tacotron2
1.0.0
Repositori ini berisi kode sampel untuk Tacotron 2, Waveglow dengan multi-speaker, Emosi Embeddings bersama dengan skrip untuk preprocessing data.
Pos pemeriksaan dan kode berasal dari sumber berikut:
configs/experiments Bagian berikut mencantumkan persyaratan untuk mulai melatih model Tacotron 2 dan Waveglow.
Klon Repositori:
git clone https://github.com/ide8/tacotron2
cd tacotron2
PROJDIR= $( pwd )
export PYTHONPATH= $PROJDIR : $PYTHONPATHRepositori ini berisi DockerFile yang memperluas wadah Pytorch NGC dan merangkum beberapa dependensi. Selain ketergantungan ini, pastikan Anda memiliki komponen berikut:
Bangun gambar dari file Docker:
docker build --tag taco .Jalankan Docker Container:
docker run --shm-size=8G --runtime=nvidia -v /absolute/path/to/your/code:/app -v /absolute/path/to/your/training_data:/mnt/train -v /absolute/path/to/your/logs:/mnt/logs -v /absolute/path/to/your/raw-data:/mnt/raw-data -v /absolute/path/to/your/pretrained-checkpoint:/mnt/pretrained -detach taco sleep infPeriksa ID Kontainer:
docker ps Pilih ID Kontainer Gambar dengan Tag taco dan masuk ke dalam wadah dengan:
docker exec -it container_id bash
Folder tacotron2 dan waveglow memiliki skrip untuk Tacotron 2, model Waveglow dan terdiri dari:
<model_name>/model.py - Arsitektur Model<model_name>/data_function.py - Fungsi pemuatan data<model_name>/loss_function.py - fungsi kerugian Folder common berisi lapisan umum untuk kedua model ( common/layers.py ), utils ( common/utils.py ) dan pemrosesan audio ( common/audio_processing.py dan common/stft.py ).
router folder digunakan dengan skrip pelatihan untuk memilih model yang sesuai
Di direktori root:
train.py - skrip untuk pelatihan modelpreprocess.py - melakukan pemrosesan audio dan membuat kumpulan data pelatihan dan validasiinference.ipynb - notebook untuk menjalankan inferensi configs folder berisi __init__.py dengan semua parameter yang diperlukan untuk pelatihan dan pemrosesan data. configs/experiments folder terdiri dari semua percobaan. waveglow.py dan tacotron2.py disediakan sebagai contoh untuk Waveglow dan Tacotron 2. Pada pelatihan atau pemrosesan data mulai, parameter disalin dari percobaan Anda (dalam kasus kami - dari waveglow.py atau dari tacotron2.py ) ke __init__.py , dari mana mereka digunakan oleh sistem.
wavs dan file metadata.csv dengan format baris berikutnya: file_name.wav|text .configs/experiments/waveglow.py atau dalam configs/experiments/tacotron2.py , di kelas PreprocessingConfig .start_from_preprocessed flag menjadi false . preprocess.py melakukan pemangkasan file audio hingga PreprocessingConfig.top_db (memotong keheningan di awal dan akhir), menerapkan perintah ffmpeg untuk mono, buat laju pengambilan sampel yang sama dan laju bit untuk semua gelombang dalam dataset.wavs dengan file audio yang diproses dan file data.csv di PreprocessingConfig.output_directory dengan format berikut: path|text|speaker_name|speaker_id|emotion|text_len|duration .process_audio benar . Pembicara dengan bendera emotion_present adalah salah , diperlakukan seperti emosi neutral-normal .start_from_preprocessed = False setelah Anda selesai menjalankan skrip preprocessing. Hanya pengecualian jika data mentah baru masuk.start_from_preprocessed diatur ke true , skrip memuat data data.csv (dibuat oleh start_from_preprocessed = False run), dan membentuk train.txt dan val.txt out dari data.csv .PreprocessingConfig utama:cpus - Menentukan jumlah core untuk generator batchsr - Menentukan rasio sampel untuk membaca dan menulis audioemo_id_map - kamus untuk nama emosi untuk pemetaan emosi_iddata[{'path'}] - adalah jalur ke folder yang dinamai dengan nama speaker dan berisi folder wavs dan metadata.csv dengan format baris berikut: file_name.wav|text|emotion (optional)PreprocessingConfig.limit_by (langkah ini diperlukan untuk ukuran batch yang tepat)PreprocessingConfig.text_limit dan PreprocessingConfig.dur_limit . Batas bawah untuk audio ditentukan oleh PreprocessingConfig.minimum_viable_durPreprocessingConfig.text_limit ke linda_jonsontrain : val = 0.95 : 0.05PreprocessingConfig.n - sampel n baristrain.txt dan val.txt ke PreprocessingConfig.output_directoryemotion_coefficients.json dan speaker_coefficients.json dengan koefisien untuk penyeimbangan kerugian (digunakan oleh train.py ). Karena kedua skrip waveglow.py dan tacotron2.py berisi kelas PreprocessingConfig , dataset pelatihan dan validasi dapat diproduksi dengan menjalankan salah satu dari mereka:
python preprocess.py --exp tacotron2
atau
python preprocess.py --exp waveglow
Dalam configs/experiment/tacotron2.py , dalam set Config kelas:
training_files dan validation_files - jalur ke train.txt , val.txt ;tacotron_checkpoint - Path to Pretrained Tacotron 2 Jika ada (kami dapat mengembalikan Waveglow dari NVIDIA, tetapi kode Tacotron 2 diedit untuk menambahkan speaker dan emosi, sehingga Tacotron 2 perlu dilatih dari awal);speaker_coefficients - jalur ke speaker_coefficients.json ;emotion_coefficients - Path to emotion_coefficients.json ;output_directory - jalur untuk menulis log dan pos pemeriksaan;use_emotions - bendera yang menunjukkan penggunaan emosi;use_loss_coefficients - Bendera yang menunjukkan penskalaan kerugian karena kemungkinan dissewaan data dalam hal pembicara dan emosi; Untuk menyeimbangkan kehilangan, atur jalur ke JSONS dengan koefisien di emotion_coefficients dan speaker_coefficients ;model_name - "Tacotron2" . python train.py --exp tacotron2
python -m multiproc train.py --exp tacotron2
Dalam configs/experiment/waveglow.py , di set Class Config :
training_files dan validation_files - jalur ke train.txt , val.txt ;waveglow_checkpoint - Path to Pretrained Waveglow, dipulihkan dari NVIDIA. Unduh CHECKOPOINT.output_directory - jalur untuk menulis log dan pos pemeriksaan;use_emotions - false ;use_loss_coefficients - false ;model_name - "WaveGlow" . python train.py --exp waveglow
python -m multiproc train.py --exp waveglow
Setelah Anda membuat model Anda memulai pelatihan, Anda mungkin ingin melihat beberapa kemajuan pelatihan:
docker ps
Pilih ID Kontainer Gambar dengan Tag taco dan Jalankan:
docker exec -it container_id bash
Mulai Tensorboard:
tensorboard --logdir=path_to_folder_with_logs --host=0.0.0.0
Kehilangan ditulis ke dalam Tensorboard:
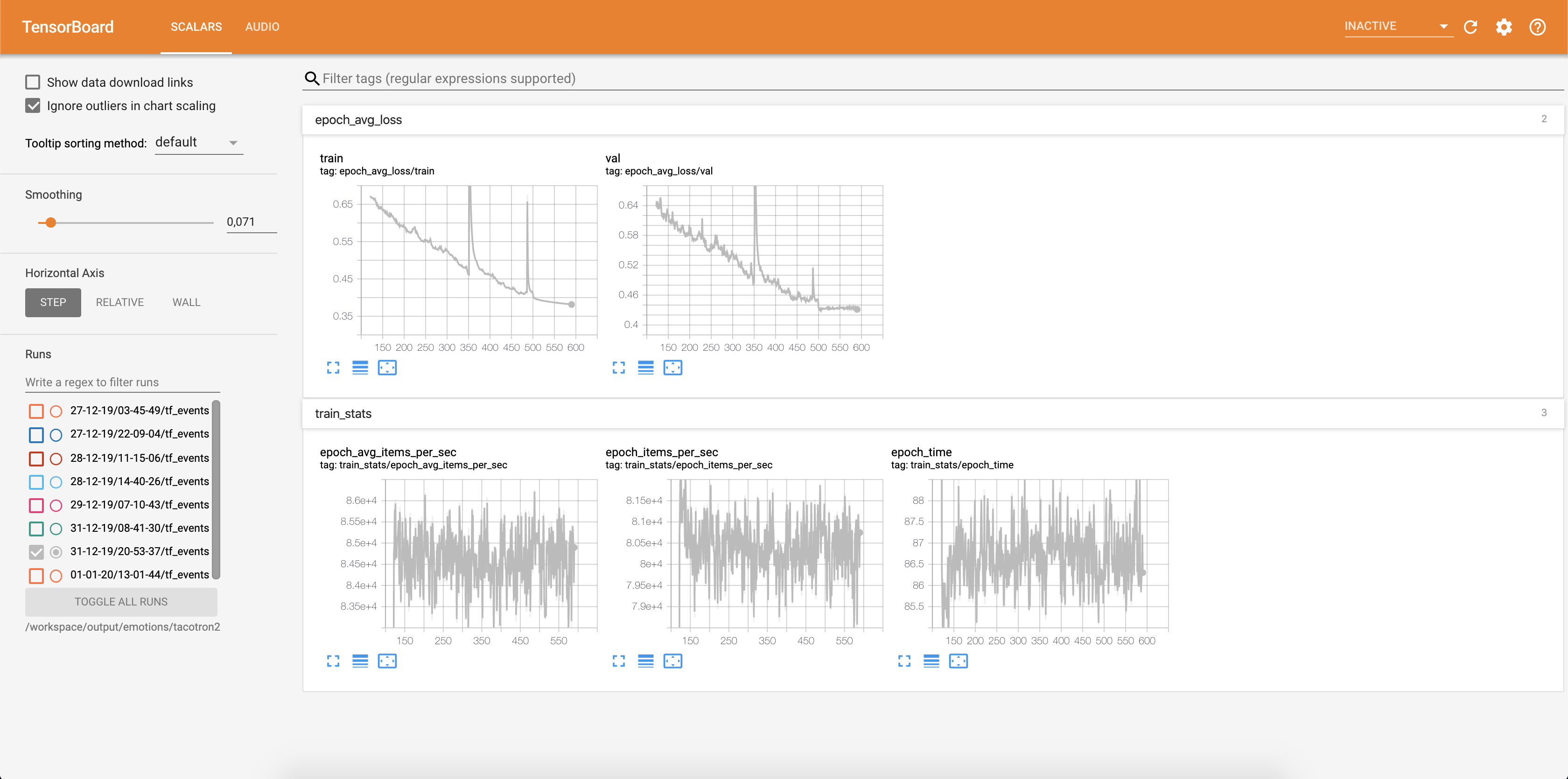
Sampel audio bersama -sama dengan keberpihakan perhatian disimpan ke dalam tensorbaord masing -masing Config.epochs_per_checkpoint . Transkrip untuk audio tercantum dalam Config.phrases
Menjalankan inferensi dengan notebook inference.ipynb .
Jalankan Jupyter Notebook:
jupyter notebook --ip 0.0.0.0 --port 6006 --no-browser --allow-root
keluaran:
root@04096a19c266:/app# jupyter notebook --ip 0.0.0.0 --port 6006 --no-browser --allow-root
[I 09:31:25.393 NotebookApp] JupyterLab extension loaded from /opt/conda/lib/python3.6/site-packages/jupyterlab
[I 09:31:25.393 NotebookApp] JupyterLab application directory is /opt/conda/share/jupyter/lab
[I 09:31:25.395 NotebookApp] Serving notebooks from local directory: /app
[I 09:31:25.395 NotebookApp] The Jupyter Notebook is running at:
[I 09:31:25.395 NotebookApp] http://(04096a19c266 or 127.0.0.1):6006/?token=bbd413aef225c1394be3b9de144242075e651bea937eecce
[I 09:31:25.395 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 09:31:25.398 NotebookApp]
To access the notebook, open this file in a browser:
file:///root/.local/share/jupyter/runtime/nbserver-15398-open.html
Or copy and paste one of these URLs:
http://(04096a19c266 or 127.0.0.1):6006/?token=bbd413aef225c1394be3b9de144242075e651bea937eecce
Pilih Adress dengan 127.0.0.1 dan letakkan di browser. Dalam hal ini: http://127.0.0.1:6006/?token=bbd413aef225c1394be3b9de144242075e651bea937eecce
Script ini mengambil teks sebagai input dan menjalankan Tacotron 2 dan kemudian inferensi Waveglow untuk menghasilkan file audio. Dibutuhkan pos pemeriksaan pra-terlatih dari model Tacotron 2 dan Waveglow, Input Text, Speaker_id dan Emotion_id.
Ubah jalur ke pos pemeriksaan tacotron 2 pretrained dan waveglow di sel [2] dari inference.ipynb .
Tulis teks yang akan ditampilkan di sel [7] dari inference.ipynb .
Di bagian ini, kami mencantumkan hyperparameter terpenting, bersama dengan nilai default mereka yang digunakan untuk melatih model Tacotron 2 dan Waveglow.
epochs - Jumlah Zaman (Tacotron 2: 1501, Waveglow: 1001)learning-rate -Tingkat pembelajaran (Tacotron 2: 1E-3, Waveglow: 1E-4)batch-size - Ukuran Batch (Tacotron 2: 64, Waveglow: 11)grad_clip_thresh - gradien kliping treshold (0,1)sampling-rate - Laju pengambilan sampel dalam HZ audio input dan output (22050)filter-length - (1024)hop-length - Hop Length for FFT, IE, sampel langkah antara FFT berturut -turut (256)win-length - Ukuran jendela untuk FFT (1024)mel-fmin - Frekuensi terendah di Hz (0,0)mel-fmax - frekuensi tertinggi di HZ (8.000)anneal-steps - Epochs untuk menganut tingkat pembelajaran (500/1000/1500)anneal-factor -Faktor yang digunakan untuk Analisis Tingkat Pembelajaran (0,1) Kedua parameter ini digunakan untuk mengubah tingkat pembelajaran pada titik-titik yang ditentukan dalam anneal-steps menurut:learning_rate = learning_rate * ( anneal_factor ** p) ,p = 0 pada langkah pertama dan bertambah dengan 1 setiap langkah.segment-length - Panjang segmen audio input yang diproses oleh jaringan saraf (8000). Sebelum melewati input, audio empuk atau dipangkas ke segment-length .wn_config - Kamus dengan parameter lapisan kopling affine. Berisi n_layers , n_chanels , kernel_size . Jika Anda pernah ingin berkontribusi pada open source, dan tujuan besar, sekarang adalah kesempatan Anda!
Lihat dokumen yang berkontribusi untuk informasi lebih lanjut


