speech adapters
1.0.0
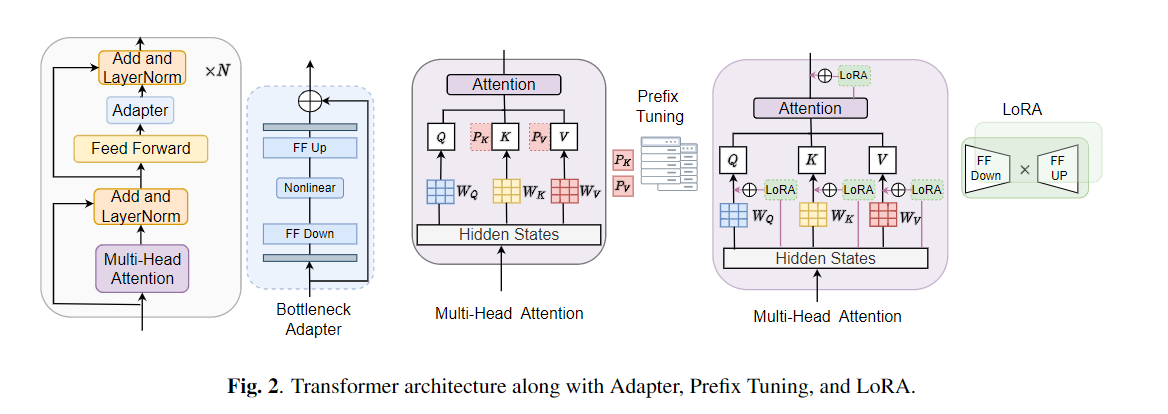
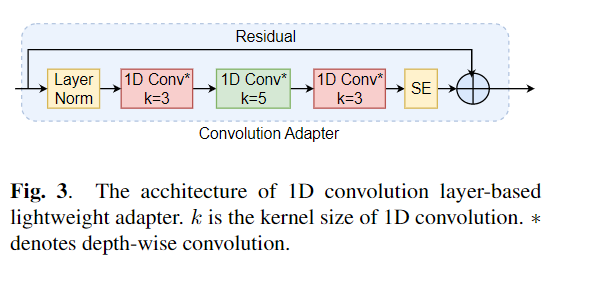
微调被广泛用作从预训练模型转移学习的默认算法。但是,当在传输学习过程中,需要更新大型预训练模型的所有参数,以便为单个下游任务更新大型预训练模型时,可能会出现参数低效率。随着参数数量的增加,微调容易拟合和灾难性遗忘。此外,当模型用于许多任务时,全面的微调可能会变得非常昂贵。为了减轻此问题,已经提出了参数有效的传输学习算法,例如适配器和前缀调整,作为一种引入一些可训练的参数,可以插入大型预训练的语言模型,例如Bert和Hubert。在本文中,我们介绍了语音理解评估(肯定)基准,用于用于各种语音处理任务的参数效率学习。此外,我们根据1D卷积引入了一个新的适配器Resuredapter。我们表明,卷积器的表现优于标准适配器,同时表现出与前缀调整和洛拉的可比性能,而在某些任务上,只有0.94%的可训练参数的0.94%。我们进一步探讨了参数有效传输学习对于语音综合任务(例如文本到语音(TTS))的有效性。
conda create - - name speechprompt python == 3.8 . 5
conda activate speechprompt
conda install pytorch == 1.10 . 0 torchvision == 0.11 . 0 torchaudio == 0.10 . 0 - c pytorch pip install - r requirements . txt 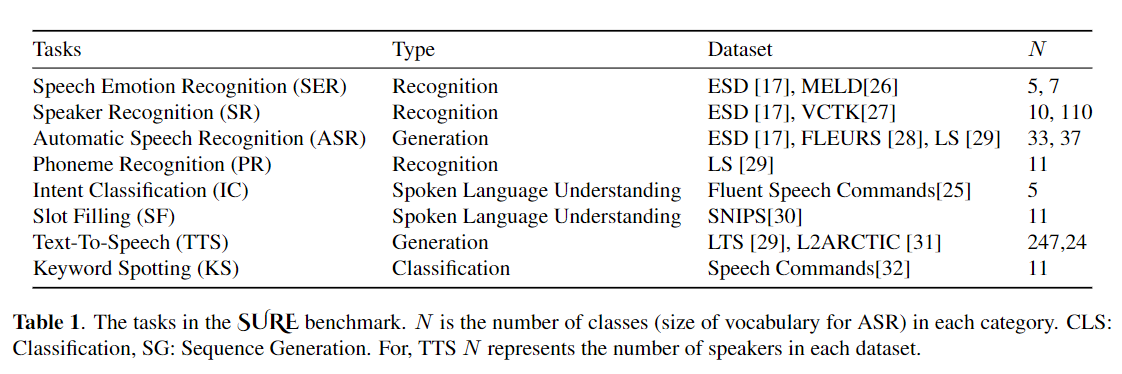
首先,我们需要指定数据集和参数。让我们将“ ESD”用作数据集,“ Finetune”作为“语音情感识别”任务中的调整方法作为一个例子:
CUDA_VISIBLE_DEVICES = 2 , 3 python train . py
- - dataset "esd"
- - data_dir "/data/path/ESD"
- - output_dir '/data/path/output_earlystop_ser_esd_finetune_2e3'
- - do_train True
- - do_eval True
- - do_predict False
- - evaluation_strategy "steps"
- - save_strategy "steps"
- - save_steps 500
- - eval_steps 25
- - learning_rate 2e-3
- - feat_adapter_name "conv_adapter"
- - trans_adapter_name "adapterblock"
- - output_adapter False
- - mh_adapter False
- - prefix_tuning False
- - lora_adapter False
- - feat_enc_adapter False
- - fine_tune True
- - per_device_train_batch_size 64
- - gradient_accumulation_steps 4
- - per_device_eval_batch_size 64
- - num_train_epochs 100
- - warmup_ratio 0.1
- - logging_steps 20
- - logging_dir '/data/path/output_earlystop_ser_esd_finetune_2e3/log'
- - load_best_model_at_end True
- - metric_for_best_model "f1" 让我们进一步解释模型的五种训练方法。例如,启动新的情感分类任务,我们将设置相应的参数,如下:
## finetune
- - fine_tune True
## bottleneck
- - trans_adapter_name "bottleneck"
- - output_adapter True
## prefix-tuning
- - prefix_tuning True
## lora
- - lora_adapter True
## ConvAdapter
- - trans_adapter_name "adapterblock"
- - output_adapter True我们还根据“ emotion_cls.sh”中的每种培训方法进行了示例,使用以下命令开始新的情感分类任务:
bash emotion_cls . sh 为了进一步监督模型培训的融合,我们可以通过张量板查看日志文件:
tensorboard - - logdir = / data / path / output_earlystop_asr_fleurs_lora_2e3 / log - - bind_all @ inproceedings { li2023evaluating ,
title = { Evaluating Parameter - Efficient Transfer Learning Approaches on SURE Benchmark for Speech Understanding },
author = { Li , Yingting and Mehrish , Ambuj and Zhao , Shuai and Bhardwaj , Rishabh and Zadeh , Amir and Majumder , Navonil and Mihalcea , Rada and Poria , Soujanya },
booktitle = { ICASSP },
year = { 2023 }
}注意:如果您发现此存储库有用,请引用我们的论文。


