speech adapters
1.0.0
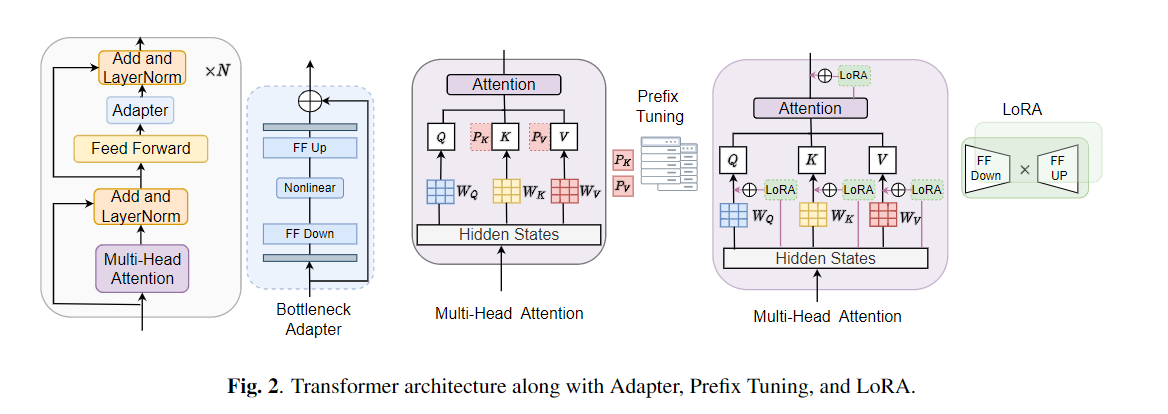
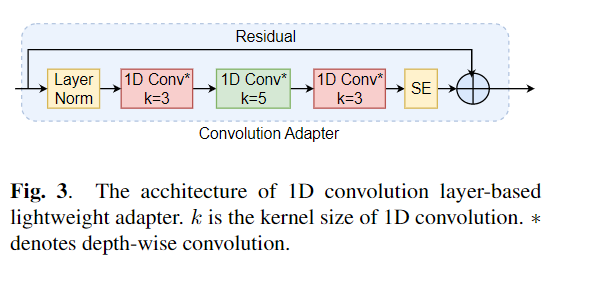
O ajuste fino é amplamente utilizado como o algoritmo padrão para o aprendizado de transferência de modelos pré-treinados. No entanto, a ineficiência dos parâmetros pode surgir quando, durante o aprendizado de transferência, todos os parâmetros de um grande modelo pré-treinado precisam ser atualizados para tarefas individuais a jusante. À medida que o número de parâmetros cresce, o ajuste fino é propenso a excesso de ajuste e esquecimento catastrófico. Além disso, o ajuste fino total pode se tornar proibitivamente caro quando o modelo é usado para muitas tarefas. Para mitigar esse problema, os algoritmos de aprendizado de transferência com eficiência de parâmetro, como adaptadores e ajuste de prefixo, foram propostos como uma maneira de introduzir alguns parâmetros treináveis que podem ser conectados a grandes modelos de linguagem pré-treinados, como Bert e Hubert. Neste artigo, introduzimos a avaliação da Avaliação de Entendimento de Discursos (com certeza) para obter aprendizado com eficiência de parâmetro para várias tarefas de processamento de fala. Além disso, introduzimos um novo adaptador, Convadapter, com base na convolução 1D. Mostramos que o Convadapter supera os adaptadores padrão enquanto mostra um desempenho comparável contra o ajuste do prefixo e o LORA com apenas 0,94% dos parâmetros treináveis em algumas das tarefas com certeza. Exploramos ainda a eficácia do aprendizado de transferência eficiente de parâmetro para tarefa de síntese de fala, como texto em fala (TTS).
conda create - - name speechprompt python == 3.8 . 5
conda activate speechprompt
conda install pytorch == 1.10 . 0 torchvision == 0.11 . 0 torchaudio == 0.10 . 0 - c pytorch pip install - r requirements . txt 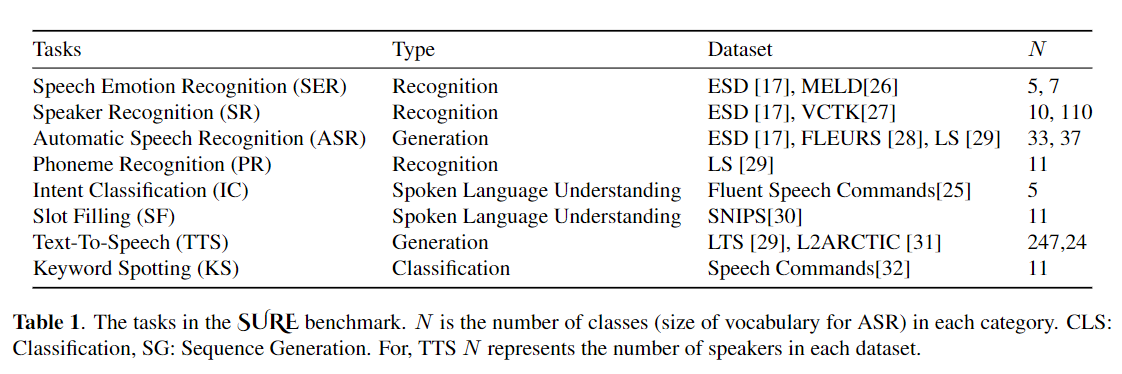
Primeiro, precisamos especificar conjuntos de dados e argumentos. Vamos usar o "ESD" como o conjunto de dados, "Finetune" como o método de ajuste em "reconhecimento de emoção de fala" Tarefa como exemplo:
CUDA_VISIBLE_DEVICES = 2 , 3 python train . py
- - dataset "esd"
- - data_dir "/data/path/ESD"
- - output_dir '/data/path/output_earlystop_ser_esd_finetune_2e3'
- - do_train True
- - do_eval True
- - do_predict False
- - evaluation_strategy "steps"
- - save_strategy "steps"
- - save_steps 500
- - eval_steps 25
- - learning_rate 2e-3
- - feat_adapter_name "conv_adapter"
- - trans_adapter_name "adapterblock"
- - output_adapter False
- - mh_adapter False
- - prefix_tuning False
- - lora_adapter False
- - feat_enc_adapter False
- - fine_tune True
- - per_device_train_batch_size 64
- - gradient_accumulation_steps 4
- - per_device_eval_batch_size 64
- - num_train_epochs 100
- - warmup_ratio 0.1
- - logging_steps 20
- - logging_dir '/data/path/output_earlystop_ser_esd_finetune_2e3/log'
- - load_best_model_at_end True
- - metric_for_best_model "f1" Vamos explicar mais os cinco métodos de treinamento do modelo. Por exemplo, inicie uma nova tarefa de classificação de emoção, definiremos o parâmetro correspondente, como abaixo:
## finetune
- - fine_tune True
## bottleneck
- - trans_adapter_name "bottleneck"
- - output_adapter True
## prefix-tuning
- - prefix_tuning True
## lora
- - lora_adapter True
## ConvAdapter
- - trans_adapter_name "adapterblock"
- - output_adapter TrueTambém colocamos exemplos de acordo com cada método de treinamento em "Emotion_Cls.sh", usando o seguinte comando para iniciar uma nova tarefa de classificação de emoção:
bash emotion_cls . sh Para supervisionar ainda mais a convergência do treinamento do modelo, podemos visualizar o arquivo de log através do Tensorboard:
tensorboard - - logdir = / data / path / output_earlystop_asr_fleurs_lora_2e3 / log - - bind_all @ inproceedings { li2023evaluating ,
title = { Evaluating Parameter - Efficient Transfer Learning Approaches on SURE Benchmark for Speech Understanding },
author = { Li , Yingting and Mehrish , Ambuj and Zhao , Shuai and Bhardwaj , Rishabh and Zadeh , Amir and Majumder , Navonil and Mihalcea , Rada and Poria , Soujanya },
booktitle = { ICASSP },
year = { 2023 }
}NOTA: Cite nosso artigo se achar útil este repositório.


