OSM one shot multispeaker
1.0.0
ระบบการพูดหลายลำโพงแบบหลายลำกล้อง (OS MS TTS) มีวัตถุประสงค์เพื่อแปลงข้อความเป็นคำพูดด้วยเสียงที่กำหนดโดยตัวอย่างเดียวขนาดเล็ก ปัญหาหลักที่นี่คือการทำซ้ำเสียงที่มองไม่เห็นใหม่โดยไม่ต้องฝึกอบรมเครือข่ายใหม่ มีวิธีการที่มีสามขั้นตอนหลักที่ใช้ในการแก้ปัญหานี้ ที่ไม่ซ้ำกันสำหรับการฝังตัวลำโพงแต่ละตัวซึ่งเปิดเผยลักษณะเสียงถูกสร้างขึ้นในขั้นตอนแรก ( ตัวเข้ารหัสลำโพง ) ในขั้นตอนที่สอง ( synthesizer ) ข้อความจะถูกเปลี่ยนเป็น mel-spectrogram โดยใช้การฝังตัวที่ได้ก่อนหน้านี้ ในที่สุดคำพูดจะถูกทำซ้ำจาก mel-spectrogram กับ คำร้อง แต่ไม่มีการใช้งานกับทั้งสามส่วนรวมกันอย่างเหมาะสม ดังนั้นเป้าหมายของโครงการของเราคือการสร้างเฟรมเวิร์กที่ยืดหยุ่นเพื่อรวมชิ้นส่วนเหล่านี้และจัดทำโมดูลและวิธีการที่เปลี่ยนได้ในแต่ละส่วน
ตอนนี้เราเห็นความท้าทายหลักต่อไปนี้:
เราเลือกโซลูชันที่เสนอโดยผู้สอนเป็นพื้นฐานซึ่งสามารถพบได้ที่นี่ มันคือการใช้งานของ [1] ที่ทำใน Google ในปี 2018 ที่นี่ผู้เขียนใช้ตัวเข้ารหัสลำโพงที่นำเสนอใน [2] ซึ่งสร้างเวกเตอร์ฝังมิติแบบคงที่ที่เรียกว่า D-vector สำหรับซินธิไซเซอร์พวกเขาใช้โมเดลที่ใช้ Tacotron 2 [3] ในขณะที่ใช้ Wavenet แบบเร่งความเร็วโดยอัตโนมัติถูกใช้เป็น Vocoder [4] ภาพต่อไปนี้ที่นำมาจาก [1] หมายถึงภาพรวมของแบบจำลอง: 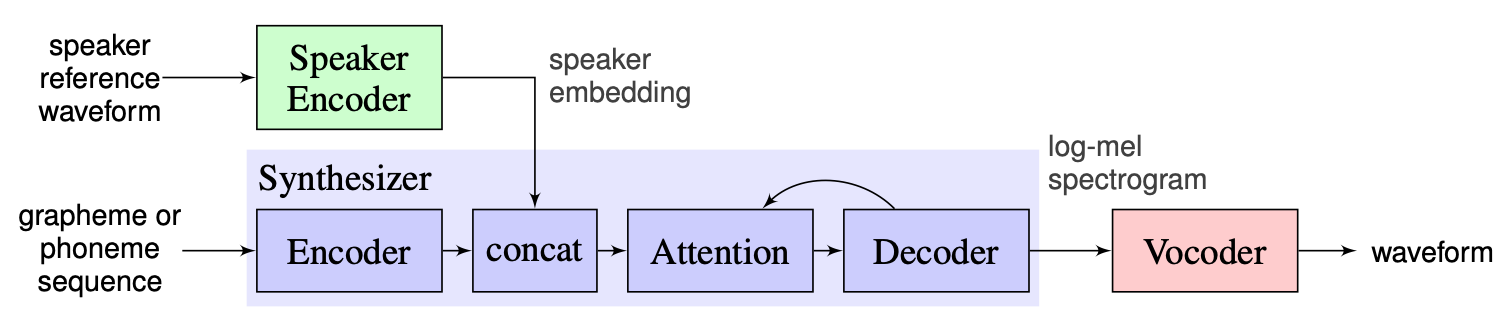
การโคลนนิ่งแบบเรียลไทม์ประกอบด้วยการรับรู้ของ encoder, Tacotron 2 และ Wavernn ไปป์ไลน์ทั้งหมดที่อธิบายไว้ใน [1] รวมถึงขั้นตอนการประมวลผลล่วงหน้ายังถูกนำไปใช้ในที่เก็บนี้ อย่างไรก็ตามโครงการไม่ยืดหยุ่นเพียงพอ โดยเฉพาะอย่างยิ่งในสถานะปัจจุบันไม่สามารถใช้เป็นเฟรมเวิร์กสำหรับระบบข้อความหลายลำโพงต่อการพูดหลายครั้งเนื่องจากไม่มีกลไกที่สะดวกสำหรับการจัดการกับโมดูลหลักสามโมดูล ตัวอย่างเช่นระบบ TTS หลายลำโพงที่เสนอใน [5] ไม่สามารถนำไปใช้ได้อย่างง่ายดายด้วยความช่วยเหลือของการโคลนนิ่งแบบเรียลไทม์เนื่องจากไม่มีจุดขยายความสามารถซึ่งอนุญาตให้ปรับท่อสำหรับวิธีใหม่
แผนของเราคือการใช้การโคลนนิ่งแบบเรียลไทม์เป็นจุดเริ่มต้นด้วยพื้นฐานที่ใช้งาน เราจะแนะนำการออกแบบโมดูลาร์ที่ยืดหยุ่นของเฟรมเวิร์ก วิธีการดังกล่าวจะช่วยให้เราสร้าง API ที่สะดวกสำหรับผู้ใช้ภายนอกที่จะสามารถใช้เฟรมเวิร์กของเราสำหรับการรวมระบบ TTS หลายลำโพงไว้ในผลิตภัณฑ์ของพวกเขา API จะช่วยให้ผู้ใช้ปรับแต่งโมดูลและขั้นตอนไปป์ไลน์โดยไม่ต้องเปลี่ยนซอร์สโค้ดของเฟรมเวิร์กหากจำเป็น เราจะใช้เครื่องเข้ารหัสลำโพงหลายตัว (LDE, TDNN) และเพิ่มลงในกรอบของเราเช่นกัน
จากจุดสูงโครงการของเราประกอบด้วย 3 องค์ประกอบหลัก: ลำโพงตัวเข้ารหัส, ซินธิไซเซอร์, Vocoder สำหรับแต่ละคนผู้จัดการจะถูกนำไปใช้ซึ่งอนุญาตให้หนึ่งสามารถเข้าถึงพารามิเตอร์และดำเนินการมาตรฐานเช่นการอนุมานและการฝึกอบรม ข้างบนเราใช้ OS MS MS TTS Manager ซึ่งรวบรวมทั้งสามส่วนเข้าด้วยกันและอนุญาตให้หนึ่งสามารถทำท่อทั้งหมดและผลิตคำพูดด้วยเสียงที่จำเป็น แต่ละส่วนเหล่านี้ยังประกอบด้วยส่วนย่อยพื้นฐานทั่วไปสำหรับองค์ประกอบที่สอดคล้องกัน พวกเขาสามารถอธิบายได้ดังนี้:
ในพื้นที่เก็บข้อมูลของเราเราได้เพิ่มสมุดบันทึกซึ่งสามารถอัปโหลดไฟล์เสียงเสียง. txt และสร้างคำพูดด้วยเสียงโคลน แม้จะมีการดาวน์โหลดแบบจำลองน้ำหนัก pretrained โดยอัตโนมัติในตอนแรก แต่ผู้ใช้ยังสามารถดาวน์โหลดเก็บถาวรได้ที่นี่คำแนะนำอื่น ๆ อยู่ในสมุดบันทึกที่นี่
Nikolay จะออกแบบสถาปัตยกรรมแบบแยกส่วน API สำหรับการใช้งานภายนอกและไปป์ไลน์การฝึกอบรม Gleb จะใช้สแต็คที่ใช้งานได้ของแบบจำลองการเขียนเอกสารและตัวอย่างการใช้งาน
.
└── osms
├── __init__.py
├── common
│ ├── __init__.py
│ ├── configs
│ │ ├── __init__.py
│ │ ├── config.py
│ │ └── main_config.yaml
│ └── multispeaker.py
├── main.py
├── tts_modules
│ ├── __init__.py
│ ├── encoder
│ │ ├── __init__.py
│ │ ├── configs
│ │ │ ├── AudioConfig.yaml
│ │ │ ├── __init__.py
│ │ │ ├── config.py
│ │ │ └── dVecModelConfig.yaml
│ │ ├── data
│ │ │ ├── DataObjects.py
│ │ │ ├── __init__.py
│ │ │ ├── dataset.py
│ │ │ ├── wav2mel.py
│ │ │ └── wav_preprocessing.py
│ │ ├── models
│ │ │ ├── __init__.py
│ │ │ └── dVecModel.py
│ │ ├── speaker_encoder_manager.py
│ │ └── utils
│ │ ├── Trainer.py
│ │ └── __init__.py
│ ├── synthesizer
│ │ ├── LICENSE.md
│ │ ├── __init__.py
│ │ ├── configs
│ │ │ ├── __init__.py
│ │ │ ├── config.py
│ │ │ ├── hparams.py
│ │ │ └── tacotron_config.yaml
│ │ ├── data
│ │ │ ├── __init__.py
│ │ │ ├── audio.py
│ │ │ ├── dataset.py
│ │ │ └── preprocess.py
│ │ ├── models
│ │ │ ├── __init__.py
│ │ │ └── tacotron.py
│ │ ├── synthesize.py
│ │ ├── synthesizer_manager.py
│ │ ├── trainer.py
│ │ └── utils
│ │ ├── __init__.py
│ │ ├── cleaners.py
│ │ ├── logmmse.py
│ │ ├── numbers.py
│ │ ├── plot.py
│ │ ├── symbols.py
│ │ └── text.py
│ ├── tts_module_manager.py
│ └── vocoder
│ ├── __init__.py
│ ├── configs
│ │ ├── __init__.py
│ │ ├── config.py
│ │ ├── hparams.py
│ │ └── wavernn_config.yaml
│ ├── data
│ │ ├── __init__.py
│ │ ├── dataset.py
│ │ └── preprocess.py
│ ├── models
│ │ ├── __init__.py
│ │ └── wavernn.py
│ ├── utils
│ │ ├── Trainer.py
│ │ ├── __init__.py
│ │ ├── audio.py
│ │ ├── distribution.py
│ │ └── gen_wavernn.py
│ └── vocoder_manager.py
└── utils
└── __init__.py Run pip3 install . จากไดเรกทอรีราก
เราได้ใช้การประมวลผลที่สมบูรณ์สำหรับชุดข้อมูล libraspeech สำหรับตัวเข้ารหัสลำโพง, synthesizer และ vocoder หนึ่งสามารถดาวน์โหลดชุดข้อมูล libraspeech ผ่านลิงค์นี้ นอกจากนี้สำหรับตัวเข้ารหัสลำโพงเราใช้อินเทอร์เฟซเพื่อใช้ชุดข้อมูลที่กำหนดเอง เราจำเป็นต้องใช้ฟังก์ชั่นอินเตอร์เฟส PreprocessDataset , ฟังก์ชั่นอินเตอร์เฟส WavPreprocessor , ฟังก์ชั่นอินเตอร์เฟส WavPreprocessor หรือใช้งานที่นำไปใช้
สำหรับรุ่นพื้นฐานการกำหนดค่าเริ่มต้นจะถูกโหลดโดยอัตโนมัติ หากต้องการเปลี่ยนพวกเขาสามารถใช้ update_config(...) ใน osms/common/configs/config.py ในการโหลดการกำหนดค่าเริ่มต้นหนึ่งสามารถใช้ get_default_<module_name>_config(...) นอกจากนี้เราสามารถใช้การกำหนดค่าของเขาเองเพื่อใช้สำหรับรุ่นอื่น ๆ
ในการทำงานกับแต่ละโมดูลเราใช้งานผู้จัดการของตัวเอง: SpeakerEncoderManager , SynthesizerManager , VocoderManager ในฐานะผู้จัดการหลักเราใช้ MustiSpreakerManager ซึ่งให้การเข้าถึงผู้จัดการทั้งสามคน หนึ่งสามารถใช้พวกเขาเพื่ออนุมานโมเดล TTS ทั้งหมดและฝึกอบรมแต่ละโมดูลแยกกันหรือร่วมกัน ตัวอย่างการใช้งานสามารถพบได้ในสมุดบันทึก
จุดตรวจพื้นฐานจะถูกดาวน์โหลดโดยอัตโนมัติในไดเรกทอรี checkpoints ด้วยการสร้างวัตถุ 'Multispeaker' นอกจากนี้เราสามารถใช้จุดตรวจอื่น ๆ โดยการอัปเดตการกำหนดค่าอย่างง่าย (เปลี่ยน ... CheckPoint_DIR_Path, CheckPoint_Name)


