OSM one shot multispeaker
1.0.0
Los sistemas de texto a voz de múltiples altavoces (OS MS TTS) tienen como objetivo transformar el texto en voz con voz determinada por una pequeña muestra única. El principal problema aquí es reproducir la nueva voz invisible sin volver a capacitar la red. Hay un enfoque con tres etapas principales que se utiliza para resolver este problema. Los únicos para cada altavoz de voz, que revelan las características de la voz, se generan en la primera etapa ( codificador de altavoces ). En la segunda etapa ( sintetizador ), el texto se transforma en espectrograma MEL utilizando incrustaciones previamente obtenidas. Finalmente, el discurso se reproduce del espectrograma MEL con el vocoder . Pero hay falta de implementaciones con estas tres partes correctamente combinadas. Entonces, el objetivo de nuestro proyecto es crear un marco flexible para combinar estas partes y proporcionar módulos y métodos reemplazables en cada parte.
A estas alturas vemos los siguientes desafíos principales:
Elegimos la solución propuesta por los instructores como línea de base, que se puede encontrar aquí. Es la implementación de [1] realizada en Google en 2018. Aquí los autores usan el codificador del altavoz, presentado en [2], que genera un vector de incrustación de dimensión fija conocido como Vector D. En cuanto al sintetizador, usan el modelo basado en Tacotron 2 [3], mientras que un wavenet autoregresivo basado en Wavenet se usa como Vocoder [4]. La siguiente imagen tomada de [1] representa la descripción general del modelo: 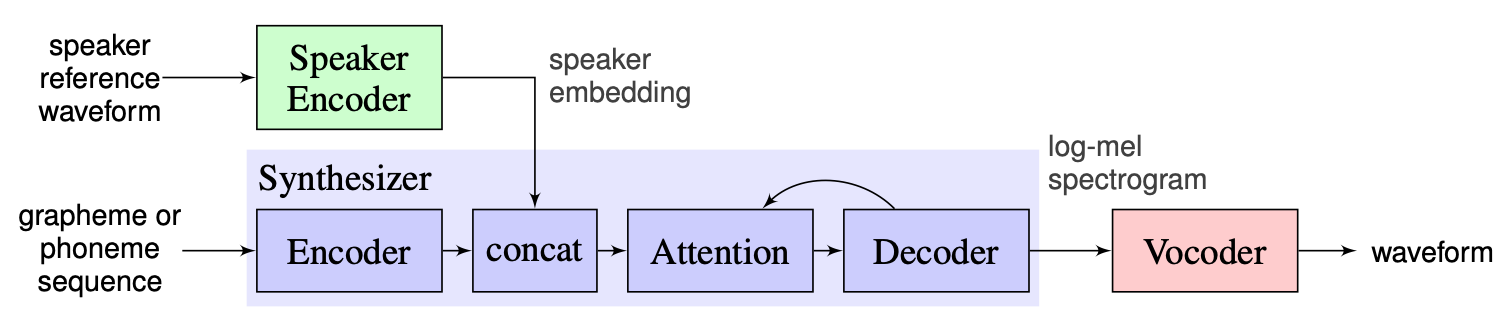
La clonación de la voz real contiene las realizaciones del codificador, Tacotron 2 y Wavernn. Toda la tubería descrita en [1], incluidos los pasos de preprocesamiento, también se implementa en este repositorio. Sin embargo, el proyecto no es lo suficientemente flexible. Más específicamente, en el estado actual no puede usarse como el marco para el sistema de texto a voz múltiple de un solo disparo, ya que no hay mecanismos convenientes para manipular con los tres módulos principales. Por ejemplo, el sistema TTS múltiple propuesto en [5] no se puede implementar fácilmente con la ayuda de la clonación de voz en tiempo real, ya que no hay puntos de extensibilidad que permitan ajustar la tubería para el nuevo método.
Nuestro plan es usar la clonación de voz en tiempo real como punto de partida con la línea de base implementada. Introduciremos el diseño modular flexible del marco. Dicho enfoque nos ayudará a crear la API conveniente para usuarios externos que podrán utilizar nuestro marco para incorporar el sistema TTS de múltiples altavoces en sus productos. La API también permitirá a los usuarios personalizar los módulos y los pasos de la tubería sin cambiar el código fuente del marco si es necesario. Implementaremos varios codificadores de altavoces (LDE, TDNN) y también los agregaremos a nuestro marco.
Desde un punto más alto, nuestro proyecto consta de 3 elementos principales: codificador de altavoces, sintetizador, vocoder. Para cada uno de ellos, se implementa un gerente que permite acceder a los parámetros y realizar acciones estándar como inferencia y capacitación. Por encima de ellos, implementamos OS MS TTS Manager, que reúne las tres partes y le permite a uno hacer toda la tubería y producir discurso con la voz necesaria. Cada una de estas partes también consiste en subpartes elementales típicos para los elementos correspondientes. Se pueden describir de la siguiente manera:
En nuestro repositorio agregamos cuaderno, donde se puede cargar el audio de voz, el archivo .txt y producir discurso con voz clonada. A pesar de los pesos de los modelos previos a la aparición, se descargan automáticamente en la primera ejecución, el usuario aún puede descargar archivo aquí otras instrucciones están en el cuaderno aquí
Nikolay diseñará la arquitectura modular, API para uso externo y tuberías de capacitación. GLEB implementará la pila de trabajo de modelos, documentos de escritura y ejemplos de uso.
.
└── osms
├── __init__.py
├── common
│ ├── __init__.py
│ ├── configs
│ │ ├── __init__.py
│ │ ├── config.py
│ │ └── main_config.yaml
│ └── multispeaker.py
├── main.py
├── tts_modules
│ ├── __init__.py
│ ├── encoder
│ │ ├── __init__.py
│ │ ├── configs
│ │ │ ├── AudioConfig.yaml
│ │ │ ├── __init__.py
│ │ │ ├── config.py
│ │ │ └── dVecModelConfig.yaml
│ │ ├── data
│ │ │ ├── DataObjects.py
│ │ │ ├── __init__.py
│ │ │ ├── dataset.py
│ │ │ ├── wav2mel.py
│ │ │ └── wav_preprocessing.py
│ │ ├── models
│ │ │ ├── __init__.py
│ │ │ └── dVecModel.py
│ │ ├── speaker_encoder_manager.py
│ │ └── utils
│ │ ├── Trainer.py
│ │ └── __init__.py
│ ├── synthesizer
│ │ ├── LICENSE.md
│ │ ├── __init__.py
│ │ ├── configs
│ │ │ ├── __init__.py
│ │ │ ├── config.py
│ │ │ ├── hparams.py
│ │ │ └── tacotron_config.yaml
│ │ ├── data
│ │ │ ├── __init__.py
│ │ │ ├── audio.py
│ │ │ ├── dataset.py
│ │ │ └── preprocess.py
│ │ ├── models
│ │ │ ├── __init__.py
│ │ │ └── tacotron.py
│ │ ├── synthesize.py
│ │ ├── synthesizer_manager.py
│ │ ├── trainer.py
│ │ └── utils
│ │ ├── __init__.py
│ │ ├── cleaners.py
│ │ ├── logmmse.py
│ │ ├── numbers.py
│ │ ├── plot.py
│ │ ├── symbols.py
│ │ └── text.py
│ ├── tts_module_manager.py
│ └── vocoder
│ ├── __init__.py
│ ├── configs
│ │ ├── __init__.py
│ │ ├── config.py
│ │ ├── hparams.py
│ │ └── wavernn_config.yaml
│ ├── data
│ │ ├── __init__.py
│ │ ├── dataset.py
│ │ └── preprocess.py
│ ├── models
│ │ ├── __init__.py
│ │ └── wavernn.py
│ ├── utils
│ │ ├── Trainer.py
│ │ ├── __init__.py
│ │ ├── audio.py
│ │ ├── distribution.py
│ │ └── gen_wavernn.py
│ └── vocoder_manager.py
└── utils
└── __init__.py Ejecute pip3 install . Del directorio raíz.
Hemos implementado un procesamiento completo para el conjunto de datos de LibraSpeech para el codificador de altavoces, el sintetizador y el vocoder. Se puede descargar el conjunto de datos de LibraSpeech a través de este enlace. Además, para el codificador de altavoces implementamos la interfaz para usar el conjunto de datos personalizado. Uno necesita implementar funciones de interfaz PreprocessDataset , funciones de interfaz WavPreprocessor , funciones de interfaz WavPreprocessor o usar las implementadas.
Para los modelos de referencia, las configuraciones predeterminadas se cargarán automáticamente. Para cambiarlos, se puede usar update_config(...) en osms/common/configs/config.py . Para cargar la configuración predeterminada, uno puede usar get_default_<module_name>_config(...) . Además, uno puede implementar sus propias configuraciones para usarlas para otros modelos.
Para trabajar con cada tres módulos, implementamos su propio gerente: SpeakerEncoderManager , SynthesizerManager , VocoderManager . Como gerente principal, implementamos MustiSpreakerManager que dan acceso a los tres gerentes. Uno puede usarlos para inferir todo el modelo TTS y entrenar cada módulos por separado o juntos. El ejemplo de uso se puede encontrar en el cuaderno.
Los puntos de control de línea de base se descargan automáticamente en el directorio checkpoints con la creación del objeto 'multiespeaker'. Además, uno puede usar otros puntos de control mediante la actualización simple de config (cambiar ... checkpoint_dir_path, checkpoint_name).


