speech adapters
1.0.0
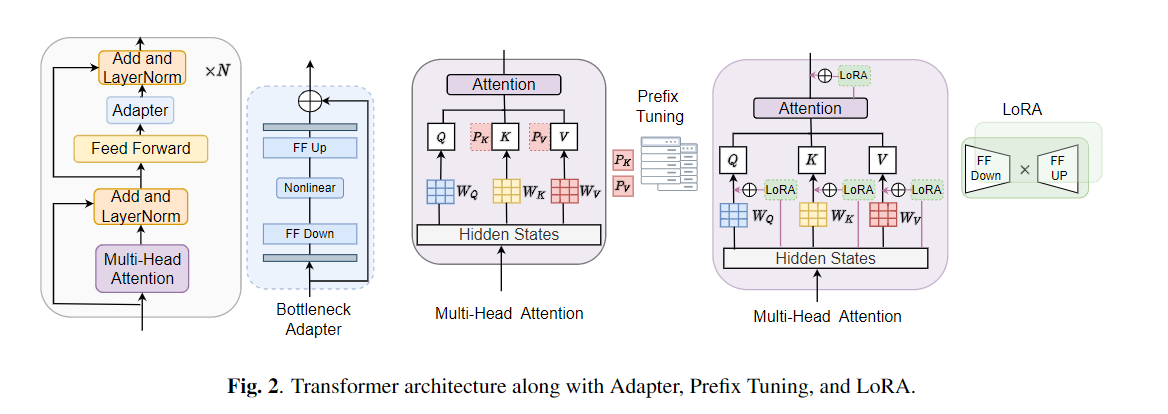
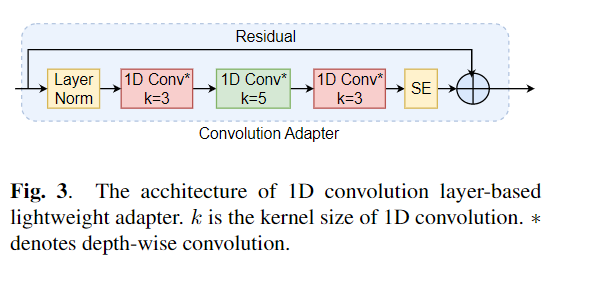
การปรับแต่งอย่างกว้างขวางถูกใช้อย่างกว้างขวางเป็นอัลกอริทึมเริ่มต้นสำหรับการถ่ายโอนการเรียนรู้จากโมเดลที่ผ่านการฝึกอบรมมาก่อน อย่างไรก็ตามความไร้ประสิทธิภาพของพารามิเตอร์สามารถเกิดขึ้นได้เมื่อระหว่างการเรียนรู้การถ่ายโอนพารามิเตอร์ทั้งหมดของโมเดลที่ผ่านการฝึกอบรมมาก่อนขนาดใหญ่จำเป็นต้องได้รับการปรับปรุงสำหรับงานดาวน์สตรีมแต่ละรายการ เมื่อจำนวนพารามิเตอร์เพิ่มขึ้นการปรับจูนมีแนวโน้มที่จะลืมไปมากเกินไปและหายนะ นอกจากนี้การปรับจูนแบบเต็มอาจมีราคาแพงอย่างห้ามเมื่อใช้แบบจำลองสำหรับงานหลายอย่าง เพื่อลดปัญหานี้อัลกอริธึมการเรียนรู้การถ่ายโอนพารามิเตอร์-ประสิทธิภาพเช่นอะแดปเตอร์และการปรับแต่งคำนำหน้าได้รับการเสนอเป็นวิธีการแนะนำพารามิเตอร์การฝึกอบรมที่สามารถเสียบเข้ากับโมเดลภาษาที่ผ่านการฝึกอบรมล่วงหน้าขนาดใหญ่เช่นเบิร์ตและฮิวเบิร์ต ในบทความนี้เราแนะนำมาตรฐานการประเมินความเข้าใจคำพูด (SURE) สำหรับการเรียนรู้ที่มีประสิทธิภาพพารามิเตอร์สำหรับงานการประมวลผลคำพูดต่างๆ นอกจากนี้เรายังแนะนำอะแดปเตอร์ใหม่ Convadapter ตาม 1D Convolution เราแสดงให้เห็นว่า Convadapter มีประสิทธิภาพสูงกว่าอะแดปเตอร์มาตรฐานในขณะที่แสดงประสิทธิภาพที่เปรียบเทียบได้กับการปรับแต่งคำนำหน้าและ LORA ด้วยพารามิเตอร์ฝึกอบรมที่สามารถฝึกอบรมได้เพียง 0.94% เราสำรวจประสิทธิภาพของพารามิเตอร์การเรียนรู้การถ่ายโอนที่มีประสิทธิภาพสำหรับงานสังเคราะห์เสียงพูดเช่นข้อความเป็นคำพูด (TTS)
conda create - - name speechprompt python == 3.8 . 5
conda activate speechprompt
conda install pytorch == 1.10 . 0 torchvision == 0.11 . 0 torchaudio == 0.10 . 0 - c pytorch pip install - r requirements . txt 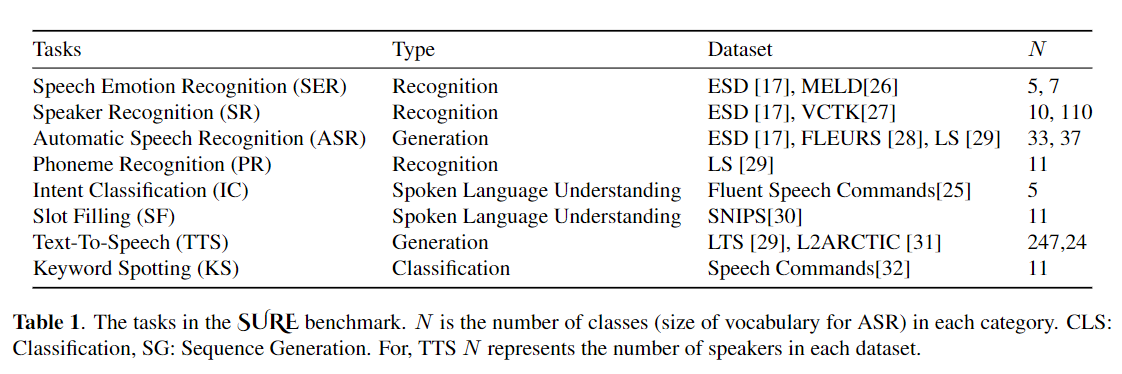
ก่อนอื่นเราต้องระบุชุดข้อมูลและอาร์กิวเมนต์ ลองใช้ "ESD" เป็นชุดข้อมูล "finetune" เป็นวิธีการปรับแต่งในงาน "การจดจำอารมณ์ความรู้สึก" เป็นตัวอย่าง:
CUDA_VISIBLE_DEVICES = 2 , 3 python train . py
- - dataset "esd"
- - data_dir "/data/path/ESD"
- - output_dir '/data/path/output_earlystop_ser_esd_finetune_2e3'
- - do_train True
- - do_eval True
- - do_predict False
- - evaluation_strategy "steps"
- - save_strategy "steps"
- - save_steps 500
- - eval_steps 25
- - learning_rate 2e-3
- - feat_adapter_name "conv_adapter"
- - trans_adapter_name "adapterblock"
- - output_adapter False
- - mh_adapter False
- - prefix_tuning False
- - lora_adapter False
- - feat_enc_adapter False
- - fine_tune True
- - per_device_train_batch_size 64
- - gradient_accumulation_steps 4
- - per_device_eval_batch_size 64
- - num_train_epochs 100
- - warmup_ratio 0.1
- - logging_steps 20
- - logging_dir '/data/path/output_earlystop_ser_esd_finetune_2e3/log'
- - load_best_model_at_end True
- - metric_for_best_model "f1" เพิ่มเติมอธิบายวิธีการฝึกอบรมห้าวิธีของแบบจำลอง ตัวอย่างเช่นเริ่มงานการจำแนกอารมณ์ใหม่เราจะตั้งค่าพารามิเตอร์ที่เกี่ยวข้องเช่นด้านล่าง:
## finetune
- - fine_tune True
## bottleneck
- - trans_adapter_name "bottleneck"
- - output_adapter True
## prefix-tuning
- - prefix_tuning True
## lora
- - lora_adapter True
## ConvAdapter
- - trans_adapter_name "adapterblock"
- - output_adapter Trueนอกจากนี้เรายังวางตัวอย่างตามวิธีการฝึกอบรมแต่ละวิธีใน "Emotion_cls.sh" โดยใช้คำสั่งต่อไปนี้เพื่อเริ่มงานการจำแนกอารมณ์ใหม่:
bash emotion_cls . sh เพื่อควบคุมการบรรจบกันของการฝึกอบรมแบบจำลองเราสามารถดูไฟล์บันทึกผ่าน Tensorboard:
tensorboard - - logdir = / data / path / output_earlystop_asr_fleurs_lora_2e3 / log - - bind_all @ inproceedings { li2023evaluating ,
title = { Evaluating Parameter - Efficient Transfer Learning Approaches on SURE Benchmark for Speech Understanding },
author = { Li , Yingting and Mehrish , Ambuj and Zhao , Shuai and Bhardwaj , Rishabh and Zadeh , Amir and Majumder , Navonil and Mihalcea , Rada and Poria , Soujanya },
booktitle = { ICASSP },
year = { 2023 }
}หมายเหตุ: โปรดอ้างอิงกระดาษของเราหากคุณพบว่าที่เก็บนี้มีประโยชน์


