OSM one shot multispeaker
1.0.0
Sistem Multi-Speaker Text-to-Speech (OS MS TTS) bertujuan untuk mengubah teks menjadi ucapan dengan suara yang ditentukan oleh sampel tunggal kecil. Masalah utama di sini adalah mereproduksi suara baru yang tak terlihat tanpa melatih kembali jaringan. Ada pendekatan dengan tiga tahap utama yang digunakan untuk menyelesaikan masalah ini. Unik untuk setiap embeddings speaker suara, yang mengungkapkan karakteristik suara, dihasilkan pada tahap pertama ( speaker encoder ). Pada tahap kedua ( synthesizer ) teks ditransformasikan menjadi mel-spectrogram menggunakan embeddings yang diperoleh sebelumnya. Akhirnya, pidato direproduksi dari Mel-Spectrogram dengan vocoder . Tetapi ada kurangnya implementasi dengan ketiga bagian ini digabungkan dengan benar. Jadi tujuan dari proyek kami adalah untuk membuat kerangka kerja yang fleksibel untuk menggabungkan bagian -bagian ini dan menyediakan modul dan metode yang dapat diganti di setiap bagian.
Sekarang kita melihat tantangan utama berikut:
Kami memilih solusi yang diusulkan oleh instruktur sebagai garis dasar, yang dapat ditemukan di sini. Ini adalah implementasi [1] yang dibuat di Google pada tahun 2018. Di sini penulis menggunakan encoder pembicara, disajikan dalam [2], yang menghasilkan vektor embedding dimensi tetap yang dikenal sebagai D-vektor. Sedangkan untuk synthesizer mereka menggunakan model berdasarkan Tacotron 2 [3] sementara berbasis Wavenet Auto-Regressive digunakan sebagai vocoder [4]. Gambar berikut yang diambil dari [1] mewakili ikhtisar model: 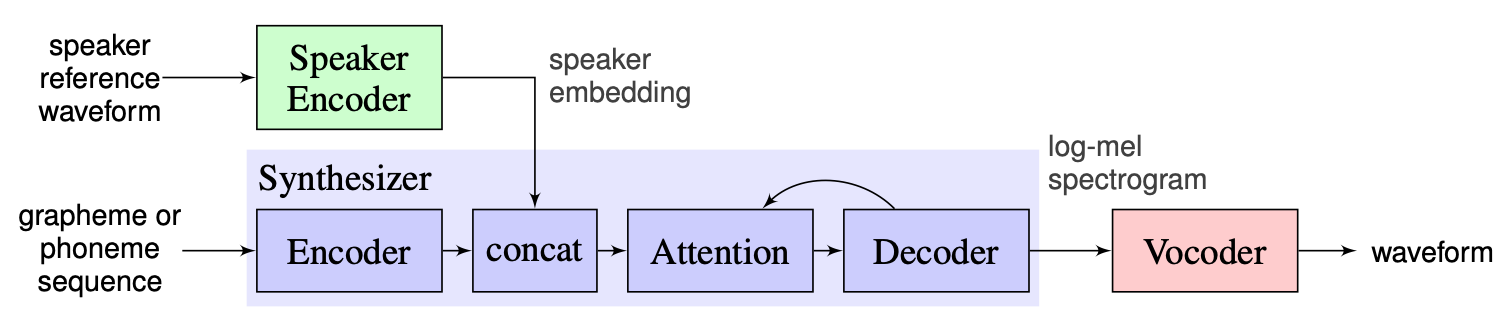
Kloning voice-time-real-time berisi realisasi Encoder, Tacotron 2 dan Wavernn. Seluruh pipa yang dijelaskan dalam [1], termasuk langkah -langkah preprocessing, juga diimplementasikan dalam repositori ini. Namun, proyek ini tidak cukup fleksibel. Lebih khusus lagi, dalam kondisi saat ini tidak dapat digunakan sebagai kerangka kerja untuk sistem teks-ke-speech multi-speake satu-shot karena tidak ada mekanisme yang nyaman untuk memanipulasi dengan tiga modul utama. Misalnya, sistem TTS multi-speaker yang diusulkan di [5] tidak dapat dengan mudah diimplementasikan dengan bantuan kloning voice-time-real-time karena tidak ada titik ekstensibilitas yang memungkinkan untuk menyesuaikan pipa untuk metode baru.
Rencana kami adalah menggunakan kloning voice-time-real-time sebagai titik awal dengan baseline yang diimplementasikan. Kami akan memperkenalkan desain modular yang fleksibel dari kerangka kerja. Pendekatan semacam itu akan membantu kami membuat API yang nyaman untuk pengguna eksternal yang akan dapat menggunakan kerangka kerja kami untuk memasukkan sistem TTS multi-speaker dalam produk mereka. API juga akan membiarkan pengguna menyesuaikan modul dan langkah pipa tanpa mengubah kode sumber kerangka kerja jika diperlukan. Kami akan mengimplementasikan beberapa Encoder Pembicara (LDE, TDNN) dan menambahkannya ke kerangka kerja kami juga.
Dari titik tertinggi, proyek kami terdiri dari 3 elemen utama: pembicara encoder, synthesizer, vocoder. Untuk masing -masing dari mereka, seorang manajer diimplementasikan yang memungkinkan seseorang untuk mengakses parameter dan melakukan tindakan standar seperti inferensi dan pelatihan. Di atas mereka, kami menerapkan OS MS TTS Manager, yang menyatukan ketiga bagian dan memungkinkan satu untuk membuat semua pipa dan menghasilkan pidato dengan suara yang dibutuhkan. Masing-masing bagian ini juga terdiri dari sub-bagian dasar yang khas untuk elemen yang sesuai. Mereka dapat digambarkan sebagai berikut:
Di repositori kami, kami menambahkan notebook, di mana orang dapat mengunggah audio suara, file .txt dan menghasilkan pidato dengan suara yang dikloning. Meskipun bobot model pretrain diunduh secara otomatis saat menjalankan pertama, pengguna masih dapat mengunduh arsip di sini instruksi lain ada di buku catatan di sini
Nikolay akan merancang arsitektur modular, API untuk penggunaan eksternal dan pipa pelatihan. GLEB akan menerapkan tumpukan model yang berfungsi, dokumentasi tulis dan contoh penggunaan.
.
└── osms
├── __init__.py
├── common
│ ├── __init__.py
│ ├── configs
│ │ ├── __init__.py
│ │ ├── config.py
│ │ └── main_config.yaml
│ └── multispeaker.py
├── main.py
├── tts_modules
│ ├── __init__.py
│ ├── encoder
│ │ ├── __init__.py
│ │ ├── configs
│ │ │ ├── AudioConfig.yaml
│ │ │ ├── __init__.py
│ │ │ ├── config.py
│ │ │ └── dVecModelConfig.yaml
│ │ ├── data
│ │ │ ├── DataObjects.py
│ │ │ ├── __init__.py
│ │ │ ├── dataset.py
│ │ │ ├── wav2mel.py
│ │ │ └── wav_preprocessing.py
│ │ ├── models
│ │ │ ├── __init__.py
│ │ │ └── dVecModel.py
│ │ ├── speaker_encoder_manager.py
│ │ └── utils
│ │ ├── Trainer.py
│ │ └── __init__.py
│ ├── synthesizer
│ │ ├── LICENSE.md
│ │ ├── __init__.py
│ │ ├── configs
│ │ │ ├── __init__.py
│ │ │ ├── config.py
│ │ │ ├── hparams.py
│ │ │ └── tacotron_config.yaml
│ │ ├── data
│ │ │ ├── __init__.py
│ │ │ ├── audio.py
│ │ │ ├── dataset.py
│ │ │ └── preprocess.py
│ │ ├── models
│ │ │ ├── __init__.py
│ │ │ └── tacotron.py
│ │ ├── synthesize.py
│ │ ├── synthesizer_manager.py
│ │ ├── trainer.py
│ │ └── utils
│ │ ├── __init__.py
│ │ ├── cleaners.py
│ │ ├── logmmse.py
│ │ ├── numbers.py
│ │ ├── plot.py
│ │ ├── symbols.py
│ │ └── text.py
│ ├── tts_module_manager.py
│ └── vocoder
│ ├── __init__.py
│ ├── configs
│ │ ├── __init__.py
│ │ ├── config.py
│ │ ├── hparams.py
│ │ └── wavernn_config.yaml
│ ├── data
│ │ ├── __init__.py
│ │ ├── dataset.py
│ │ └── preprocess.py
│ ├── models
│ │ ├── __init__.py
│ │ └── wavernn.py
│ ├── utils
│ │ ├── Trainer.py
│ │ ├── __init__.py
│ │ ├── audio.py
│ │ ├── distribution.py
│ │ └── gen_wavernn.py
│ └── vocoder_manager.py
└── utils
└── __init__.py Jalankan pip3 install . dari direktori root.
Kami telah menerapkan pemrosesan lengkap untuk dataset LibRaspeech untuk Encoder Speaker, Synthesizer dan Vocoder. Seseorang dapat mengunduh dataset LibRaspeech melalui tautan ini. Juga, untuk Encoder Speaker kami menerapkan antarmuka untuk menggunakan dataset khusus. Orang perlu menerapkan fungsi antarmuka PreprocessDataset , fungsi antarmuka WavPreprocessor , fungsi antarmuka WavPreprocessor , atau menggunakan yang diimplementasikan.
Untuk model baseline, konfigurasi default akan dimuat secara otomatis. Untuk mengubahnya, seseorang dapat menggunakan update_config(...) di osms/common/configs/config.py . Untuk memuat konfigurasi default, seseorang dapat menggunakan get_default_<module_name>_config(...) . Juga, seseorang dapat mengimplementasikan konfigurasi sendiri untuk menggunakannya untuk model lain.
Untuk bekerja dengan masing -masing tiga modul, kami mengimplementasikan manajernya sendiri: SpeakerEncoderManager , SynthesizerManager , VocoderManager . Sebagai manajer utama kami menerapkan MustiSpreakerManager yang memberikan akses ke ketiga manajer. Seseorang dapat menggunakannya untuk menyimpulkan seluruh model TTS dan melatih setiap modul secara terpisah atau bersama -sama. Contoh penggunaan dapat ditemukan di notebook.
Pos pemeriksaan dasar diunduh secara otomatis di direktori checkpoints dengan pembuatan objek 'multispeaker'. Juga, seseorang dapat menggunakan pos pemeriksaan lain dengan memperbarui konfigurasi sederhana (ubah ... checkpoint_dir_path, checkpoint_name).


