speech adapters
1.0.0
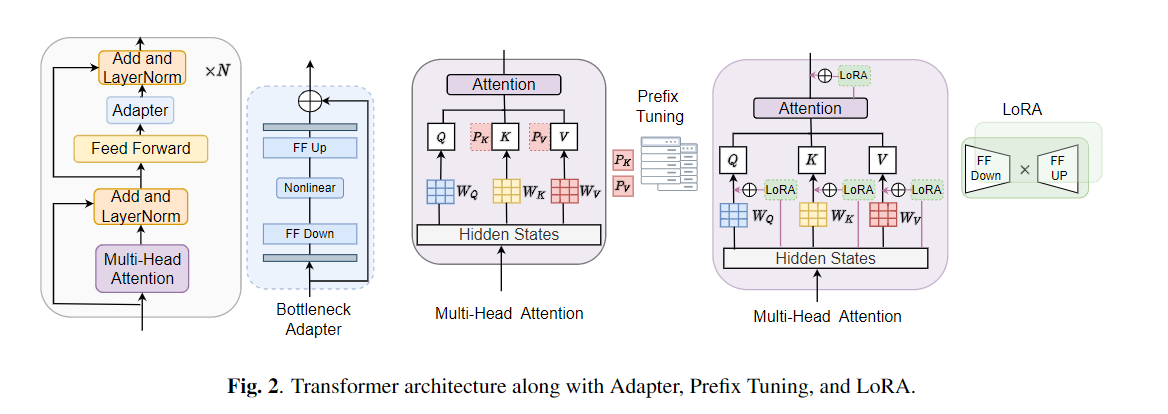
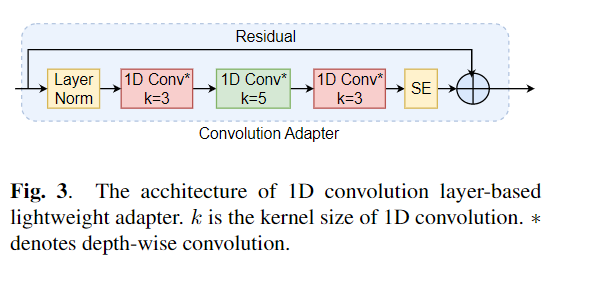
Fine-tuning is widely used as the default algorithm for transfer learning from pre-trained models. Parameter inefficiency can however arise when, during transfer learning, all the parameters of a large pre-trained model need to be updated for individual downstream tasks. As the number of parameters grows, fine-tuning is prone to overfitting and catastrophic forgetting. In addition, full fine-tuning can become prohibitively expensive when the model is used for many tasks. To mitigate this issue, parameter-efficient transfer learning algorithms, such as adapters and prefix tuning, have been proposed as a way to introduce a few trainable parameters that can be plugged into large pre-trained language models such as BERT, and HuBERT. In this paper, we introduce the Speech UndeRstanding Evaluation (SURE) benchmark for parameter-efficient learning for various speech-processing tasks. Additionally, we introduce a new adapter, ConvAdapter, based on 1D convolution. We show that ConvAdapter outperforms the standard adapters while showing comparable performance against prefix tuning and LoRA with only 0.94% of trainable parameters on some of the tasks in SURE. We further explore the effectiveness of parameter efficient transfer learning for speech synthesis task such as Text-to-Speech (TTS).
conda create --name speechprompt python==3.8.5
conda activate speechprompt
conda install pytorch==1.10.0 torchvision==0.11.0 torchaudio==0.10.0 -c pytorchpip install -r requirements.txt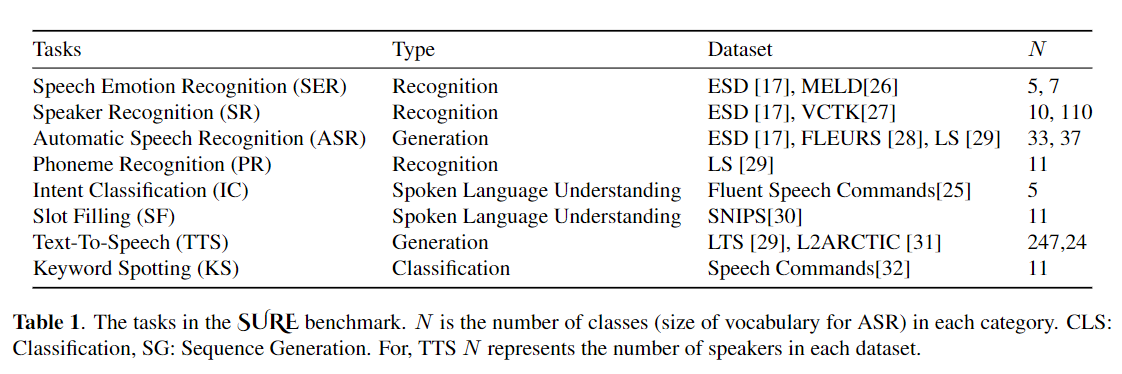
First, we need to specify datasets and arguments. let's use "esd" as the dataset, "finetune" as the tuning method in "speech emotion recognition" task as an example:
CUDA_VISIBLE_DEVICES=2,3 python train.py
--dataset "esd"
--data_dir "/data/path/ESD"
--output_dir '/data/path/output_earlystop_ser_esd_finetune_2e3'
--do_train True
--do_eval True
--do_predict False
--evaluation_strategy "steps"
--save_strategy "steps"
--save_steps 500
--eval_steps 25
--learning_rate 2e-3
--feat_adapter_name "conv_adapter"
--trans_adapter_name "adapterblock"
--output_adapter False
--mh_adapter False
--prefix_tuning False
--lora_adapter False
--feat_enc_adapter False
--fine_tune True
--per_device_train_batch_size 64
--gradient_accumulation_steps 4
--per_device_eval_batch_size 64
--num_train_epochs 100
--warmup_ratio 0.1
--logging_steps 20
--logging_dir '/data/path/output_earlystop_ser_esd_finetune_2e3/log'
--load_best_model_at_end True
--metric_for_best_model "f1" Let's further explain the five training methods of the model. For example, start a new emotion classification task, we will set the corresponding parameter like below:
## finetune
--fine_tune True
## bottleneck
--trans_adapter_name "bottleneck"
--output_adapter True
## prefix-tuning
--prefix_tuning True
## lora
--lora_adapter True
## ConvAdapter
--trans_adapter_name "adapterblock"
--output_adapter TrueWe also placed examples according to each training method in "emotion_cls.sh", using the following command to start new emotion classification task:
bash emotion_cls.shIn order to further supervise the convergence of model training, we can view the log file through Tensorboard:
tensorboard --logdir=/data/path/output_earlystop_asr_fleurs_lora_2e3/log --bind_all@inproceedings{li2023evaluating,
title={Evaluating Parameter-Efficient Transfer Learning Approaches on SURE Benchmark for Speech Understanding},
author={Li, Yingting and Mehrish, Ambuj and Zhao, Shuai and Bhardwaj, Rishabh and Zadeh, Amir and Majumder, Navonil and Mihalcea, Rada and Poria, Soujanya},
booktitle={ICASSP},
year={2023}
}Note: Please cite our paper if you find this repository useful.


