speech adapters
1.0.0
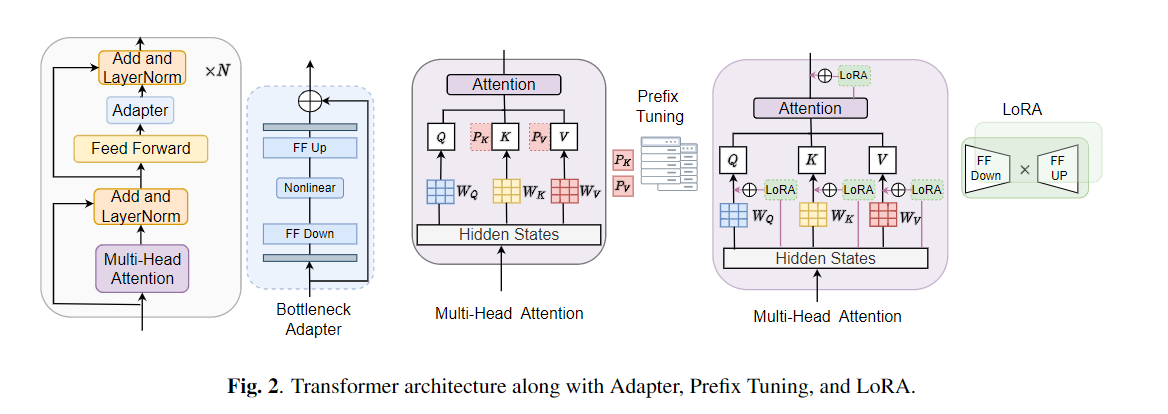
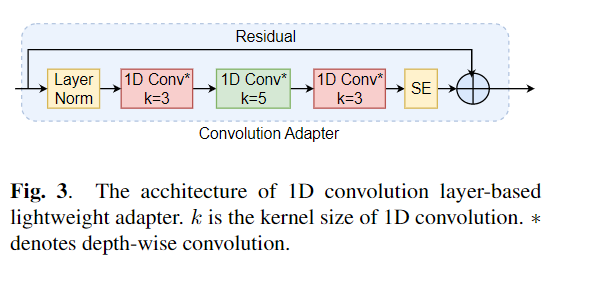
미세 조정은 미리 훈련 된 모델에서 전송 학습을위한 기본 알고리즘으로 널리 사용됩니다. 그러나 전송 학습 중에 대규모 미리 훈련 된 모델의 모든 매개 변수를 개별 다운 스트림 작업에 대해 업데이트해야 할 때 매개 변수 비 효율성이 발생할 수 있습니다. 매개 변수의 수가 증가함에 따라 미세 조정은 과적으로 적합하고 치명적인 잊어 버리기 쉽습니다. 또한 모델이 많은 작업에 사용될 때 완전 미세 조정이 엄청나게 비싸 질 수 있습니다. 이 문제를 완화하기 위해 어댑터 및 접두사 튜닝과 같은 매개 변수 효율적인 전송 학습 알고리즘이 Bert 및 Hubert와 같은 대규모 미리 훈련 된 언어 모델에 연결할 수있는 몇 가지 훈련 가능한 매개 변수를 도입하는 방법으로 제안되었습니다. 이 논문에서는 다양한 음성 처리 작업에 대한 매개 변수 효율적인 학습을위한 Speech Inderning Evaluation (Sure) 벤치 마크를 소개합니다. 또한 1D 컨볼 루션을 기반으로 새로운 어댑터 인 Convadapter를 소개합니다. 우리는 Convadapter가 표준 어댑터보다 우수한 것으로 나타 났으며 Prefix 튜닝 및 LORA에 대해 비슷한 성능을 보여줍니다. 우리는 TTS (Text-To-Steece)와 같은 음성 합성 작업에 대한 매개 변수 효율적인 전송 학습의 효과를 더 탐구합니다.
conda create - - name speechprompt python == 3.8 . 5
conda activate speechprompt
conda install pytorch == 1.10 . 0 torchvision == 0.11 . 0 torchaudio == 0.10 . 0 - c pytorch pip install - r requirements . txt 
먼저 데이터 세트 및 인수를 지정해야합니다. "ESD"를 데이터 세트로 사용하여 "Finetune"을 "음성 감정 인식"작업의 튜닝 방법으로 사용하겠습니다.
CUDA_VISIBLE_DEVICES = 2 , 3 python train . py
- - dataset "esd"
- - data_dir "/data/path/ESD"
- - output_dir '/data/path/output_earlystop_ser_esd_finetune_2e3'
- - do_train True
- - do_eval True
- - do_predict False
- - evaluation_strategy "steps"
- - save_strategy "steps"
- - save_steps 500
- - eval_steps 25
- - learning_rate 2e-3
- - feat_adapter_name "conv_adapter"
- - trans_adapter_name "adapterblock"
- - output_adapter False
- - mh_adapter False
- - prefix_tuning False
- - lora_adapter False
- - feat_enc_adapter False
- - fine_tune True
- - per_device_train_batch_size 64
- - gradient_accumulation_steps 4
- - per_device_eval_batch_size 64
- - num_train_epochs 100
- - warmup_ratio 0.1
- - logging_steps 20
- - logging_dir '/data/path/output_earlystop_ser_esd_finetune_2e3/log'
- - load_best_model_at_end True
- - metric_for_best_model "f1" 모델의 5 가지 훈련 방법을 설명해 봅시다. 예를 들어, 새로운 감정 분류 작업을 시작하면 다음과 같은 해당 매개 변수를 설정합니다.
## finetune
- - fine_tune True
## bottleneck
- - trans_adapter_name "bottleneck"
- - output_adapter True
## prefix-tuning
- - prefix_tuning True
## lora
- - lora_adapter True
## ConvAdapter
- - trans_adapter_name "adapterblock"
- - output_adapter True또한 새로운 감정 분류 작업을 시작하기 위해 다음 명령을 사용하여 "감정 _cls.sh"의 각 교육 방법에 따라 예제를 배치했습니다.
bash emotion_cls . sh 모델 교육의 수렴을 추가로 감독하기 위해 Tensorboard를 통해 로그 파일을 볼 수 있습니다.
tensorboard - - logdir = / data / path / output_earlystop_asr_fleurs_lora_2e3 / log - - bind_all @ inproceedings { li2023evaluating ,
title = { Evaluating Parameter - Efficient Transfer Learning Approaches on SURE Benchmark for Speech Understanding },
author = { Li , Yingting and Mehrish , Ambuj and Zhao , Shuai and Bhardwaj , Rishabh and Zadeh , Amir and Majumder , Navonil and Mihalcea , Rada and Poria , Soujanya },
booktitle = { ICASSP },
year = { 2023 }
}참고 :이 저장소가 유용하다고 생각되면 우리 논문을 인용하십시오.


