OSM one shot multispeaker
1.0.0
Les systèmes de texte à dispection multi-uns-uns-uns (OS MS TTS) visent à transformer le texte en parole avec une voix déterminée par un petit échantillon unique. Le principal problème ici est de reproduire la nouvelle voix invisible sans recycler le réseau. Il y a une approche avec trois étapes principales qui est utilisée pour résoudre ce problème. L'unique pour chaque embarcation de haut-parleur vocale, qui révèle les caractéristiques vocales, sont générés au premier stade ( encodeur d'enceintes ). À la deuxième étape ( synthétiseur ), le texte est transformé en spectrogramme MEL en utilisant des intérêts précédemment obtenus. Enfin, le discours est reproduit à partir du spectrogramme MEL avec le vocodeur . Mais il y a un manque d'implémentations avec ces trois parties correctement combinées. L'objectif de notre projet est donc de créer un cadre flexible pour combiner ces pièces et fournir des modules et méthodes remplaçables dans chaque partie.
Nous voyons maintenant les principaux défis suivants:
Nous choisissons la solution proposée par les instructeurs comme référence, qui peut être trouvée ici. Il s'agit de l'implémentation de [1] fabriquée dans Google en 2018. Ici, les auteurs utilisent le codeur de haut-parleur, présenté dans [2], qui génère un vecteur d'incorporation fixe connu sous le nom de vecteur D. Quant au synthétiseur, ils utilisent un modèle basé sur le tacotron 2 [3] tandis qu'un wavenet auto-régressif basé sur un wavenet est utilisé comme vocodeur [4]. L'image suivante tirée de [1] représente la vue d'ensemble du modèle: 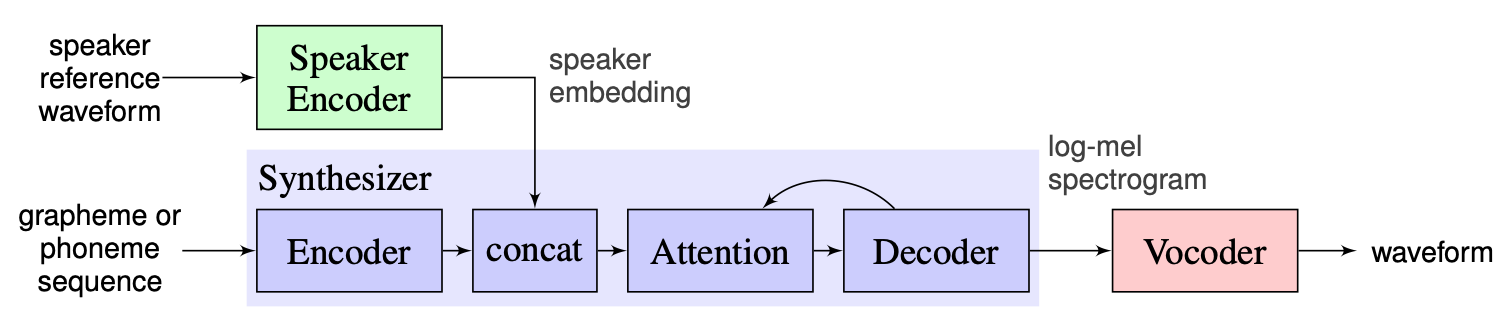
La clonage de voix en temps réel contient les réalisations de l'encodeur, du tacotron 2 et du wavernn. L'ensemble du pipeline décrit dans [1], y compris les étapes de prétraitement, est également implémenté dans ce référentiel. Cependant, le projet n'est pas assez flexible. Plus précisément, dans l'état actuel, il ne peut pas être utilisé comme cadre pour le système de texte à la parole multi-uns-uns-paroles car il n'y a pas de mécanismes pratiques pour manipuler avec les trois modules principaux. Par exemple, le système TTS multi-haut-parleurs proposé dans [5] ne peut pas être facilement mis en œuvre à l'aide de la clonage en temps réel, car il n'y a pas de points d'extensibilité qui permettent d'ajuster le pipeline pour la nouvelle méthode.
Notre plan est d'utiliser le clonage en temps réel comme point de départ avec la ligne de base implémentée. Nous présenterons la conception modulaire flexible du cadre. Cette approche nous aidera à créer l'API pratique pour les utilisateurs externes qui pourront utiliser notre cadre pour incorporer le système TTS multi-haut-parleurs dans leurs produits. L'API permettra également aux utilisateurs de personnaliser les modules et les étapes de pipeline sans modifier le code source du cadre si nécessaire. Nous implémenterons plusieurs encodeurs de haut-parleurs (LDE, TDNN) et les ajouterons également à notre cadre.
À partir d'un point culminant, notre projet se compose de 3 éléments principaux: Encodeur de haut-parleur, synthétiseur, vocodeur. Pour chacun d'eux, un gestionnaire est implémenté qui permet d'accéder aux paramètres et d'effectuer des actions standard telles que l'inférence et la formation. Au-dessus d'eux, nous avons implémenté OS MS TTS Manager, qui rassemble les trois parties et permet de faire tout le pipeline et de produire une parole avec la voix nécessaire. Chacune de ces pièces est également composée de sous-parties élémentaires typiques des éléments correspondants. Ils peuvent être décrits comme suit:
Dans notre référentiel, nous avons ajouté un cahier, où l'on peut télécharger l'audio vocal, un fichier .txt et produire un discours avec une voix clonée. Malgré les poids des modèles pré-entraînés téléchargés automatiquement lors de la première exécution, l'utilisateur peut toujours télécharger des archives ici, d'autres instructions sont dans le cahier ici
Nikolay concevra l'architecture modulaire, API pour l'utilisation externe et le pipeline de formation. GleB implémentera la pile de travail de modèles, d'écriture de documents et d'exemples d'utilisation.
.
└── osms
├── __init__.py
├── common
│ ├── __init__.py
│ ├── configs
│ │ ├── __init__.py
│ │ ├── config.py
│ │ └── main_config.yaml
│ └── multispeaker.py
├── main.py
├── tts_modules
│ ├── __init__.py
│ ├── encoder
│ │ ├── __init__.py
│ │ ├── configs
│ │ │ ├── AudioConfig.yaml
│ │ │ ├── __init__.py
│ │ │ ├── config.py
│ │ │ └── dVecModelConfig.yaml
│ │ ├── data
│ │ │ ├── DataObjects.py
│ │ │ ├── __init__.py
│ │ │ ├── dataset.py
│ │ │ ├── wav2mel.py
│ │ │ └── wav_preprocessing.py
│ │ ├── models
│ │ │ ├── __init__.py
│ │ │ └── dVecModel.py
│ │ ├── speaker_encoder_manager.py
│ │ └── utils
│ │ ├── Trainer.py
│ │ └── __init__.py
│ ├── synthesizer
│ │ ├── LICENSE.md
│ │ ├── __init__.py
│ │ ├── configs
│ │ │ ├── __init__.py
│ │ │ ├── config.py
│ │ │ ├── hparams.py
│ │ │ └── tacotron_config.yaml
│ │ ├── data
│ │ │ ├── __init__.py
│ │ │ ├── audio.py
│ │ │ ├── dataset.py
│ │ │ └── preprocess.py
│ │ ├── models
│ │ │ ├── __init__.py
│ │ │ └── tacotron.py
│ │ ├── synthesize.py
│ │ ├── synthesizer_manager.py
│ │ ├── trainer.py
│ │ └── utils
│ │ ├── __init__.py
│ │ ├── cleaners.py
│ │ ├── logmmse.py
│ │ ├── numbers.py
│ │ ├── plot.py
│ │ ├── symbols.py
│ │ └── text.py
│ ├── tts_module_manager.py
│ └── vocoder
│ ├── __init__.py
│ ├── configs
│ │ ├── __init__.py
│ │ ├── config.py
│ │ ├── hparams.py
│ │ └── wavernn_config.yaml
│ ├── data
│ │ ├── __init__.py
│ │ ├── dataset.py
│ │ └── preprocess.py
│ ├── models
│ │ ├── __init__.py
│ │ └── wavernn.py
│ ├── utils
│ │ ├── Trainer.py
│ │ ├── __init__.py
│ │ ├── audio.py
│ │ ├── distribution.py
│ │ └── gen_wavernn.py
│ └── vocoder_manager.py
└── utils
└── __init__.py Exécutez pip3 install . du répertoire racine.
Nous avons implémenté le traitement complet de l'ensemble de données LibrassEech pour l'encodeur de haut-parleur, le synthétiseur et le vocodeur. On peut télécharger le jeu de données LibraspeEch via ce lien. De plus, pour l'encodeur de haut-parleur, nous avons implémenté l'interface pour utiliser un ensemble de données personnalisé. Il faut implémenter les fonctions d'interface PreprocessDataset , les fonctions d'interface WavPreprocessor , les fonctions d'interface WavPreprocessor ou utiliser des fonctions implémentées.
Pour les modèles de base, les configurations par défaut seront chargées automatiquement. Pour les modifier, on peut utiliser update_config(...) dans osms/common/configs/config.py . Pour charger la configuration par défaut, on peut utiliser get_default_<module_name>_config(...) . De plus, on peut implémenter ses propres configurations pour les utiliser pour d'autres modèles.
Pour travailler avec chaque trois modules, nous avons mis en œuvre son propre manager: SpeakerEncoderManager , SynthesizerManager , VocoderManager . En tant que gestionnaire principal, nous avons mis en œuvre MustiSpreakerManager qui donnent accès aux trois managers. On peut les utiliser pour inférer l'ensemble du modèle TTS et former chaque module séparément ou ensemble. L'exemple d'utilisation se trouve dans le cahier.
Les points de contrôle de base sont téléchargés automatiquement dans le répertoire checkpoints avec la création de l'objet «multispeaker». De plus, on peut utiliser d'autres points de contrôle par simple mise à jour de la configuration (modifier ... Checkpoint_dir_path, Checkpoint_name).


