OSM one shot multispeaker
1.0.0
单发多扬声器文本到语音(OS MS TTS)系统的目的是将文本转换为用小样本确定的语音的语音。这里的主要问题是在不重述网络的情况下重现新的看不见的声音。有三个主要阶段的方法用于解决此问题。在第一阶段生成的每个语音扬声器嵌入的独特嵌入(示出语音特征)(扬声器编码器)。在第二阶段(合成器),使用先前获得的嵌入将文本转化为MEL-SECTROGRAM。最后,语音是从Mel-Spectrograpon与Vocoder复制的。但是,正确组合这三个部分缺乏实现。因此,我们项目的目标是创建一个灵活的框架,以组合这些零件并在每个部分中提供可更换的模块和方法。
到目前为止,我们看到以下主要挑战:
我们选择讲师提出的解决方案作为基线,可以在此处找到。这是2018年在Google中制造的[1]的实现。在这里,作者使用[2]中介绍的扬声器编码器,该编码器生成了固定维嵌入向量,称为d-vector。至于合成器,他们使用基于Tacotron 2 [3]的模型,而基于自动回归的WaveNet的模型则用作Vocoder [4]。从[1]拍摄的以下图像表示模型概述: 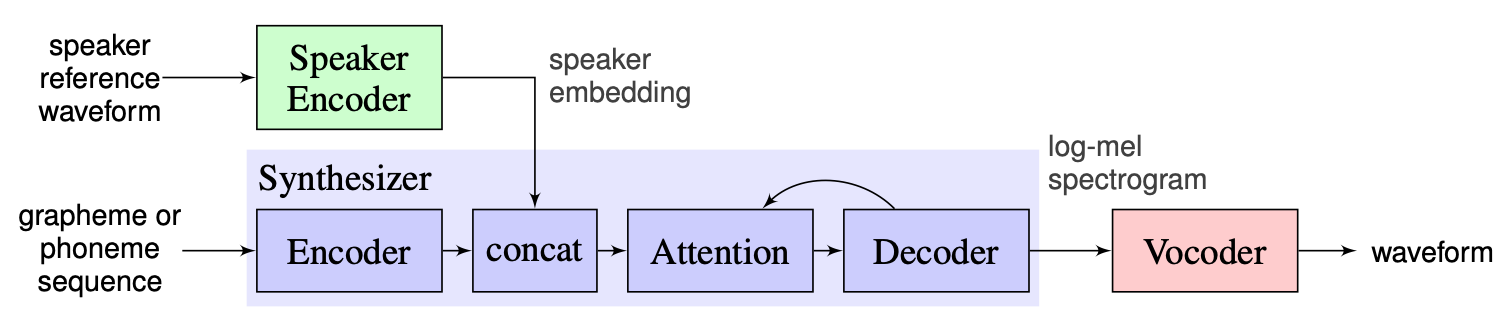
实时声音键合包含编码器,Tacotron 2和Wavernn的实现。 [1]中描述的整个管道,包括预处理步骤,在此存储库中也实现。但是,该项目还不够灵活。更具体地说,在当前状态下,它不能用作单发多演讲者文本到语音系统的框架,因为没有方便的机制可以用三个主模块来操纵。例如,[5]中的拟议的多扬声器TTS系统无法在实时访问的帮助下轻松实现,因为没有可扩展的点可以调整新方法的管道。
我们的计划是使用实现的基线使用实时派遣点键合作点。我们将介绍框架的灵活模块化设计。这种方法将帮助我们为外部用户创建方便的API,他们将能够使用我们的框架将多扬声器TTS系统纳入其产品中。 API还将让用户自定义模块和管道步骤,而无需在需要时更改框架的源代码。我们将实施几个发言人编码器(LDE,TDNN),并将它们添加到我们的框架中。
从高点来看,我们的项目包括3个主要要素:扬声器编码器,合成器,Vocoder。对于他们每个人,都将实施一个经理,允许人们访问参数并执行标准操作,例如推理和培训。在它们上方,我们实施了OS MS TTS Manager,该管理器将所有三个部分汇总在一起,并允许一个人制作所有管道并用所需的语音产生语音。这些部分中的每一个都由相应元素的典型基本子零件组成。它们可以描述如下:
在我们的存储库中,我们添加了笔记本电脑,可以在其中上传语音音频,.txt文件并用克隆的语音产生语音。尽管预算模型的权重自动在第一次运行时自动下载,但用户仍然可以下载存档,此处的其他说明在此处的笔记本中
Nikolay将设计模块化体系结构,用于外部使用和培训管道的API。 gleb将实施模型,编写文档和用法示例的工作堆栈。
.
└── osms
├── __init__.py
├── common
│ ├── __init__.py
│ ├── configs
│ │ ├── __init__.py
│ │ ├── config.py
│ │ └── main_config.yaml
│ └── multispeaker.py
├── main.py
├── tts_modules
│ ├── __init__.py
│ ├── encoder
│ │ ├── __init__.py
│ │ ├── configs
│ │ │ ├── AudioConfig.yaml
│ │ │ ├── __init__.py
│ │ │ ├── config.py
│ │ │ └── dVecModelConfig.yaml
│ │ ├── data
│ │ │ ├── DataObjects.py
│ │ │ ├── __init__.py
│ │ │ ├── dataset.py
│ │ │ ├── wav2mel.py
│ │ │ └── wav_preprocessing.py
│ │ ├── models
│ │ │ ├── __init__.py
│ │ │ └── dVecModel.py
│ │ ├── speaker_encoder_manager.py
│ │ └── utils
│ │ ├── Trainer.py
│ │ └── __init__.py
│ ├── synthesizer
│ │ ├── LICENSE.md
│ │ ├── __init__.py
│ │ ├── configs
│ │ │ ├── __init__.py
│ │ │ ├── config.py
│ │ │ ├── hparams.py
│ │ │ └── tacotron_config.yaml
│ │ ├── data
│ │ │ ├── __init__.py
│ │ │ ├── audio.py
│ │ │ ├── dataset.py
│ │ │ └── preprocess.py
│ │ ├── models
│ │ │ ├── __init__.py
│ │ │ └── tacotron.py
│ │ ├── synthesize.py
│ │ ├── synthesizer_manager.py
│ │ ├── trainer.py
│ │ └── utils
│ │ ├── __init__.py
│ │ ├── cleaners.py
│ │ ├── logmmse.py
│ │ ├── numbers.py
│ │ ├── plot.py
│ │ ├── symbols.py
│ │ └── text.py
│ ├── tts_module_manager.py
│ └── vocoder
│ ├── __init__.py
│ ├── configs
│ │ ├── __init__.py
│ │ ├── config.py
│ │ ├── hparams.py
│ │ └── wavernn_config.yaml
│ ├── data
│ │ ├── __init__.py
│ │ ├── dataset.py
│ │ └── preprocess.py
│ ├── models
│ │ ├── __init__.py
│ │ └── wavernn.py
│ ├── utils
│ │ ├── Trainer.py
│ │ ├── __init__.py
│ │ ├── audio.py
│ │ ├── distribution.py
│ │ └── gen_wavernn.py
│ └── vocoder_manager.py
└── utils
└── __init__.py运行pip3 install .从根目录。
我们已经针对扬声器编码器,合成器和Vocoder实施了libraspeech数据集的完整处理。可以通过此链接下载Libraspeech数据集。另外,对于扬声器编码器,我们实现了使用自定义数据集的接口。一个人需要实现PreprocessDataset界面接口函数, WavPreprocessor接口函数, WavPreprocessor接口函数或使用实现的函数。
对于基线模型,默认配置将自动加载。要更改它们,可以在osms/common/configs/config.py中使用update_config(...) 。要加载默认配置,可以使用get_default_<module_name>_config(...) 。另外,人们可以实现自己的配置将其用于其他型号。
要与每个三个模块一起工作,我们实现了自己的经理: SpeakerEncoderManager , SynthesizerManager , VocoderManager 。作为主要经理,我们实施了MustiSpreakerManager ,该管理员可以访问所有三位经理。可以使用它们来推断整个TTS模型,并分别或一起训练每个模块。用法的示例可以在笔记本中找到。
基线检查点会在checkpoints目录中自动下载,并创建“ MultiSpeaker”对象。另外,可以通过简单更新配置(更改... checkpoint_dir_path,checkpoint_name)来使用其他检查点。


