speech adapters
1.0.0
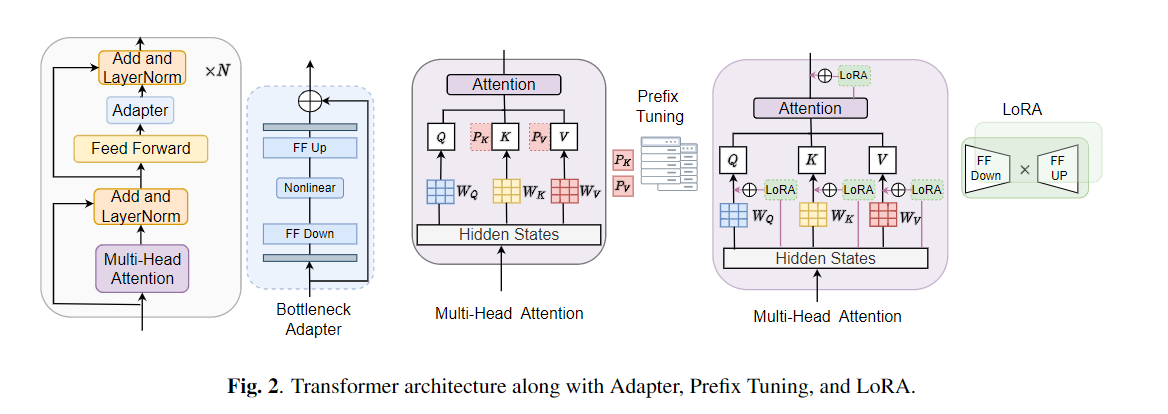
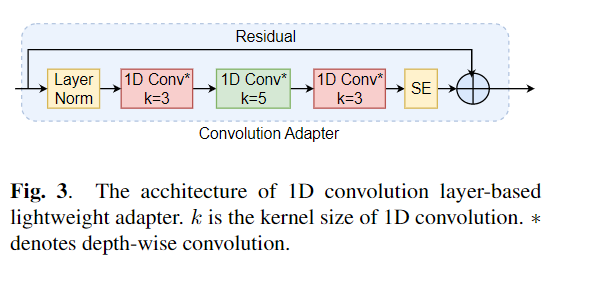
Fine-tuning banyak digunakan sebagai algoritma default untuk pembelajaran transfer dari model yang sudah terlatih. Namun, inefisiensi parameter dapat muncul ketika, selama pembelajaran transfer, semua parameter dari model pra-terlatih besar perlu diperbarui untuk tugas hilir individu. Ketika jumlah parameter tumbuh, penyempurnaan rentan terhadap overfitting dan melupakan bencana. Selain itu, penyempurnaan penuh dapat menjadi sangat mahal ketika model digunakan untuk banyak tugas. Untuk mengurangi masalah ini, algoritma pembelajaran transfer yang efisien parameter, seperti adaptor dan penyetelan awalan, telah diusulkan sebagai cara untuk memperkenalkan beberapa parameter yang dapat dilatih yang dapat dicolokkan ke model bahasa pra-terlatih besar seperti Bert, dan Hubert. Dalam makalah ini, kami memperkenalkan tolok ukur evaluasi pemahaman wicara (tentu) untuk pembelajaran yang efisien parameter untuk berbagai tugas pemrosesan bicara. Selain itu, kami memperkenalkan adaptor baru, Convadapter, berdasarkan konvolusi 1D. Kami menunjukkan bahwa ConvAdapter mengungguli adapter standar sambil menunjukkan kinerja yang sebanding dengan tuning awalan dan LORA dengan hanya 0,94% parameter yang dapat dilatih pada beberapa tugas dengan pasti. Kami selanjutnya mengeksplorasi efektivitas pembelajaran transfer efisien parameter untuk tugas sintesis bicara seperti teks-ke-pidato (TTS).
conda create - - name speechprompt python == 3.8 . 5
conda activate speechprompt
conda install pytorch == 1.10 . 0 torchvision == 0.11 . 0 torchaudio == 0.10 . 0 - c pytorch pip install - r requirements . txt 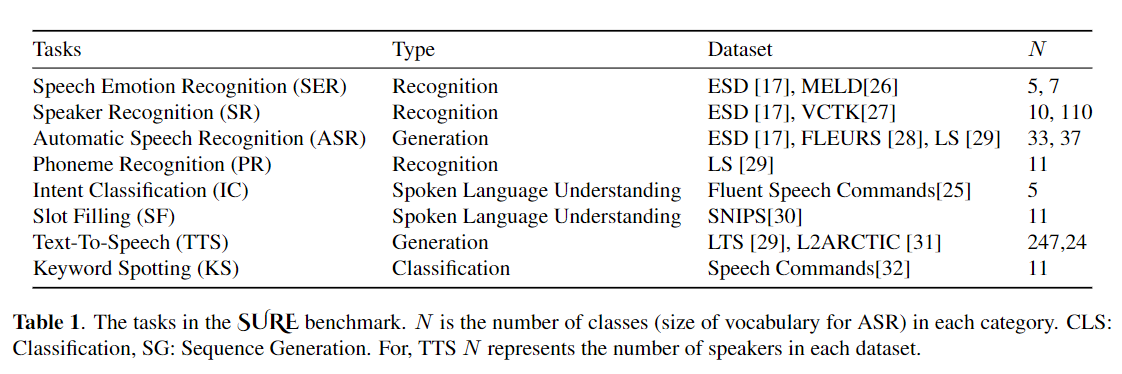
Pertama, kita perlu menentukan set data dan argumen. Mari kita gunakan "ESD" sebagai dataset, "Finetune" sebagai metode tuning dalam tugas "pengenalan emosi wicara" sebagai contoh:
CUDA_VISIBLE_DEVICES = 2 , 3 python train . py
- - dataset "esd"
- - data_dir "/data/path/ESD"
- - output_dir '/data/path/output_earlystop_ser_esd_finetune_2e3'
- - do_train True
- - do_eval True
- - do_predict False
- - evaluation_strategy "steps"
- - save_strategy "steps"
- - save_steps 500
- - eval_steps 25
- - learning_rate 2e-3
- - feat_adapter_name "conv_adapter"
- - trans_adapter_name "adapterblock"
- - output_adapter False
- - mh_adapter False
- - prefix_tuning False
- - lora_adapter False
- - feat_enc_adapter False
- - fine_tune True
- - per_device_train_batch_size 64
- - gradient_accumulation_steps 4
- - per_device_eval_batch_size 64
- - num_train_epochs 100
- - warmup_ratio 0.1
- - logging_steps 20
- - logging_dir '/data/path/output_earlystop_ser_esd_finetune_2e3/log'
- - load_best_model_at_end True
- - metric_for_best_model "f1" Mari kita jelaskan lebih lanjut lima metode pelatihan model. Misalnya, mulailah tugas klasifikasi emosi baru, kami akan mengatur parameter yang sesuai seperti di bawah ini:
## finetune
- - fine_tune True
## bottleneck
- - trans_adapter_name "bottleneck"
- - output_adapter True
## prefix-tuning
- - prefix_tuning True
## lora
- - lora_adapter True
## ConvAdapter
- - trans_adapter_name "adapterblock"
- - output_adapter TrueKami juga memberikan contoh sesuai dengan setiap metode pelatihan di "Emotion_Cls.sh", menggunakan perintah berikut untuk memulai tugas klasifikasi emosi baru:
bash emotion_cls . sh Untuk lebih mengawasi konvergensi pelatihan model, kami dapat melihat file log melalui Tensorboard:
tensorboard - - logdir = / data / path / output_earlystop_asr_fleurs_lora_2e3 / log - - bind_all @ inproceedings { li2023evaluating ,
title = { Evaluating Parameter - Efficient Transfer Learning Approaches on SURE Benchmark for Speech Understanding },
author = { Li , Yingting and Mehrish , Ambuj and Zhao , Shuai and Bhardwaj , Rishabh and Zadeh , Amir and Majumder , Navonil and Mihalcea , Rada and Poria , Soujanya },
booktitle = { ICASSP },
year = { 2023 }
}Catatan: Harap kutip kertas kami jika Anda menemukan repositori ini bermanfaat.


