speech adapters
1.0.0
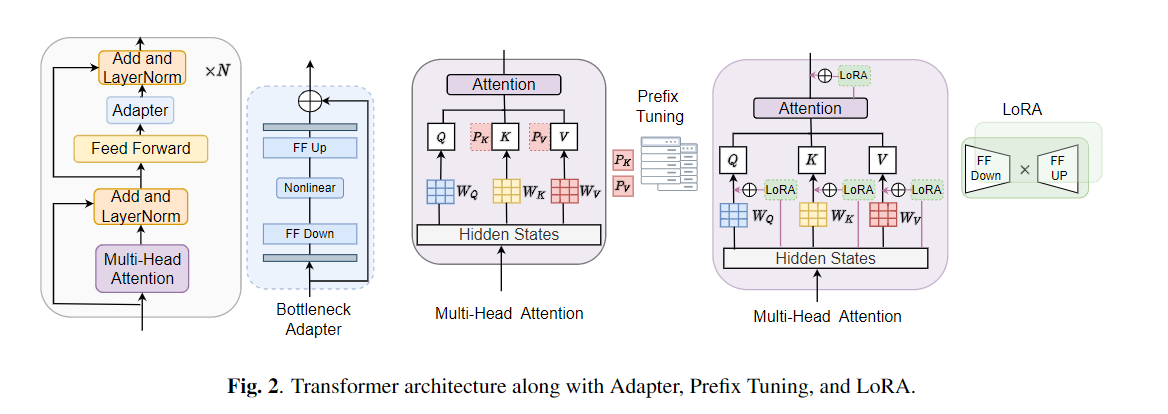
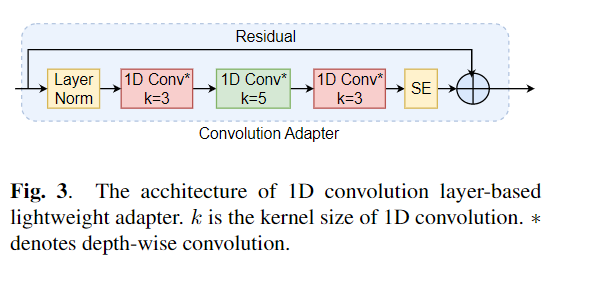
Точная настройка широко используется в качестве алгоритма по умолчанию для переноса обучения из предварительно обученных моделей. Однако неэффективность параметров может возникнуть, когда во время переноса обучения все параметры большой предварительно обученной модели должны быть обновлены для отдельных нижестоящих задач. По мере роста количества параметров, тонкая настройка подвержена переоснащению и катастрофическим забываниям. Кроме того, полная точная настройка может стать чрезмерно дорогой, когда модель используется для многих задач. Для смягчения этой проблемы были предложены алгоритмы обучения по переносу, такие как адаптеры и настройка префикса, были предложены в качестве способа ввести несколько обучаемых параметров, которые можно подключить к большим предварительно обученным языковым моделям, таким как Берт и Хуберт. В этой статье мы вводим контрольный показатель оценки речи (конечно) для параметров-эффективного обучения для различных задач обработки речи. Кроме того, мы представляем новый адаптер, Convadapter, на основе 1D свертки. Мы показываем, что Convadapter превосходит стандартные адаптеры, показывая сопоставимую производительность против настройки префикса и LORA, и только 0,94% обучаемых параметров по некоторым задачам в конечном. Кроме того, мы исследуем эффективность эффективного переносного обучения параметров для задачи синтеза речи, такой как текст в речь (TTS).
conda create - - name speechprompt python == 3.8 . 5
conda activate speechprompt
conda install pytorch == 1.10 . 0 torchvision == 0.11 . 0 torchaudio == 0.10 . 0 - c pytorch pip install - r requirements . txt 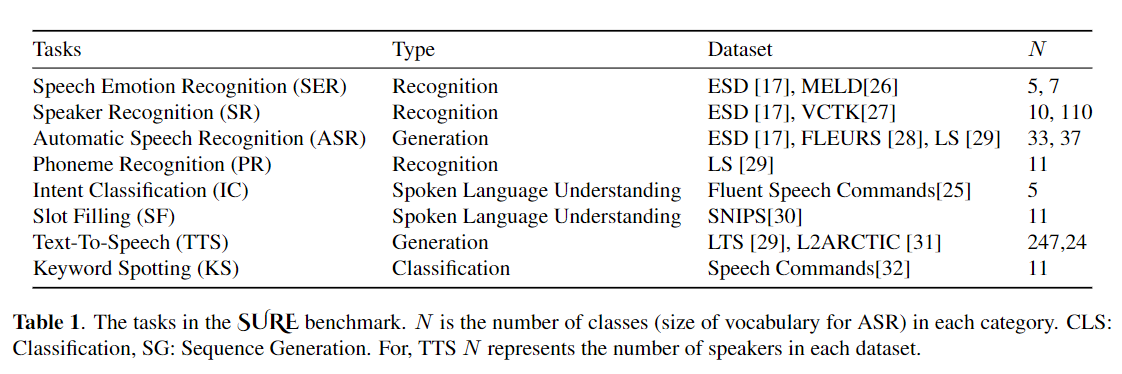
Во -первых, нам нужно указать наборы данных и аргументы. Давайте использовать «ESD» в качестве набора данных, «Finetune» в качестве метода настройки в задаче «распознавание эмоций речи» в качестве примера:
CUDA_VISIBLE_DEVICES = 2 , 3 python train . py
- - dataset "esd"
- - data_dir "/data/path/ESD"
- - output_dir '/data/path/output_earlystop_ser_esd_finetune_2e3'
- - do_train True
- - do_eval True
- - do_predict False
- - evaluation_strategy "steps"
- - save_strategy "steps"
- - save_steps 500
- - eval_steps 25
- - learning_rate 2e-3
- - feat_adapter_name "conv_adapter"
- - trans_adapter_name "adapterblock"
- - output_adapter False
- - mh_adapter False
- - prefix_tuning False
- - lora_adapter False
- - feat_enc_adapter False
- - fine_tune True
- - per_device_train_batch_size 64
- - gradient_accumulation_steps 4
- - per_device_eval_batch_size 64
- - num_train_epochs 100
- - warmup_ratio 0.1
- - logging_steps 20
- - logging_dir '/data/path/output_earlystop_ser_esd_finetune_2e3/log'
- - load_best_model_at_end True
- - metric_for_best_model "f1" Давайте также объясним пять методов обучения модели. Например, запустите новую задачу классификации эмоций, мы установим соответствующий параметр, как ниже:
## finetune
- - fine_tune True
## bottleneck
- - trans_adapter_name "bottleneck"
- - output_adapter True
## prefix-tuning
- - prefix_tuning True
## lora
- - lora_adapter True
## ConvAdapter
- - trans_adapter_name "adapterblock"
- - output_adapter TrueМы также разместили примеры в соответствии с каждым методом обучения в «Emotion_cls.sh», используя следующую команду для запуска новой задачи классификации эмоций:
bash emotion_cls . sh Чтобы дополнительно контролировать конвергенцию обучения модели, мы можем просмотреть файл журнала через Tensorboard:
tensorboard - - logdir = / data / path / output_earlystop_asr_fleurs_lora_2e3 / log - - bind_all @ inproceedings { li2023evaluating ,
title = { Evaluating Parameter - Efficient Transfer Learning Approaches on SURE Benchmark for Speech Understanding },
author = { Li , Yingting and Mehrish , Ambuj and Zhao , Shuai and Bhardwaj , Rishabh and Zadeh , Amir and Majumder , Navonil and Mihalcea , Rada and Poria , Soujanya },
booktitle = { ICASSP },
year = { 2023 }
}Примечание. Пожалуйста, процитируйте нашу статью, если вы найдете этот репозиторий полезным.


