speech adapters
1.0.0
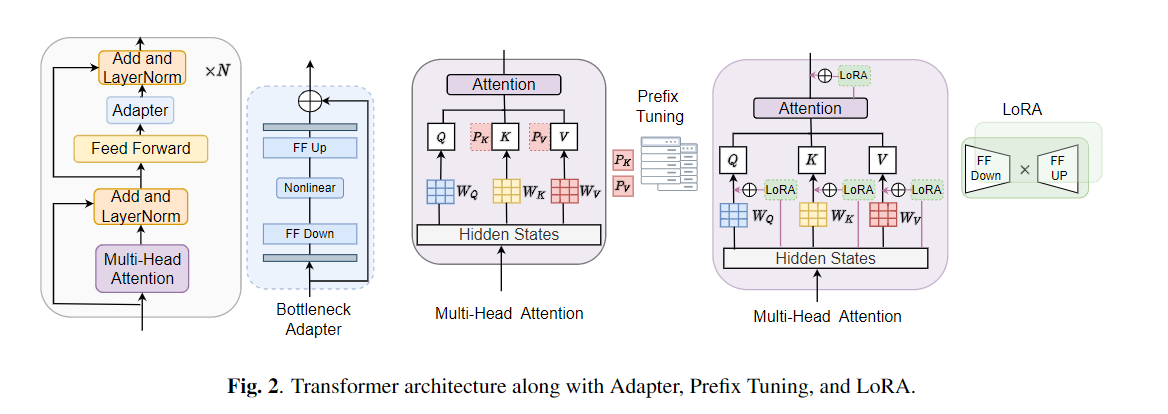
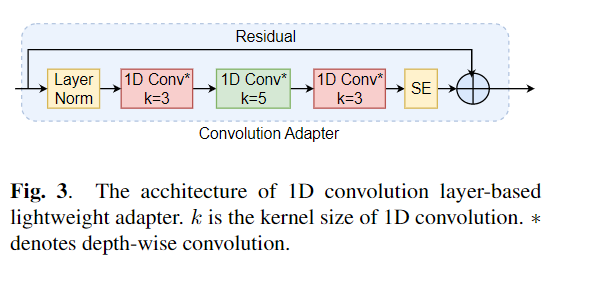
El ajuste fino se usa ampliamente como algoritmo predeterminado para transferir el aprendizaje de los modelos previamente capacitados. Sin embargo, la ineficiencia de los parámetros puede surgir cuando, durante el aprendizaje de la transferencia, todos los parámetros de un gran modelo previamente capacitado deben actualizarse para tareas individuales posteriores. A medida que crece el número de parámetros, el ajuste fino es propenso al sobreajuste y el olvido catastrófico. Además, el ajuste completo puede volverse prohibitivamente costoso cuando el modelo se usa para muchas tareas. Para mitigar este problema, se han propuesto algoritmos de aprendizaje de transferencia de parámetros, como adaptadores y ajuste de prefijo, como una forma de introducir algunos parámetros capacitables que pueden conectarse a grandes modelos de lenguaje previamente capacitados como Bert y Hubert. En este documento, presentamos el punto de referencia de evaluación de comprensión del habla (seguro) para el aprendizaje de los parámetros eficientes para varias tareas de procesamiento del habla. Además, presentamos un nuevo adaptador, Convadapter, basado en la convolución 1D. Mostramos que el Convado supera a los adaptadores estándar al tiempo que muestra un rendimiento comparable contra el ajuste de prefijo y Lora con solo el 0.94% de los parámetros capacitables en algunas de las tareas seguras. Además, exploramos la efectividad del aprendizaje de transferencia eficiente de parámetros para la tarea de síntesis de habla, como texto a voz (TTS).
conda create - - name speechprompt python == 3.8 . 5
conda activate speechprompt
conda install pytorch == 1.10 . 0 torchvision == 0.11 . 0 torchaudio == 0.10 . 0 - c pytorch pip install - r requirements . txt 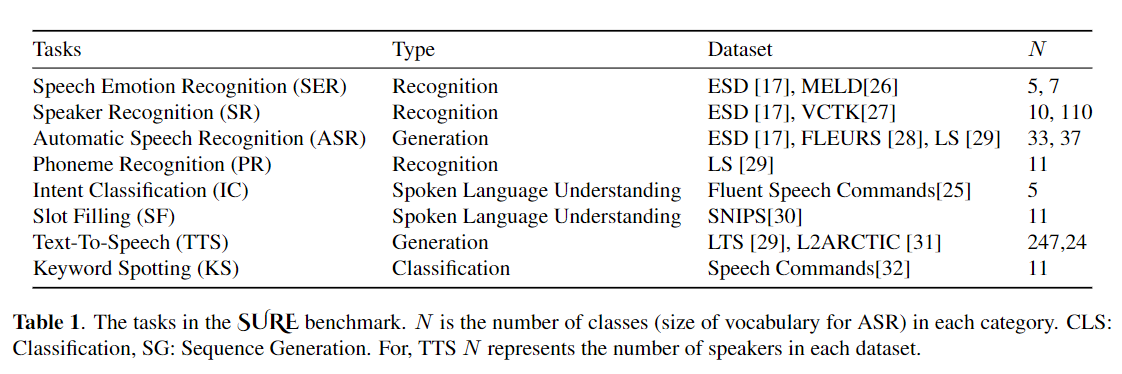
Primero, necesitamos especificar conjuntos de datos y argumentos. Usemos "ESD" como conjunto de datos, "Finetune" como el método de ajuste en la tarea de "Reconocimiento de emociones del habla" como ejemplo:
CUDA_VISIBLE_DEVICES = 2 , 3 python train . py
- - dataset "esd"
- - data_dir "/data/path/ESD"
- - output_dir '/data/path/output_earlystop_ser_esd_finetune_2e3'
- - do_train True
- - do_eval True
- - do_predict False
- - evaluation_strategy "steps"
- - save_strategy "steps"
- - save_steps 500
- - eval_steps 25
- - learning_rate 2e-3
- - feat_adapter_name "conv_adapter"
- - trans_adapter_name "adapterblock"
- - output_adapter False
- - mh_adapter False
- - prefix_tuning False
- - lora_adapter False
- - feat_enc_adapter False
- - fine_tune True
- - per_device_train_batch_size 64
- - gradient_accumulation_steps 4
- - per_device_eval_batch_size 64
- - num_train_epochs 100
- - warmup_ratio 0.1
- - logging_steps 20
- - logging_dir '/data/path/output_earlystop_ser_esd_finetune_2e3/log'
- - load_best_model_at_end True
- - metric_for_best_model "f1" Expliquemos más los cinco métodos de entrenamiento del modelo. Por ejemplo, inicie una nueva tarea de clasificación de emociones, estableceremos el parámetro correspondiente como a continuación:
## finetune
- - fine_tune True
## bottleneck
- - trans_adapter_name "bottleneck"
- - output_adapter True
## prefix-tuning
- - prefix_tuning True
## lora
- - lora_adapter True
## ConvAdapter
- - trans_adapter_name "adapterblock"
- - output_adapter TrueTambién colocamos ejemplos de acuerdo con cada método de entrenamiento en "emocion_cls.sh", utilizando el siguiente comando para iniciar una nueva tarea de clasificación de emociones:
bash emotion_cls . sh Para supervisar aún más la convergencia de la capacitación del modelo, podemos ver el archivo de registro a través de TensorBoard:
tensorboard - - logdir = / data / path / output_earlystop_asr_fleurs_lora_2e3 / log - - bind_all @ inproceedings { li2023evaluating ,
title = { Evaluating Parameter - Efficient Transfer Learning Approaches on SURE Benchmark for Speech Understanding },
author = { Li , Yingting and Mehrish , Ambuj and Zhao , Shuai and Bhardwaj , Rishabh and Zadeh , Amir and Majumder , Navonil and Mihalcea , Rada and Poria , Soujanya },
booktitle = { ICASSP },
year = { 2023 }
}Nota: Cite nuestro documento si encuentra útil este repositorio.


