speech adapters
1.0.0
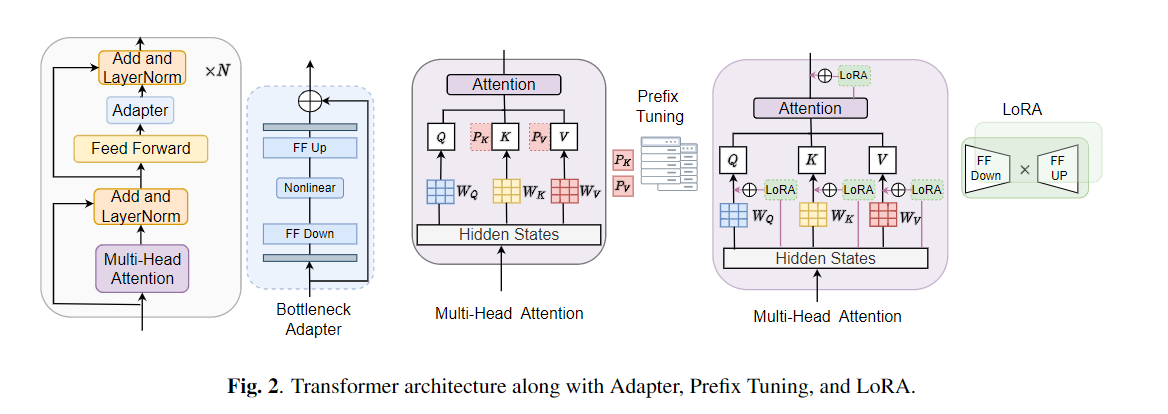
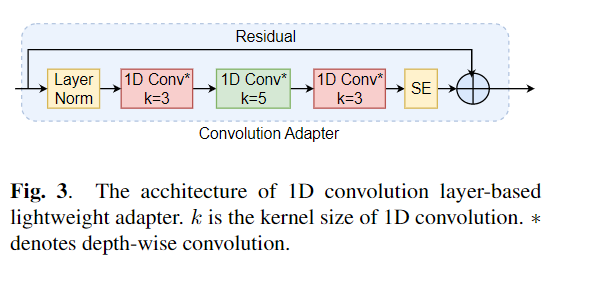
Die Feinabstimmung wird häufig als Standardalgorithmus für das Transferlernen aus vorgeborenen Modellen verwendet. Die Parameter-Ineffizienz kann jedoch auftreten, wenn beim Übertragungslernen alle Parameter eines großen vorgeborenen Modells für einzelne nachgeschaltete Aufgaben aktualisiert werden müssen. Wenn die Anzahl der Parameter wächst, neigt die Feinabstimmung anfällig für überanpassende und katastrophale Vergessen. Darüber hinaus kann eine vollständige Feinabstimmung unerschwinglich teuer werden, wenn das Modell für viele Aufgaben verwendet wird. Um dieses Problem zu mildern, wurden parameter-effiziente Transferlernalgorithmen wie Adapter und Präfix-Tuning vorgeschlagen, um einige trainierbare Parameter einzuführen, die in große vorgebaute Sprachmodelle wie Bert und Hubert angeschlossen werden können. In diesem Artikel stellen wir den Benchmark (SPECE-Verständnis-Evaluation) für das parametereffiziente Lernen für verschiedene Sprachverarbeitungsaufgaben vor. Darüber hinaus stellen wir einen neuen Adapter, Convadapter, basierend auf 1D -Faltung vor. Wir zeigen, dass Convadapter die Standardadapter übertrifft und gleichzeitig eine vergleichbare Leistung mit dem Präfix -Tuning und Lora mit nur 0,94% der trainierbaren Parameter für einige der Aufgaben zeigt. Wir untersuchen weiter die Wirksamkeit des effizienten Transferlernens für die Sprachsynthese wie Text-to-Speech (TTS).
conda create - - name speechprompt python == 3.8 . 5
conda activate speechprompt
conda install pytorch == 1.10 . 0 torchvision == 0.11 . 0 torchaudio == 0.10 . 0 - c pytorch pip install - r requirements . txt 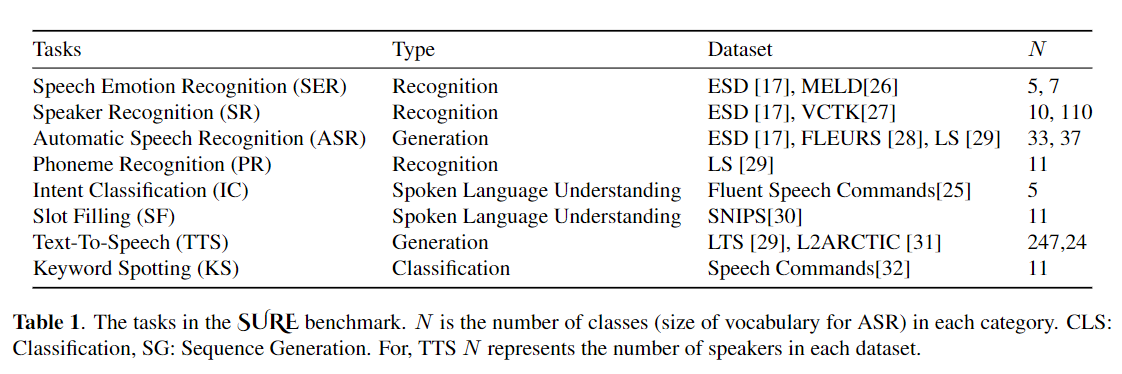
Zunächst müssen wir Datensätze und Argumente angeben. Lassen Sie uns "ESD" als Datensatz "finetune" als Tuning -Methode in der Aufgabe "Sprachemotionserkennung" als Beispiel verwenden:
CUDA_VISIBLE_DEVICES = 2 , 3 python train . py
- - dataset "esd"
- - data_dir "/data/path/ESD"
- - output_dir '/data/path/output_earlystop_ser_esd_finetune_2e3'
- - do_train True
- - do_eval True
- - do_predict False
- - evaluation_strategy "steps"
- - save_strategy "steps"
- - save_steps 500
- - eval_steps 25
- - learning_rate 2e-3
- - feat_adapter_name "conv_adapter"
- - trans_adapter_name "adapterblock"
- - output_adapter False
- - mh_adapter False
- - prefix_tuning False
- - lora_adapter False
- - feat_enc_adapter False
- - fine_tune True
- - per_device_train_batch_size 64
- - gradient_accumulation_steps 4
- - per_device_eval_batch_size 64
- - num_train_epochs 100
- - warmup_ratio 0.1
- - logging_steps 20
- - logging_dir '/data/path/output_earlystop_ser_esd_finetune_2e3/log'
- - load_best_model_at_end True
- - metric_for_best_model "f1" Lassen Sie uns die fünf Trainingsmethoden des Modells weiter erläutern. Starten Sie beispielsweise eine neue Emotionsklassifizierungsaufgabe, wir setzen den entsprechenden Parameter wie unten fest:
## finetune
- - fine_tune True
## bottleneck
- - trans_adapter_name "bottleneck"
- - output_adapter True
## prefix-tuning
- - prefix_tuning True
## lora
- - lora_adapter True
## ConvAdapter
- - trans_adapter_name "adapterblock"
- - output_adapter TrueWir haben auch Beispiele gemäß jeder Trainingsmethode in "emotion_cls.sh" unter Verwendung des folgenden Befehls gegeben, um eine neue Emotion -Klassifizierungsaufgabe zu starten:
bash emotion_cls . sh Um die Konvergenz des Modelltrainings weiter zu überwachen, können wir die Protokolldatei über Tensorboard anzeigen:
tensorboard - - logdir = / data / path / output_earlystop_asr_fleurs_lora_2e3 / log - - bind_all @ inproceedings { li2023evaluating ,
title = { Evaluating Parameter - Efficient Transfer Learning Approaches on SURE Benchmark for Speech Understanding },
author = { Li , Yingting and Mehrish , Ambuj and Zhao , Shuai and Bhardwaj , Rishabh and Zadeh , Amir and Majumder , Navonil and Mihalcea , Rada and Poria , Soujanya },
booktitle = { ICASSP },
year = { 2023 }
}Hinweis: Bitte zitieren Sie unser Papier, wenn Sie dieses Repository nützlich finden.


