tacotron2
1.0.0
Этот репозиторий содержит пример кода для Tacotron 2, волновой хлопки с несколькими динамиками, эмоциональными встраиваниями вместе со сценарием для предварительной обработки данных.
Контрольные точки и код происходят из следующих источников:
configs/experiments В следующем разделе перечислены требования, чтобы начать обучение моделей Tacotron 2 и WaveGlow.
Клонировать репозиторий:
git clone https://github.com/ide8/tacotron2
cd tacotron2
PROJDIR= $( pwd )
export PYTHONPATH= $PROJDIR : $PYTHONPATHЭтот репозиторий содержит DockerFile, который расширяет контейнер Pytorch NGC и инкапсулирует некоторые зависимости. Помимо этих зависимостей, убедитесь, что у вас есть следующие компоненты:
Создайте изображение из файла Docker:
docker build --tag taco .Запустите контейнер Docker:
docker run --shm-size=8G --runtime=nvidia -v /absolute/path/to/your/code:/app -v /absolute/path/to/your/training_data:/mnt/train -v /absolute/path/to/your/logs:/mnt/logs -v /absolute/path/to/your/raw-data:/mnt/raw-data -v /absolute/path/to/your/pretrained-checkpoint:/mnt/pretrained -detach taco sleep infПроверьте идентификатор контейнера:
docker ps Выберите идентификатор контейнера изображения с тегом taco и войдите в контейнер с:
docker exec -it container_id bash
Папки tacotron2 и waveglow имеют сценарии для Tacotron 2, модели волн и состоят из:
<model_name>/model.py - Архитектура модели<model_name>/data_function.py - Функции загрузки данных<model_name>/loss_function.py - функция потери common папка содержит общие слои для обеих моделей ( common/layers.py ), UTILS ( common/utils.py ) и аудио -обработку ( common/audio_processing.py и common/stft.py ).
router папки используется сценарием обучения для выбора подходящей модели
В корневом каталоге:
train.py - сценарий для обучения моделиpreprocess.py - выполняет обработку аудио и создает наборы данных обучения и валидацииinference.ipynb - записная книжка для выполнения вывода configs папок содержит __init__.py со всеми параметрами, необходимыми для обучения и обработки данных. configs/experiments папок состоит из всех экспериментов. waveglow.py и tacotron2.py представлены в качестве примеров для волнового хлопка и такотрона. При начале обучения или обработки данных параметры копируются из вашего эксперимента (в нашем случае - от waveglow.py или от tacotron2.py ) до __init__.py , из которого они используются системой.
wavs и файл metadata.csv с форматом следующей строки: file_name.wav|text .configs/experiments/waveglow.py или в configs/experiments/tacotron2.py , в классе PreprocessingConfig .start_from_preprocessed flag на false . preprocess.py выполняет обрезку аудиофайлов до PreprocessingConfig.top_db (сокращает молчание в начале и в конце), применяет команду ffmpeg, чтобы моно, создать одинаковую скорость выборки и скорость битов для всех волн в наборе данных.wavs с обработанными аудиофайлами и файлом data.csv в PreprocessingConfig.output_directory с следующим форматом: path|text|speaker_name|speaker_id|emotion|text_len|duration .process_audio верно . Динамики с Flag emotion_present ложны , рассматриваются как с эмоциями neutral-normal .start_from_preprocessed = False как только вы закончите запуск сценария предварительной обработки. Только исключение в случае новых необработанных данных.start_from_preprocessed устанавливается на true , Script загружает файл data.csv (созданный start_from_preprocessed = False Run) и Forms train.txt и val.txt Out из data.csv .PreprocessingConfig :cpus - определяет количество ядер для генератора партииsr - определяет соотношение выборки для чтения и написания звукаemo_id_map - Словарь для эмоциональных именdata[{'path'}] - IS Path to Polder с именем с именем динамика и содержащей папку wavs и metadata.csv с следующим форматом строки: file_name.wav|text|emotion (optional)PreprocessingConfig.limit_by (этот шаг необходим для правильного размера партии)PreprocessingConfig.text_limit и PreprocessingConfig.dur_limit . Нижний предел для аудио определяется PreprocessingConfig.minimum_viable_durPreprocessingConfig.text_limit linda_jonsontrain : val = 0.95 : 0.05PreprocessingConfig.n - Образцы n Rowtrain.txt и val.txt в PreprocessingConfig.output_directoryemotion_coefficients.json и speaker_coefficients.json с коэффициентами для балансировки потерь (используется train.py ). Поскольку оба сценария waveglow.py и tacotron2.py содержат класс PreprocessingConfig , набор данных обучения и валидации может быть создан путем запуска любого из них:
python preprocess.py --exp tacotron2
или
python preprocess.py --exp waveglow
В configs/experiment/tacotron2.py , в наборе Config класса:
training_files и validation_files - paths to train.txt , val.txt ;tacotron_checkpoint - Путь к предварительному такотрону 2, если он существует (мы смогли восстановить волновой хлопот из nvidia, но код Tacotron 2 был отредактирован для добавления динамиков и эмоций, поэтому Tacotron 2 должен быть обучен с нуля);speaker_coefficients - Path to speaker_coefficients.json ;emotion_coefficients - Путь к emotion_coefficients.json ;output_directory - Путь для записи журналов и контрольных точек;use_emotions - флаг, указывающий на использование эмоций;use_loss_coefficients - флаг, указывающий на масштабирование потерь из -за возможного расстройства данных с точки зрения как динамиков, так и эмоций; Для балансировки потерь установите пути к JSons с коэффициентами в emotion_coefficients и speaker_coefficients ;model_name - "Tacotron2" . python train.py --exp tacotron2
python -m multiproc train.py --exp tacotron2
В configs/experiment/waveglow.py , в наборе Config класса:
training_files и validation_files - paths to train.txt , val.txt ;waveglow_checkpoint - Путь к предварительному волновому связу, восстановленный из nvidia. Скачать Pectopoint.output_directory - Путь для записи журналов и контрольных точек;use_emotions - false ;use_loss_coefficients - false ;model_name - "WaveGlow" . python train.py --exp waveglow
python -m multiproc train.py --exp waveglow
После того, как вы начали обучение модели, вы можете увидеть некоторый прогресс в обучении:
docker ps
Выберите идентификатор контейнера изображения с тегом taco и запустите:
docker exec -it container_id bash
Начните Tensorboard:
tensorboard --logdir=path_to_folder_with_logs --host=0.0.0.0
Потеря записывается в Tensorboard:
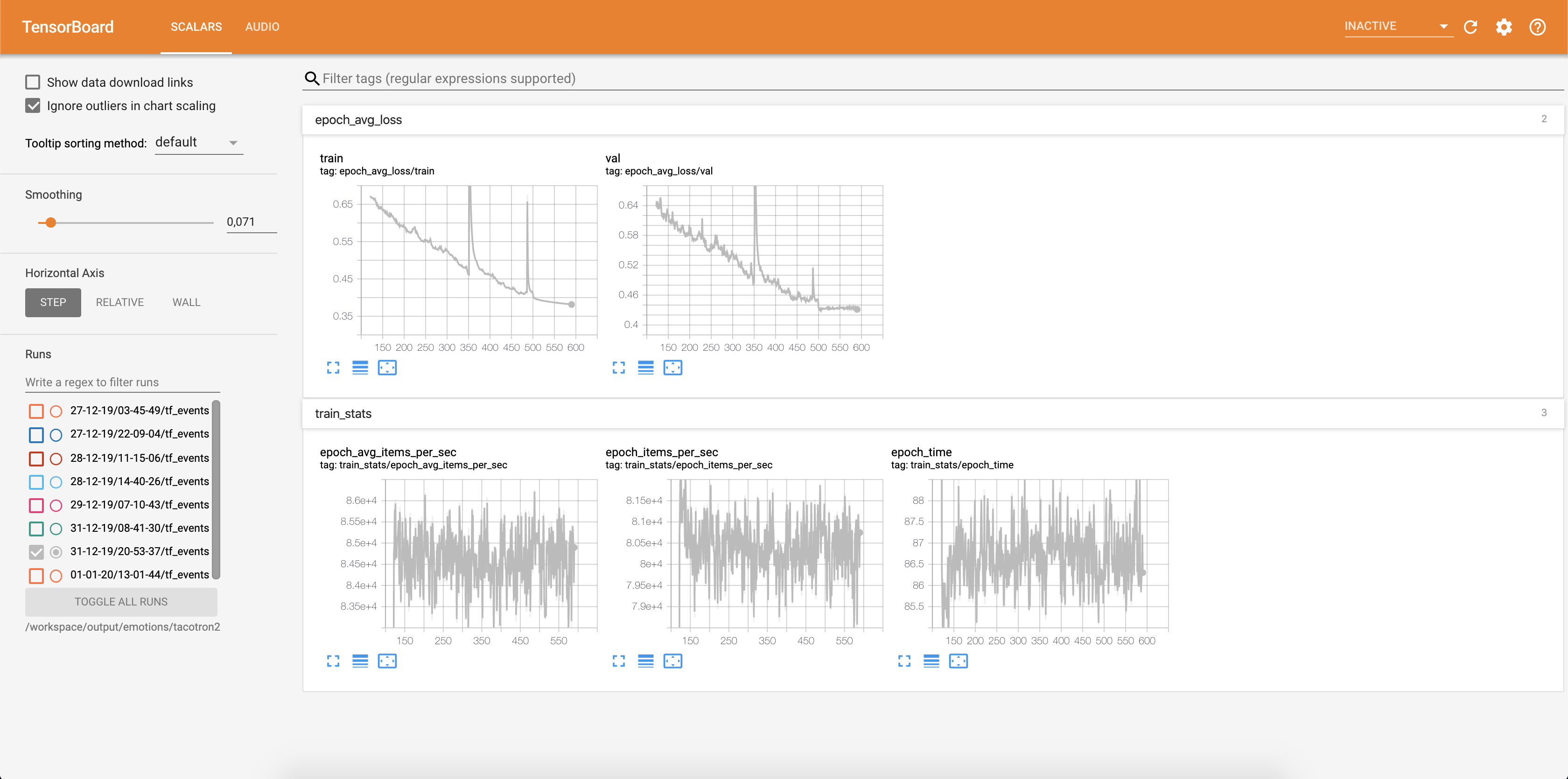
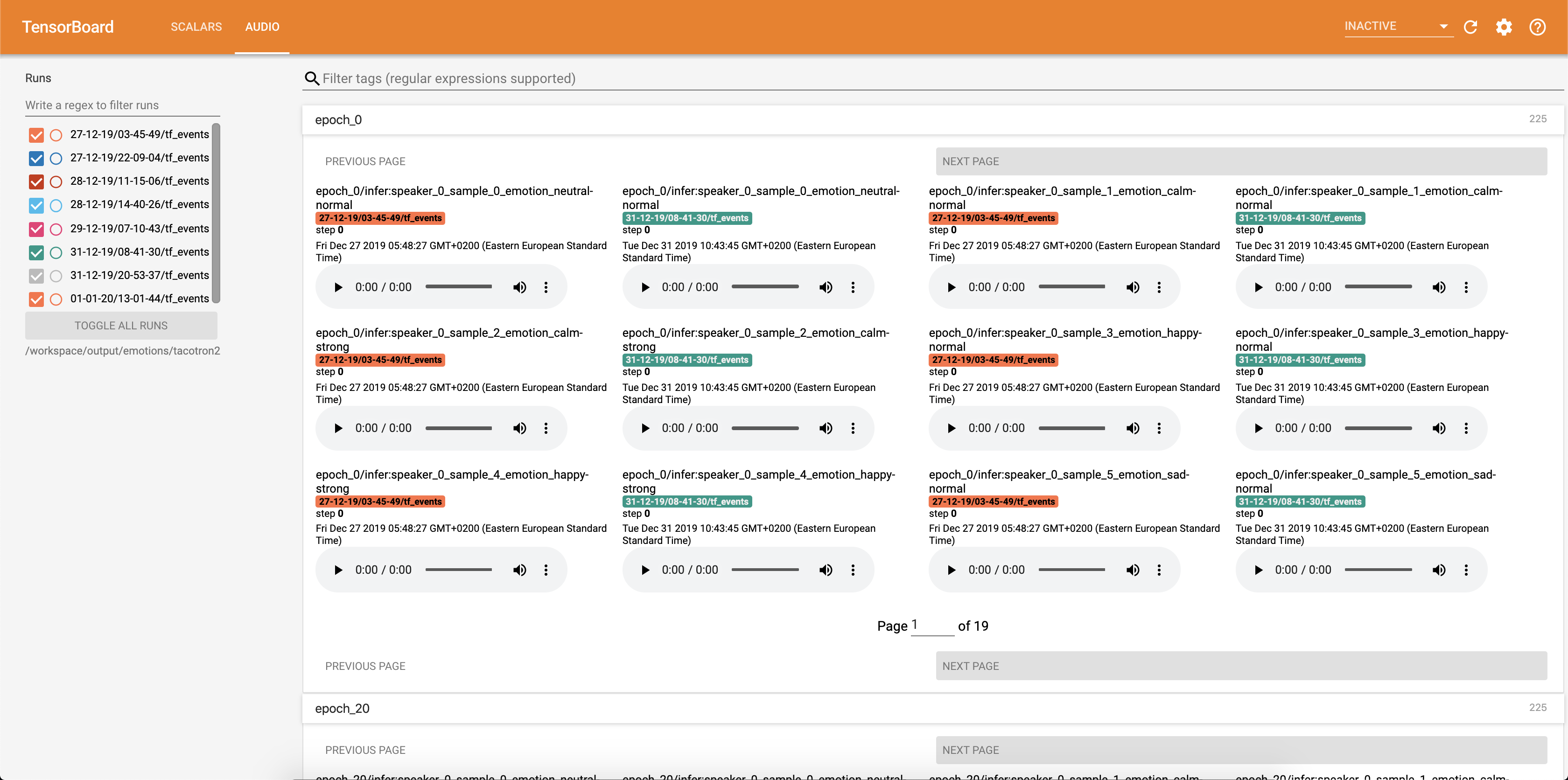
Образцы аудио вместе с выравниванием внимания сохраняются в Tensorbaord каждый Config.epochs_per_checkpoint . Стенограммы для аудио перечислены в Config.phrases
Запуск вывода с inference.ipynb .
Запустите записную книжку Jupyter:
jupyter notebook --ip 0.0.0.0 --port 6006 --no-browser --allow-root
выход:
root@04096a19c266:/app# jupyter notebook --ip 0.0.0.0 --port 6006 --no-browser --allow-root
[I 09:31:25.393 NotebookApp] JupyterLab extension loaded from /opt/conda/lib/python3.6/site-packages/jupyterlab
[I 09:31:25.393 NotebookApp] JupyterLab application directory is /opt/conda/share/jupyter/lab
[I 09:31:25.395 NotebookApp] Serving notebooks from local directory: /app
[I 09:31:25.395 NotebookApp] The Jupyter Notebook is running at:
[I 09:31:25.395 NotebookApp] http://(04096a19c266 or 127.0.0.1):6006/?token=bbd413aef225c1394be3b9de144242075e651bea937eecce
[I 09:31:25.395 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 09:31:25.398 NotebookApp]
To access the notebook, open this file in a browser:
file:///root/.local/share/jupyter/runtime/nbserver-15398-open.html
Or copy and paste one of these URLs:
http://(04096a19c266 or 127.0.0.1):6006/?token=bbd413aef225c1394be3b9de144242075e651bea937eecce
Выберите Adress с 127.0.0.1 и поместите его в браузер. В этом случае: http://127.0.0.1:6006/?token=bbd413aef225c1394be3b9de144242075e651bea937eecce
Этот скрипт принимает текст в качестве ввода и запускает Tacotron 2, а затем вывод волнового хлопка для создания аудиофайла. Это требует предварительно обученных контрольных точек из моделей Tacotron 2 и волновых хлопков, входного текста, Speaker_id и Emotion_id.
Изменить пути на контрольно -пропускные пункты предварительно проведенного такотрона 2 и волнового потока в ячейке [2] inference.ipynb . Ipynb.
Напишите текст, который будет отображаться в ячейке [7] inference.ipynb .
В этом разделе мы перечислим наиболее важные гиперпараметры, а также их значения по умолчанию, которые используются для обучения моделей Tacotron 2 и волновых дней.
epochs - Количество эпох (Такотрон 2: 1501, волновой стеклян: 1001)learning-rate -скорость обучения (Tacotron 2: 1E-3, волновой хлопьев: 1E-4)batch-size - размер партии (Такотрон 2: 64, Волновой встрече: 11)grad_clip_thresh - Градиент обрезание TRESHOLD (0,1)sampling-rate - скорость выборки в Гц входного и выходного аудио (22050)filter-length - (1024)hop-length - длина прыжков для БПФ, т.е.win-length - размер окна для БПФ (1024)mel-fmin - самая низкая частота в Гц (0,0)mel-fmax - самая высокая частота в Гц (8.000)anneal-steps - эпохи, в которых можно отжигать скорость обучения (500/1000/1500)anneal-factor -фактор, с помощью которого отжиг скорость обучения (0,1) Эти два параметра используются для изменения скорости обучения в точках, определенных в anneal-steps согласно:learning_rate = learning_rate * ( anneal_factor ** p) ,p = 0 на первом этапе и приращения на 1 каждый шаг.segment-length - длина сегмента входного аудио, обработанного нейронной сетью (8000). Перед перемещением на вход звук прокладывается или обрезан до segment-length .wn_config - Словарь с параметрами слоев аффинной связи. Содержит n_layers , n_chanels , kernel_size . Если вы когда -либо хотели внести свой вклад в открытый исходный код, и отличное дело, сейчас ваш шанс!
См. Документы, предназначенные для получения дополнительной информации


