speech adapters
1.0.0
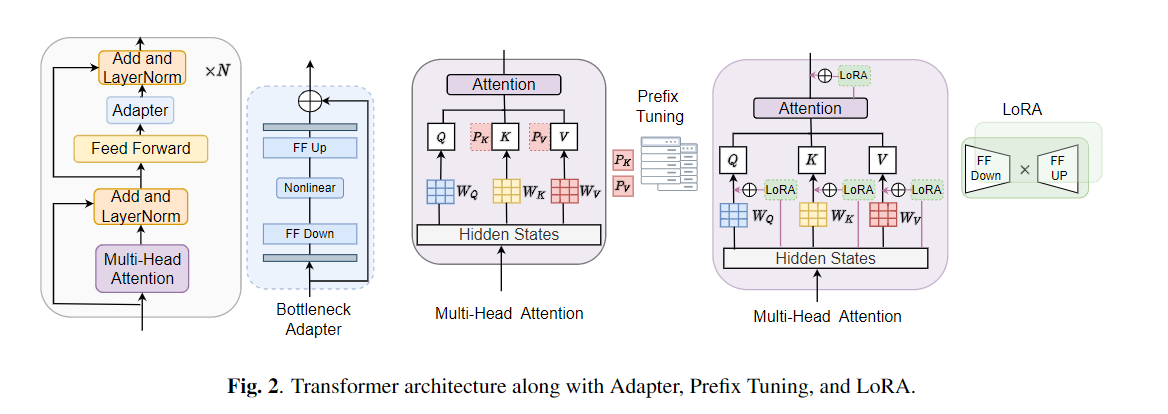
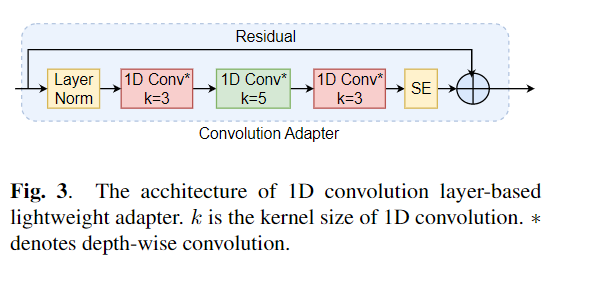
يستخدم النقل الدقيق على نطاق واسع كخوارزمية افتراضية لتعلم النقل من النماذج التي تم تدريبها مسبقًا. ومع ذلك ، يمكن أن تنشأ عدم كفاءة المعلمة عندما تحتاج إلى تحديث جميع معلمات نموذج كبير تدريبات مسبقًا ، أثناء النقل ، جميع المعلمات. مع نمو عدد المعلمات ، يكون التثبيت معرضًا للتزايد والنساء الكارثي. بالإضافة إلى ذلك ، يمكن أن يصبح الضبط الكامل مكلفًا بشكل مكلف عند استخدام النموذج للعديد من المهام. للتخفيف من هذه المشكلة ، تم اقتراح خوارزميات التعلم النقل الموفرة للمعلمة ، مثل المحولات وضبط البادئة ، كوسيلة لإدخال بعض المعلمات القابلة للتدريب التي يمكن توصيلها بنماذج لغة كبيرة تم تدريبها مسبقًا مثل BERT و Hubert. في هذه الورقة ، نقدم معيار تقييم فهم الكلام (بالتأكيد) للتعلم الفعال المعلمة لمختلف مهام معالجة الكلام. بالإضافة إلى ذلك ، نقدم محولًا جديدًا ، Convadapter ، استنادًا إلى الالتفاف 1D. نوضح أن Convadapter يتفوق على المحولات القياسية مع إظهار أداء مماثل مقابل ضبط البادئة و LORA مع 0.94 ٪ فقط من المعلمات القابلة للتدريب على بعض المهام بالتأكيد. نستكشف كذلك فعالية تعلم النقل الفعال للمعلمة لمهمة تخليق الكلام مثل النص إلى كلام (TTS).
conda create - - name speechprompt python == 3.8 . 5
conda activate speechprompt
conda install pytorch == 1.10 . 0 torchvision == 0.11 . 0 torchaudio == 0.10 . 0 - c pytorch pip install - r requirements . txt 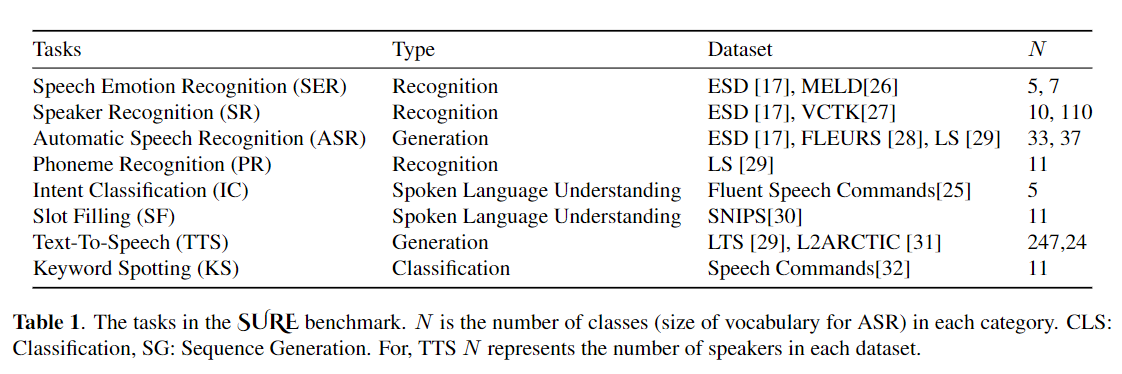
أولاً ، نحتاج إلى تحديد مجموعات البيانات والوسائط. دعنا نستخدم "ESD" كمجموعة البيانات ، "Finetune" كطريقة ضبط في مهمة "التعرف على العاطفة" كمثال:
CUDA_VISIBLE_DEVICES = 2 , 3 python train . py
- - dataset "esd"
- - data_dir "/data/path/ESD"
- - output_dir '/data/path/output_earlystop_ser_esd_finetune_2e3'
- - do_train True
- - do_eval True
- - do_predict False
- - evaluation_strategy "steps"
- - save_strategy "steps"
- - save_steps 500
- - eval_steps 25
- - learning_rate 2e-3
- - feat_adapter_name "conv_adapter"
- - trans_adapter_name "adapterblock"
- - output_adapter False
- - mh_adapter False
- - prefix_tuning False
- - lora_adapter False
- - feat_enc_adapter False
- - fine_tune True
- - per_device_train_batch_size 64
- - gradient_accumulation_steps 4
- - per_device_eval_batch_size 64
- - num_train_epochs 100
- - warmup_ratio 0.1
- - logging_steps 20
- - logging_dir '/data/path/output_earlystop_ser_esd_finetune_2e3/log'
- - load_best_model_at_end True
- - metric_for_best_model "f1" دعونا نوضح كذلك طرق التدريب الخمسة للنموذج. على سبيل المثال ، ابدأ مهمة تصنيف العاطفة الجديدة ، سنقوم بتعيين المعلمة المقابلة كما هو موضح أدناه:
## finetune
- - fine_tune True
## bottleneck
- - trans_adapter_name "bottleneck"
- - output_adapter True
## prefix-tuning
- - prefix_tuning True
## lora
- - lora_adapter True
## ConvAdapter
- - trans_adapter_name "adapterblock"
- - output_adapter Trueوضعنا أيضًا أمثلة وفقًا لكل طريقة تدريب في "Emotion_cls.sh" ، باستخدام الأمر التالي لبدء مهمة تصنيف العاطفة الجديدة:
bash emotion_cls . sh من أجل زيادة الإشراف على تقارب التدريب النموذجي ، يمكننا عرض ملف السجل من خلال Tensorboard:
tensorboard - - logdir = / data / path / output_earlystop_asr_fleurs_lora_2e3 / log - - bind_all @ inproceedings { li2023evaluating ,
title = { Evaluating Parameter - Efficient Transfer Learning Approaches on SURE Benchmark for Speech Understanding },
author = { Li , Yingting and Mehrish , Ambuj and Zhao , Shuai and Bhardwaj , Rishabh and Zadeh , Amir and Majumder , Navonil and Mihalcea , Rada and Poria , Soujanya },
booktitle = { ICASSP },
year = { 2023 }
}ملاحظة: يرجى الاستشهاد بالورقة إذا وجدت هذا المستودع مفيدًا.


