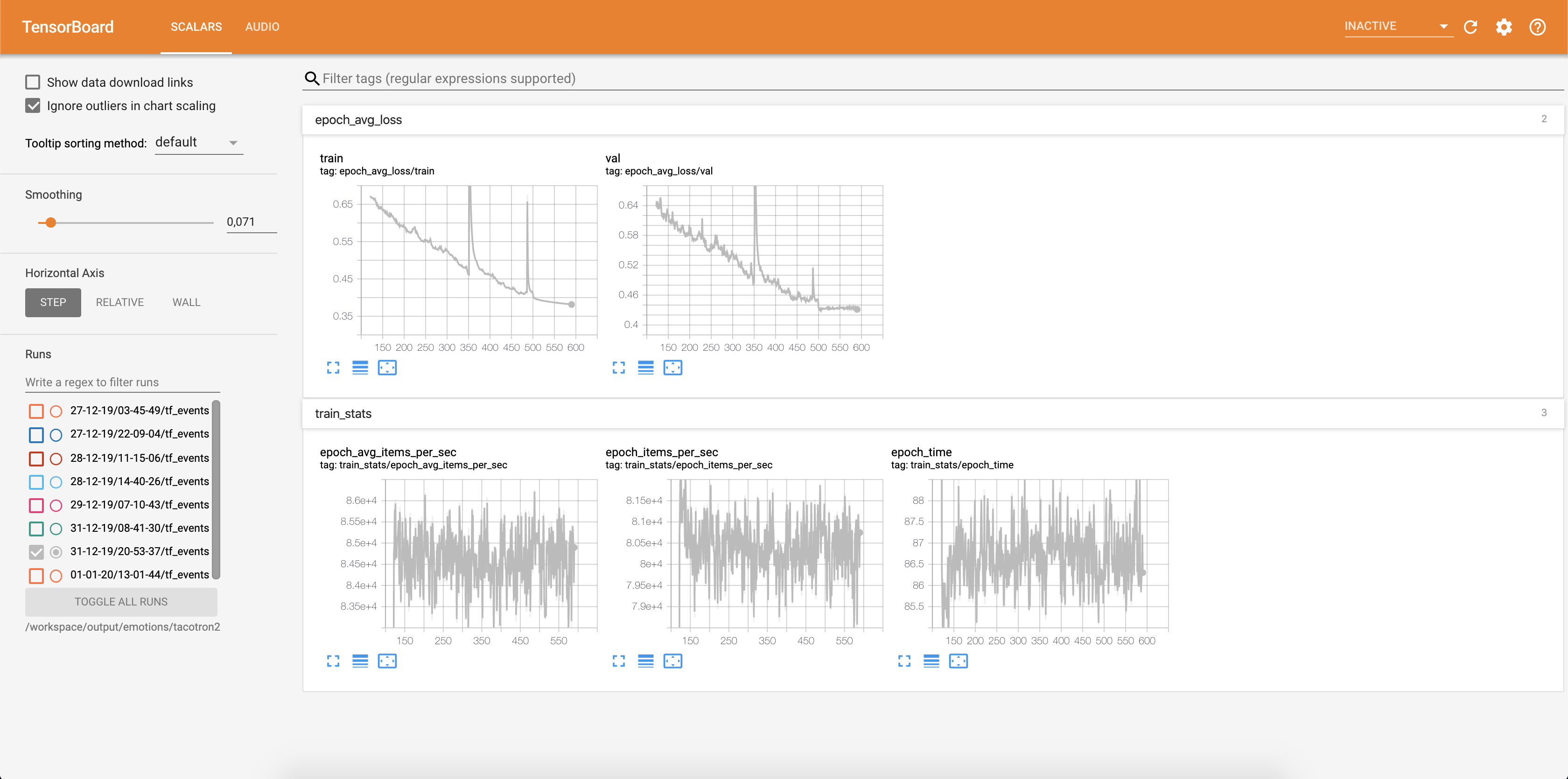
Der Verlust wird in Tensorboard geschrieben:
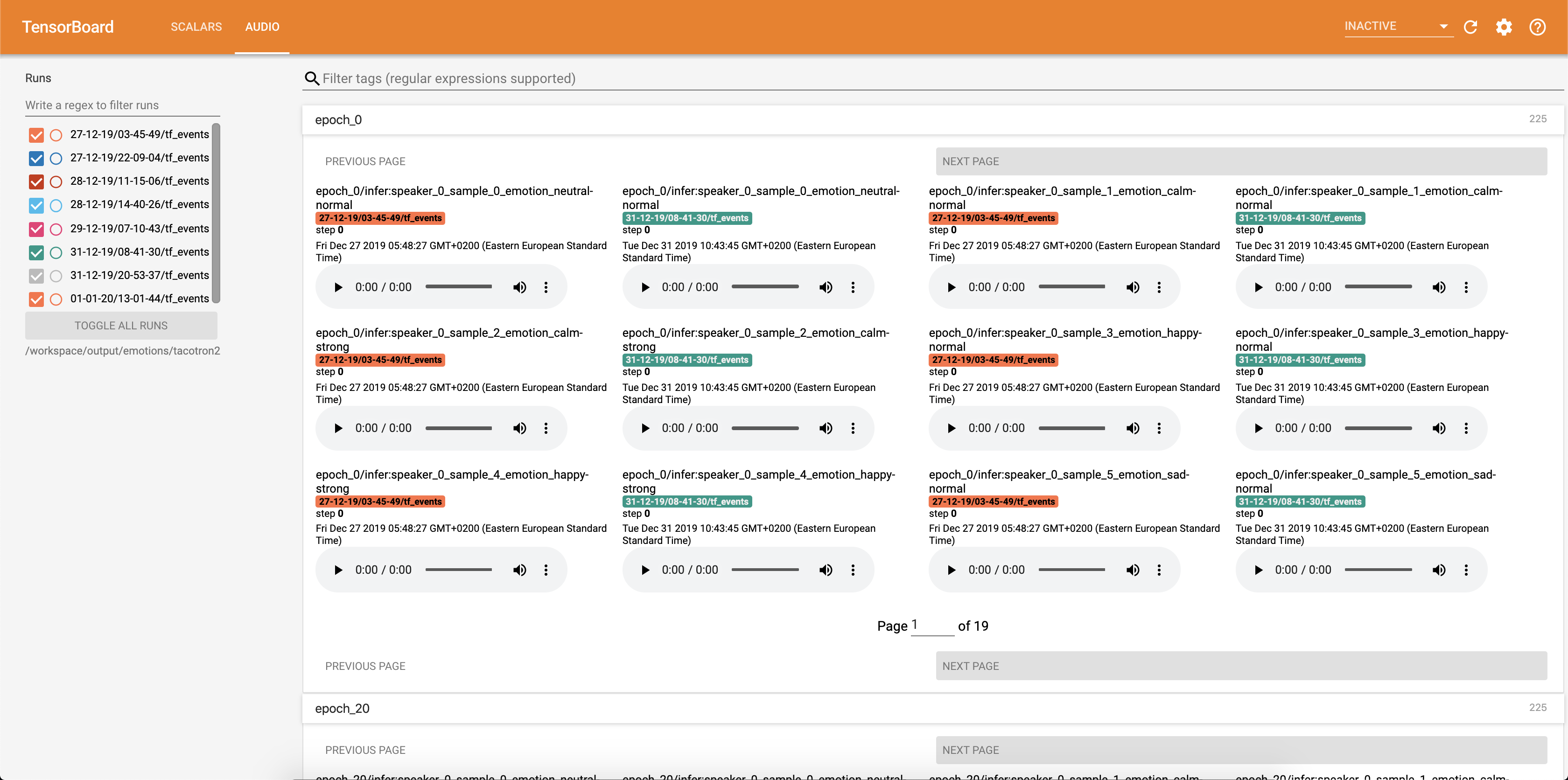
Audio -Samples zusammen mit Aufmerksamkeitsausrichtungen werden in TensorBaord jede Config.epochs_per_checkpoint gespeichert. Transkripte für Audios sind in Config.phrases aufgeführt
Ausführen von Inferenz mit dem Notebook inference.ipynb .
Jupyter Notebook ausführen:
jupyter notebook --ip 0.0.0.0 --port 6006 --no-browser --allow-root
Ausgabe:
root@04096a19c266:/app# jupyter notebook --ip 0.0.0.0 --port 6006 --no-browser --allow-root
[I 09:31:25.393 NotebookApp] JupyterLab extension loaded from /opt/conda/lib/python3.6/site-packages/jupyterlab
[I 09:31:25.393 NotebookApp] JupyterLab application directory is /opt/conda/share/jupyter/lab
[I 09:31:25.395 NotebookApp] Serving notebooks from local directory: /app
[I 09:31:25.395 NotebookApp] The Jupyter Notebook is running at:
[I 09:31:25.395 NotebookApp] http://(04096a19c266 or 127.0.0.1):6006/?token=bbd413aef225c1394be3b9de144242075e651bea937eecce
[I 09:31:25.395 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 09:31:25.398 NotebookApp]
To access the notebook, open this file in a browser:
file:///root/.local/share/jupyter/runtime/nbserver-15398-open.html
Or copy and paste one of these URLs:
http://(04096a19c266 or 127.0.0.1):6006/?token=bbd413aef225c1394be3b9de144242075e651bea937eecce
Wählen Sie Adress mit 127.0.0.1 und legen Sie es in den Browser. In diesem Fall: http://127.0.0.1:6006/?token=bbd413aef225c1394be3b9de144242075e651bea937eecce
Dieses Skript nimmt Text als Eingabe an und führt Tacotron 2 und dann Wellenlow -Inferenz aus, um eine Audio -Datei zu erstellen. Vorausgebildete Checkpoints aus Tacotron 2- und WaveGlow-Modellen, Eingabetxt, Lautsprecher_ID und Emotion_ID.
Wechseln Sie Pfade zu Checkpoints von vorbereiteten Tacotron 2 und Wellenlow in der Zelle [2] der inference.ipynb .
Schreiben Sie einen Text, der in der Zelle [7] der inference.ipynb angezeigt wird.
In diesem Abschnitt listen wir die wichtigsten Hyperparameter zusammen mit ihren Standardwerten auf, die zum Trainieren von Tacotron 2- und Wellenlow -Modellen verwendet werden.
epochs - Anzahl der Epochen (Tacotron 2: 1501, Wellenlow: 1001)learning-rate -Lernrate (Tacotron 2: 1E-3, Wellenlow: 1E-4)batch-size - Stapelgröße (Tacotron 2: 64, Wellenlow: 11)grad_clip_thresh - Gradient Clipping Treshold (0,1)sampling-rate - Abtastrate in Hz von Eingangs- und Ausgangs -Audio (22050)filter-length - (1024)hop-length - Hopfenlänge für FFT, dh Probenschritt zwischen aufeinanderfolgenden FFTs (256)win-length - Fenstergröße für FFT (1024)mel-fmin - niedrigste Frequenz bei Hz (0,0)mel-fmax - höchste Frequenz in Hz (8.000)anneal-steps - Epochen, mit denen die Lernrate (500/1000/1500) angelehnt werden kannanneal-factor -Faktor, mit dem die Lernrate (0,1) diese beiden Parameter an den Lernrate an den in anneal-steps definierten Punkten gemäß:learning_rate = learning_rate * ( anneal_factor ** p) ,p = 0 im ersten Schritt und in jedem Schritt um 1 in Schritte auferlegt wird.segment-length - Segmentlänge des vom neuronalen Netzwerks verarbeiteten Eingangs -Audio (8000). Vor dem Übergeben an Eingabe wird Audio auf segment-length gepolstert oder beschnitten.wn_config - Wörterbuch mit Parametern der affinen Kopplungsschichten. Enthält n_layers , n_chanels , kernel_size . Wenn Sie schon immer zu Open Source beitragen wollten und eine großartige Sache ist, ist jetzt Ihre Chance!
Weitere Informationen finden Sie in den beitragenden Dokumenten


