speech adapters
1.0.0
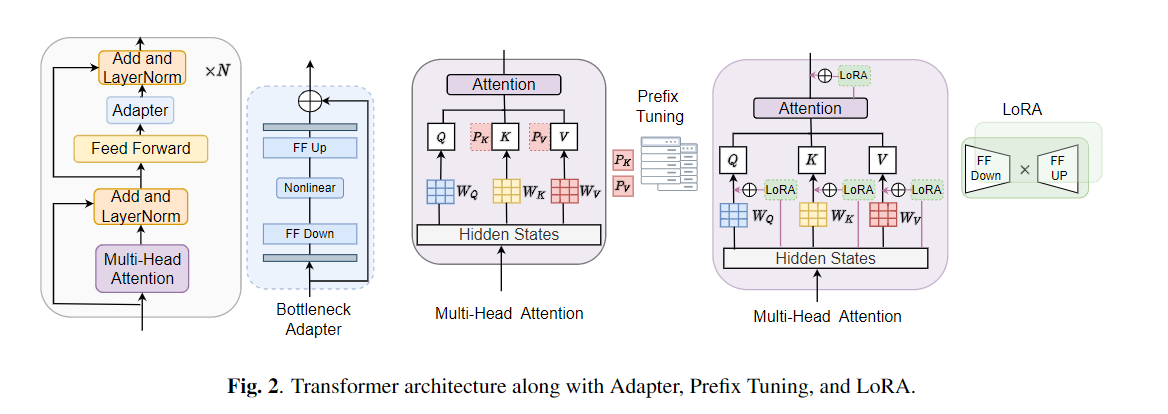
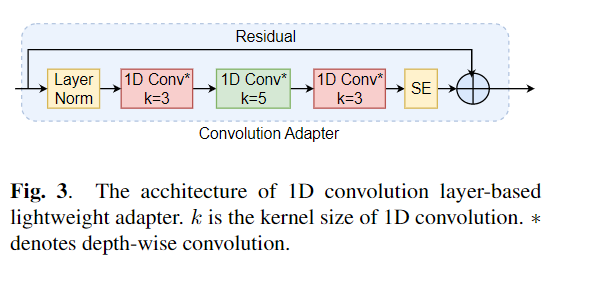
Le réglage fin est largement utilisé comme algorithme par défaut pour l'apprentissage du transfert à partir de modèles pré-formés. L'inefficacité des paramètres peut cependant survenir lorsque, pendant l'apprentissage du transfert, tous les paramètres d'un grand modèle pré-formé doivent être mis à jour pour les tâches individuelles en aval. Au fur et à mesure que le nombre de paramètres augmente, le réglage fin est sujet à un sur-ajustement et à l'oubli catastrophique. De plus, le réglage fin complet peut devenir prohibitif lorsque le modèle est utilisé pour de nombreuses tâches. Pour atténuer ce problème, des algorithmes d'apprentissage transfert par les paramètres, tels que les adaptateurs et le réglage du préfixe, ont été proposés comme un moyen d'introduire quelques paramètres formables qui peuvent être branchés sur de grands modèles de langage pré-formés tels que Bert et Hubert. Dans cet article, nous introduisons la référence d'évaluation de la compréhension de la parole (sûre) pour l'apprentissage économe en paramètres pour diverses tâches de traitement de la parole. De plus, nous introduisons un nouvel adaptateur, Convadapter, basé sur la convolution 1D. Nous montrons que Convadapter surpasse les adaptateurs standard tout en montrant des performances comparables avec le réglage du préfixe et LORA avec seulement 0,94% des paramètres formables sur certaines des tâches. Nous explorons davantage l'efficacité de l'apprentissage du transfert efficace par les paramètres pour la tâche de synthèse de la parole tels que le texte-parole (TTS).
conda create - - name speechprompt python == 3.8 . 5
conda activate speechprompt
conda install pytorch == 1.10 . 0 torchvision == 0.11 . 0 torchaudio == 0.10 . 0 - c pytorch pip install - r requirements . txt 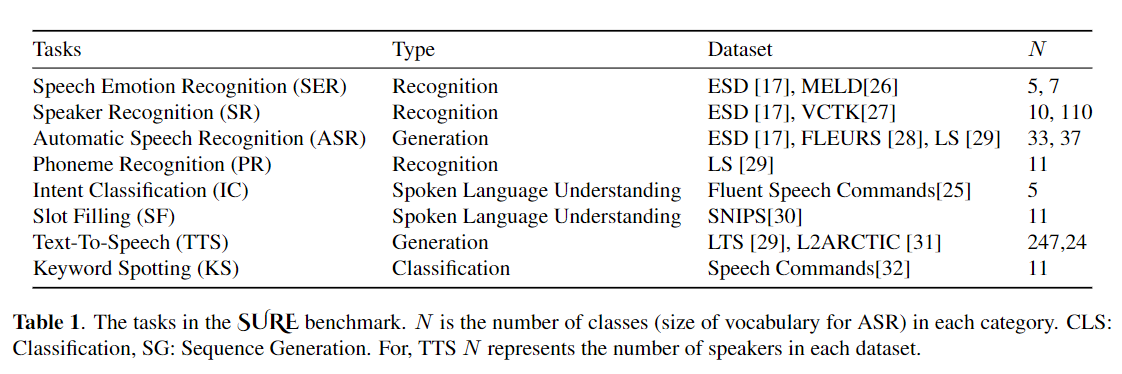
Tout d'abord, nous devons spécifier des ensembles de données et des arguments. Utilisons "ESD" comme ensemble de données, "FineTune" comme méthode de réglage dans la tâche "Reconnaissance des émotions de la parole" comme exemple:
CUDA_VISIBLE_DEVICES = 2 , 3 python train . py
- - dataset "esd"
- - data_dir "/data/path/ESD"
- - output_dir '/data/path/output_earlystop_ser_esd_finetune_2e3'
- - do_train True
- - do_eval True
- - do_predict False
- - evaluation_strategy "steps"
- - save_strategy "steps"
- - save_steps 500
- - eval_steps 25
- - learning_rate 2e-3
- - feat_adapter_name "conv_adapter"
- - trans_adapter_name "adapterblock"
- - output_adapter False
- - mh_adapter False
- - prefix_tuning False
- - lora_adapter False
- - feat_enc_adapter False
- - fine_tune True
- - per_device_train_batch_size 64
- - gradient_accumulation_steps 4
- - per_device_eval_batch_size 64
- - num_train_epochs 100
- - warmup_ratio 0.1
- - logging_steps 20
- - logging_dir '/data/path/output_earlystop_ser_esd_finetune_2e3/log'
- - load_best_model_at_end True
- - metric_for_best_model "f1" Expliquez en outre les cinq méthodes de formation du modèle. Par exemple, démarrez une nouvelle tâche de classification des émotions, nous définirons le paramètre correspondant comme ci-dessous:
## finetune
- - fine_tune True
## bottleneck
- - trans_adapter_name "bottleneck"
- - output_adapter True
## prefix-tuning
- - prefix_tuning True
## lora
- - lora_adapter True
## ConvAdapter
- - trans_adapter_name "adapterblock"
- - output_adapter TrueNous avons également placé des exemples en fonction de chaque méthode de formation dans "emotion_cls.sh", en utilisant la commande suivante pour démarrer une nouvelle tâche de classification des émotions:
bash emotion_cls . sh Afin de superviser davantage la convergence de la formation des modèles, nous pouvons afficher le fichier journal via Tensorboard:
tensorboard - - logdir = / data / path / output_earlystop_asr_fleurs_lora_2e3 / log - - bind_all @ inproceedings { li2023evaluating ,
title = { Evaluating Parameter - Efficient Transfer Learning Approaches on SURE Benchmark for Speech Understanding },
author = { Li , Yingting and Mehrish , Ambuj and Zhao , Shuai and Bhardwaj , Rishabh and Zadeh , Amir and Majumder , Navonil and Mihalcea , Rada and Poria , Soujanya },
booktitle = { ICASSP },
year = { 2023 }
}Remarque: veuillez citer notre article si vous trouvez ce référentiel utile.


