tacotron2
1.0.0
このリポジトリには、Tacotron 2のサンプルコード、マルチスピーカーを備えた波動コード、およびデータプリプセッシング用のスクリプトとともに感情埋め込みが含まれています。
チェックポイントとコードは、次のソースから発生します。
configs/experimentsフォルダーの下の実験構成ファイルに移動する次のセクションには、タコトロン2と波動モデルのトレーニングを開始するための要件を示します。
リポジトリをクローンします:
git clone https://github.com/ide8/tacotron2
cd tacotron2
PROJDIR= $( pwd )
export PYTHONPATH= $PROJDIR : $PYTHONPATHこのリポジトリには、Pytorch NGCコンテナを拡張し、いくつかの依存関係をカプセル化するDockerFileが含まれています。これらの依存関係は別として、次のコンポーネントがあることを確認してください。
Dockerファイルから画像を作成します。
docker build --tag taco .Dockerコンテナを実行します:
docker run --shm-size=8G --runtime=nvidia -v /absolute/path/to/your/code:/app -v /absolute/path/to/your/training_data:/mnt/train -v /absolute/path/to/your/logs:/mnt/logs -v /absolute/path/to/your/raw-data:/mnt/raw-data -v /absolute/path/to/your/pretrained-checkpoint:/mnt/pretrained -detach taco sleep infコンテナIDを確認してください:
docker ps tacoを使用して画像のコンテナIDを選択し、次のようにコンテナにログインします。
docker exec -it container_id bash
フォルダーtacotron2とwaveglowは、Tacotron 2のスクリプト、WaveGlowモデルがあり、次のことで構成されています。
<model_name>/model.pyモデルアーキテクチャ<model_name>/data_function.pyデータ読み込み関数<model_name>/loss_function.py損失関数フォルダーcommonには、両方のモデル( common/layers.py )、Utils( common/utils.py )、およびAudio Processing( common/audio_processing.pyおよびcommon/stft.py )の共通レイヤーが含まれます。
フォルダrouter 、適切なモデルを選択するためにトレーニングスクリプトによって使用されます
ルートディレクトリ:
train.pyモデルトレーニング用のスクリプトpreprocess.pyオーディオ処理を実行し、トレーニングと検証データセットを作成しますinference.ipynb実行中の推論のためのノートブックフォルダーconfigsトレーニングとデータ処理に必要なすべてのパラメーターを備えた__init__.pyが含まれています。フォルダーのconfigs/experimentsすべての実験で構成されています。 waveglow.pyおよびtacotron2.pyは、WaveglowおよびTacotron 2の例として提供されます。トレーニングまたはデータ処理の開始時に、パラメーターは(この場合はwaveglow.pyまたはtacotron2.pyから) __init__.pyからコピーされます。
wavsフォルダーとmetadata.csvファイルを含む必要があります: file_name.wav|text 。configs/experiments/waveglow.pyまたはconfigs/experiments/tacotron2.py 、クラスPreprocessingConfigで設定する必要があります。start_from_preprocessedフラグをfalseに設定します。 preprocess.py 、 PreprocessingConfig.top_dbまでのオーディオファイルのトリミングを実行し(最初と最後に沈黙をカットします)、FFMPEGコマンドを適用して、データセット内のすべてのWAVの同じサンプリングレートとビットレートを作成します。PreprocessingConfig.output_directoryオーディオファイルとdata.csvファイルをpath|text|speaker_name|speaker_id|emotion|text_len|durationしてフォルダーwavsを保存します。process_audio FFMPEGコマンドは、SPEAKERSにのみ適用されます。旗を持つemotion_presentは虚偽であり、感情neutral-normalであるように扱われます。start_from_preprocessed = Falseは必要ありません。新しい生データの場合のみが登場します。start_from_preprocessed trueに設定されると、スクリプトはファイルdata.csv ( start_from_preprocessed = False runによって作成)をロードし、 data.csvからtrain.txtおよびval.txtを形成します。PreprocessingConfigパラメーター:cpusバッチジェネレーターのコアの数を定義しますsrオーディオを読み書きするためのサンプル比を定義しますemo_id_map感情名の辞書emotion_idマッピングdata[{'path'}] - スピーカー名で名前が付けられ、次の行形式を備えたwavsフォルダーとmetadata.csvを含むフォルダーへのパス: file_name.wav|text|emotion (optional)PreprocessingConfig.limit_by長さで行を選択する行を選択します。PreprocessingConfig.text_limitおよびPreprocessingConfig.dur_limit内の行を選択します。オーディオの下限は、 PreprocessingConfig.minimum_viable_durによって定義されますPreprocessingConfig.text_limitをlinda_jonsonに設定しますtrain : val = 0.95 : 0.05PreprocessingConfig.nよりも大きい場合 - n行のサンプルPreprocessingConfig.output_directoryにtrain.txtとval.txtを保存しますemotion_coefficients.jsonとspeaker_coefficients.json train.py保存します。両方のスクリプトwaveglow.pyとtacotron2.pyクラスPreprocessingConfigが含まれているため、トレーニングデータセットと検証データセットは、それらのいずれかを実行することで作成できます。
python preprocess.py --exp tacotron2
または
python preprocess.py --exp waveglow
configs/experiment/tacotron2.py 、クラスConfigセット:
training_files and validation_files -to train.txt 、 val.txtへのパス;tacotron_checkpoint存在する場合は、前処理されたタコトロン2へのパスが存在する場合(nvidiaから波路を復元できましたが、タコトロン2コードを編集してスピーカーと感情を追加するため、タコトロン2をゼロから訓練する必要があります)。speaker_coefficients speaker_coefficients.jsonへのパス;emotion_coefficients emotion_coefficients.jsonへのパス;output_directoryログとチェックポイントを作成するためのパス。use_emotions感情の使用法を示すフラグ。use_loss_coefficientsスピーカーと感情の両方の観点からデータのバランスの可能性による損失スケーリングを示すフラグ。損失のバランスをとるには、 emotion_coefficientsおよびspeaker_coefficientsの係数を持つJsonsへのパスを設定します。model_name "Tacotron2" 。 python train.py --exp tacotron2
python -m multiproc train.py --exp tacotron2
configs/experiment/waveglow.pyで、クラスConfigセット:
training_files and validation_files -to train.txt 、 val.txtへのパス;waveglow_checkpoint nvidiaから復元された、前処理された波動への道。 Checkopointをダウンロードします。output_directoryログとチェックポイントを作成するためのパス。use_emotions -false ;use_loss_coefficients -false ;model_name "WaveGlow" 。 python train.py --exp waveglow
python -m multiproc train.py --exp waveglow
モデルのトレーニングを開始したら、トレーニングの進捗状況を確認する必要があります。
docker ps
タグtacoを使用して画像のコンテナIDを選択し、実行します。
docker exec -it container_id bash
テンソルボードを開始します:
tensorboard --logdir=path_to_folder_with_logs --host=0.0.0.0
損失はテンソルボードに書き込まれています:
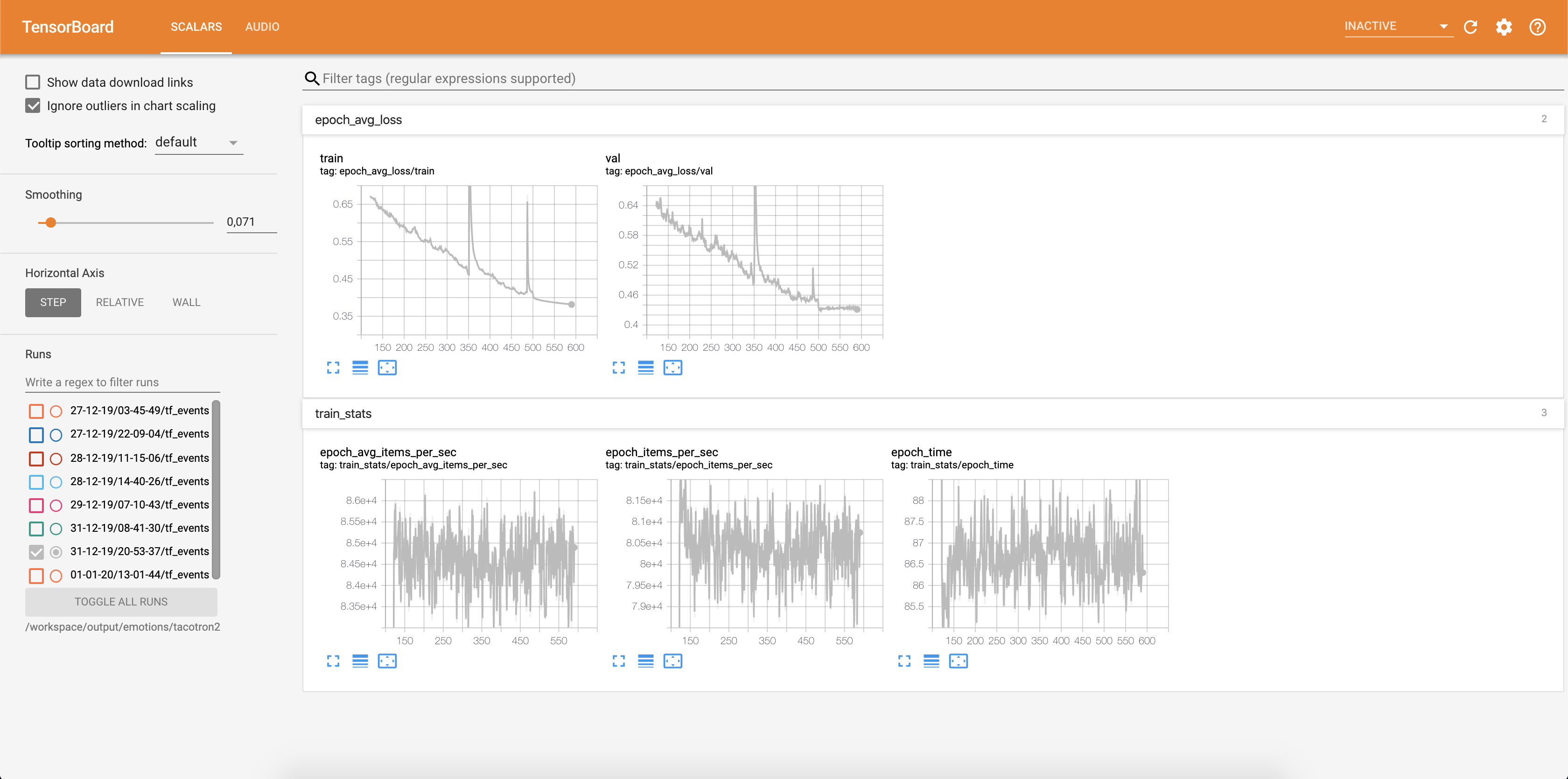
オーディオサンプルと注意アラインメントは、各Config.epochs_per_checkpointの各config.epochs_per_checkpointにTensorbaordに保存されます。オーディオのトランスクリプトは、 Config.phrasesにリストされています
inference.ipynbノートブックを使用して推論を実行します。
Jupyterノートブックを実行:
jupyter notebook --ip 0.0.0.0 --port 6006 --no-browser --allow-root
出力:
root@04096a19c266:/app# jupyter notebook --ip 0.0.0.0 --port 6006 --no-browser --allow-root
[I 09:31:25.393 NotebookApp] JupyterLab extension loaded from /opt/conda/lib/python3.6/site-packages/jupyterlab
[I 09:31:25.393 NotebookApp] JupyterLab application directory is /opt/conda/share/jupyter/lab
[I 09:31:25.395 NotebookApp] Serving notebooks from local directory: /app
[I 09:31:25.395 NotebookApp] The Jupyter Notebook is running at:
[I 09:31:25.395 NotebookApp] http://(04096a19c266 or 127.0.0.1):6006/?token=bbd413aef225c1394be3b9de144242075e651bea937eecce
[I 09:31:25.395 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 09:31:25.398 NotebookApp]
To access the notebook, open this file in a browser:
file:///root/.local/share/jupyter/runtime/nbserver-15398-open.html
Or copy and paste one of these URLs:
http://(04096a19c266 or 127.0.0.1):6006/?token=bbd413aef225c1394be3b9de144242075e651bea937eecce
127.0.0.1でアドレスを選択し、ブラウザに入れます。 http://127.0.0.1:6006/?token=bbd413aef225c1394be3b9de144242075e651bea937eecce
このスクリプトはテキストを入力として受け取り、タコトロン2を実行し、次に波動推論を実行してオーディオファイルを作成します。 Tacotron 2およびWaveGlowモデル、入力テキスト、Speaker_ID、およびEmotion_IDからの事前に訓練されたチェックポイントが必要です。
推定されたタコトロン2のチェックポイントと、 inference.ipynbのセル[2]のチェックポイントにパスを変更します。
inference.ipynbのセル[7]に表示されるテキストを作成します。
このセクションでは、Tacotron 2およびWaveGlowモデルのトレーニングに使用されるデフォルト値とともに、最も重要なハイパーパラメータをリストします。
epochs - エポックの数(タコトロン2:1501、波路:1001)learning-rate - 学習率(タコトロン2:1E-3、波動:1E-4)batch-size - バッチサイズ(タコトロン2:64、波動:11)grad_clip_threshグラデーションクリッピングトレッション(0.1)sampling-rate - 入力および出力オーディオのHzのサンプリングレート(22050)filter-length - (1024)hop-length - FFTのホップ長、つまり、連続したFFTの間のサンプルストライド(256)win-length -FFTのウィンドウサイズ(1024)mel-fmin -Hzで最も低い周波数(0.0)mel-fmax -Hzで最も高い周波数(8.000)anneal-steps - 学習率をアニールするエポック(500/ 1000/1500)anneal-factor anneal-steps学習率をアニールする要因learning_rate = learning_rate * ( anneal_factor ** p) 、p = 0 、各ステップ1の増分。segment-length - ニューラルネットワーク(8000)によって処理された入力オーディオのセグメント長。入力に渡す前に、オーディオはパッド入りまたはsegment-lengthにトリミングされています。wn_configアフィンカップリング層のパラメーターを備えた辞書。 n_layers 、 n_chanels 、 kernel_sizeが含まれます。 オープンソースと大きな理由に貢献したいと思ったことがあるなら、今があなたのチャンスです!
詳細については、貢献ドキュメントを参照してください


