speech adapters
1.0.0
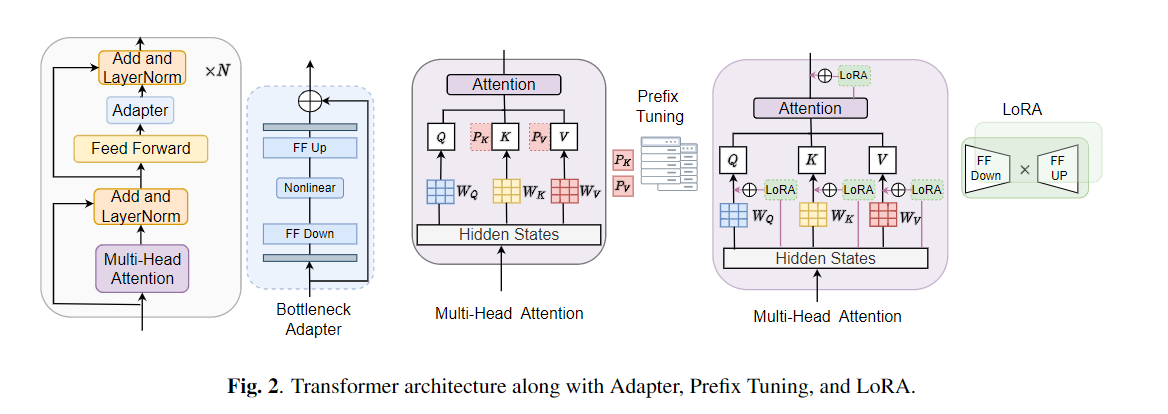
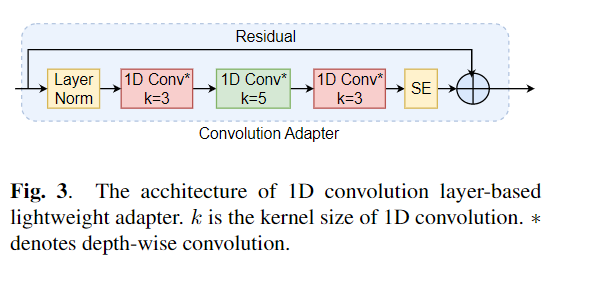
微調整は、事前に訓練されたモデルからの転送学習のデフォルトアルゴリズムとして広く使用されています。ただし、パラメーターの非効率性は、転送学習中に、個々のダウンストリームタスクに対して大規模な事前訓練モデルのすべてのパラメーターを更新する必要がある場合に発生する可能性があります。パラメーターの数が増えるにつれて、微調整は過度に適合し、壊滅的な忘却を受けやすくなります。さらに、モデルが多くのタスクに使用されると、完全な微調整が法外に高価になる可能性があります。この問題を軽減するために、アダプターやプレフィックスチューニングなどのパラメーター効率の高い転送学習アルゴリズムは、BertやHubertなどの大規模な訓練を受けた言語モデルにプラグインできるいくつかのトレーニング可能なパラメーターを導入する方法として提案されています。この論文では、さまざまな音声処理タスクのパラメーター効率の高い学習のための音声理解評価(SURE)ベンチマークを紹介します。さらに、1D畳み込みに基づいて、新しいアダプター、コンバダプターを紹介します。コンバダプターが標準のアダプターを上回り、プレフィックスチューニングとLORAに対して同等のパフォーマンスを示し、いくつかのタスクでトレーニング可能なパラメーターのわずか0.94%を示していることを示します。さらに、テキストからスピーチ(TTS)などの音声合成タスクのパラメーター効率的な転送学習の有効性を調査します。
conda create - - name speechprompt python == 3.8 . 5
conda activate speechprompt
conda install pytorch == 1.10 . 0 torchvision == 0.11 . 0 torchaudio == 0.10 . 0 - c pytorch pip install - r requirements . txt 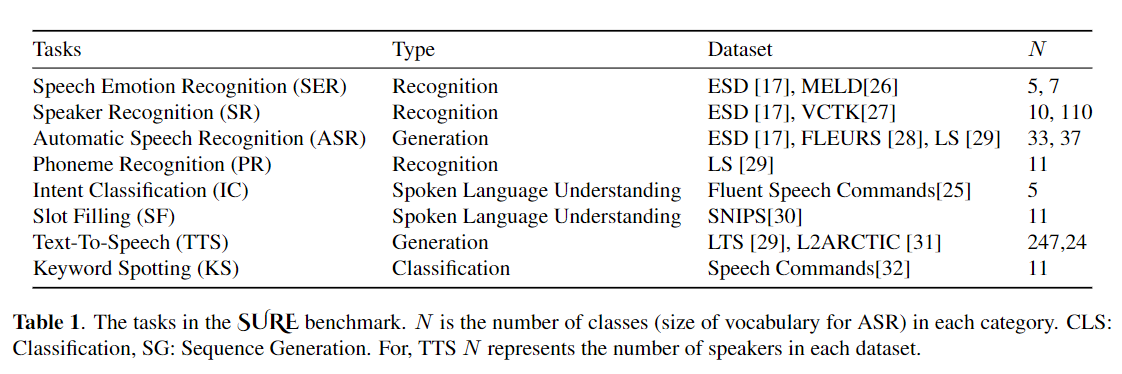
まず、データセットと引数を指定する必要があります。 「ESD」をデータセットとして使用し、「Speech Emotion認識」タスクのチューニング方法として「Finetune」を例として使用しましょう。
CUDA_VISIBLE_DEVICES = 2 , 3 python train . py
- - dataset "esd"
- - data_dir "/data/path/ESD"
- - output_dir '/data/path/output_earlystop_ser_esd_finetune_2e3'
- - do_train True
- - do_eval True
- - do_predict False
- - evaluation_strategy "steps"
- - save_strategy "steps"
- - save_steps 500
- - eval_steps 25
- - learning_rate 2e-3
- - feat_adapter_name "conv_adapter"
- - trans_adapter_name "adapterblock"
- - output_adapter False
- - mh_adapter False
- - prefix_tuning False
- - lora_adapter False
- - feat_enc_adapter False
- - fine_tune True
- - per_device_train_batch_size 64
- - gradient_accumulation_steps 4
- - per_device_eval_batch_size 64
- - num_train_epochs 100
- - warmup_ratio 0.1
- - logging_steps 20
- - logging_dir '/data/path/output_earlystop_ser_esd_finetune_2e3/log'
- - load_best_model_at_end True
- - metric_for_best_model "f1" モデルの5つのトレーニング方法についてさらに説明しましょう。たとえば、新しい感情分類タスクを開始すると、以下のような対応するパラメーターを設定します。
## finetune
- - fine_tune True
## bottleneck
- - trans_adapter_name "bottleneck"
- - output_adapter True
## prefix-tuning
- - prefix_tuning True
## lora
- - lora_adapter True
## ConvAdapter
- - trans_adapter_name "adapterblock"
- - output_adapter Trueまた、次のコマンドを使用して新しい感情分類タスクを開始するために、「感情_cls.sh」の各トレーニング方法に従って例を配置しました。
bash emotion_cls . sh モデルトレーニングの収束をさらに監督するために、テンソルボードを介してログファイルを表示できます。
tensorboard - - logdir = / data / path / output_earlystop_asr_fleurs_lora_2e3 / log - - bind_all @ inproceedings { li2023evaluating ,
title = { Evaluating Parameter - Efficient Transfer Learning Approaches on SURE Benchmark for Speech Understanding },
author = { Li , Yingting and Mehrish , Ambuj and Zhao , Shuai and Bhardwaj , Rishabh and Zadeh , Amir and Majumder , Navonil and Mihalcea , Rada and Poria , Soujanya },
booktitle = { ICASSP },
year = { 2023 }
}注:このリポジトリが便利だと思う場合は、私たちの論文を引用してください。


