OSM one shot multispeaker
1.0.0
Os sistemas de texto para fala em múltiplos falantes de um tiro de um Shot têm como objetivo transformar o texto em fala com voz determinada por uma pequena amostra única. O principal problema aqui é reproduzir a nova voz invisível sem recorrer a rede. Há uma abordagem com três estágios principais que são usados para resolver esse problema. Os únicos para cada orador de voz, que revelam as características da voz, são gerados no primeiro estágio ( codificador do alto -falante ). No segundo estágio ( sintetizador ), o texto é transformado em espectrograma MEL usando incorporações obtidas anteriormente. Finalmente, o discurso é reproduzido do espectrograma MEL com o vocoder . Mas há falta de implementações com essas três partes adequadamente combinadas. Portanto, o objetivo do nosso projeto é criar uma estrutura flexível para combinar essas peças e fornecer módulos e métodos substituíveis em cada parte.
Até agora vemos os seguintes desafios principais:
Escolhemos a solução proposta pelos instrutores como uma linha de base, que pode ser encontrada aqui. É a implementação de [1] fabricado no Google em 2018. Aqui os autores usam o codificador do alto-falante, apresentado em [2], que gera um vetor de incorporação de dimensão fixa conhecida como D-vetor. Quanto ao sintetizador, eles usam o modelo com base no tacotron 2 [3], enquanto uma base de wavenet automaticamente regressiva é usada como o vocoder [4]. A imagem a seguir tirada de [1] representa a visão geral do modelo: 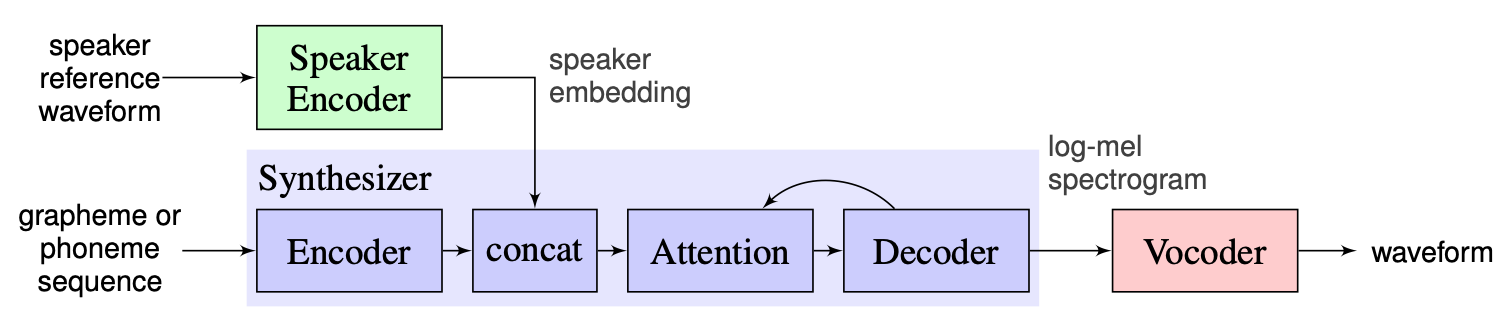
A clonagem de voz em tempo real contém as realizações do codificador, Tacotron 2 e Wavernn. Todo o pipeline descrito em [1], incluindo etapas de pré -processamento, também é implementado neste repositório. No entanto, o projeto não é flexível o suficiente. Mais especificamente, no estado atual, ele não pode ser usado como estrutura para um sistema de texto para fala de vários falantes de um tiro, pois não há mecanismos convenientes para manipular com os três módulos principais. Por exemplo, o sistema TTS multi-falante proposto em [5] não pode ser facilmente implementado com a ajuda da clonagem de voz em tempo real, pois não há pontos de extensibilidade que permitam ajustar o pipeline para o novo método.
Nosso plano é usar a clonagem de voz em tempo real como ponto de partida na linha de base implementada. Introduziremos o design modular flexível da estrutura. Essa abordagem nos ajudará a criar a API conveniente para usuários externos que poderão usar nossa estrutura para incorporar o sistema TTS de vários falantes em seus produtos. A API também permitirá que os usuários personalizem módulos e etapas do pipeline sem alterar o código -fonte da estrutura, se necessário. Implementaremos vários codificadores de alto -falantes (LDE, TDNN) e os adicionaremos à nossa estrutura também.
De um ponto alto, nosso projeto consiste em 3 elementos principais: codificador de alto -falante, sintetizador, vocoder. Para cada um deles, é implementado um gerente que permite acessar os parâmetros e executar ações padrão, como inferência e treinamento. Acima deles, implementamos o OS MS TTS Manager, que reúne todas as três partes e permite fazer todo o pipeline e produzir fala com a voz necessária. Cada uma dessas partes também consiste em sub-partes elementares típicas para os elementos correspondentes. Eles podem ser descritos da seguinte forma:
Em nosso repositório, adicionamos notebook, onde se pode fazer upload do arquivo .txt File e produzir uma fala com voz clonada. Apesar dos pesos dos modelos pré -terem sido baixados automaticamente na primeira execução, o usuário ainda pode baixar o arquivo aqui, outras instruções estão no notebook aqui
Nikolay projetará a arquitetura modular, API para uso externo e pipeline de treinamento. O GLEB implementará a pilha de trabalho dos modelos, escreverá documentações e exemplos de uso.
.
└── osms
├── __init__.py
├── common
│ ├── __init__.py
│ ├── configs
│ │ ├── __init__.py
│ │ ├── config.py
│ │ └── main_config.yaml
│ └── multispeaker.py
├── main.py
├── tts_modules
│ ├── __init__.py
│ ├── encoder
│ │ ├── __init__.py
│ │ ├── configs
│ │ │ ├── AudioConfig.yaml
│ │ │ ├── __init__.py
│ │ │ ├── config.py
│ │ │ └── dVecModelConfig.yaml
│ │ ├── data
│ │ │ ├── DataObjects.py
│ │ │ ├── __init__.py
│ │ │ ├── dataset.py
│ │ │ ├── wav2mel.py
│ │ │ └── wav_preprocessing.py
│ │ ├── models
│ │ │ ├── __init__.py
│ │ │ └── dVecModel.py
│ │ ├── speaker_encoder_manager.py
│ │ └── utils
│ │ ├── Trainer.py
│ │ └── __init__.py
│ ├── synthesizer
│ │ ├── LICENSE.md
│ │ ├── __init__.py
│ │ ├── configs
│ │ │ ├── __init__.py
│ │ │ ├── config.py
│ │ │ ├── hparams.py
│ │ │ └── tacotron_config.yaml
│ │ ├── data
│ │ │ ├── __init__.py
│ │ │ ├── audio.py
│ │ │ ├── dataset.py
│ │ │ └── preprocess.py
│ │ ├── models
│ │ │ ├── __init__.py
│ │ │ └── tacotron.py
│ │ ├── synthesize.py
│ │ ├── synthesizer_manager.py
│ │ ├── trainer.py
│ │ └── utils
│ │ ├── __init__.py
│ │ ├── cleaners.py
│ │ ├── logmmse.py
│ │ ├── numbers.py
│ │ ├── plot.py
│ │ ├── symbols.py
│ │ └── text.py
│ ├── tts_module_manager.py
│ └── vocoder
│ ├── __init__.py
│ ├── configs
│ │ ├── __init__.py
│ │ ├── config.py
│ │ ├── hparams.py
│ │ └── wavernn_config.yaml
│ ├── data
│ │ ├── __init__.py
│ │ ├── dataset.py
│ │ └── preprocess.py
│ ├── models
│ │ ├── __init__.py
│ │ └── wavernn.py
│ ├── utils
│ │ ├── Trainer.py
│ │ ├── __init__.py
│ │ ├── audio.py
│ │ ├── distribution.py
│ │ └── gen_wavernn.py
│ └── vocoder_manager.py
└── utils
└── __init__.py Execute pip3 install . do diretório raiz.
Implementamos o processamento completo para o conjunto de dados de librapech para codificador de alto -falante, sintetizador e vocoder. Pode -se baixar o conjunto de dados da librapechech por este link. Além disso, para o codificador de alto -falante, implementamos a interface para usar o conjunto de dados personalizado. É preciso implementar funções de interface PreprocessDataset , funções de interface WavPreprocessor , funções de interface WavPreprocessor ou usar as implementadas.
Para modelos de linha de base, as configurações padrão serão carregadas automaticamente. Para alterá -los, pode -se usar update_config(...) em osms/common/configs/config.py . Para carregar a configuração padrão, pode -se usar get_default_<module_name>_config(...) . Além disso, pode -se implementar suas próprias configurações para usá -las para outros modelos.
Para trabalhar com cada três módulos, implementamos seu próprio gerente: SpeakerEncoderManager , SynthesizerManager , VocoderManager . Como gerente principal, implementamos MustiSpreakerManager , que dão acesso aos três gerentes. Pode -se usá -los para inferir todo o modelo TTS e treinar cada módulos separadamente ou juntos. O exemplo de uso pode ser encontrado no notebook.
Os pontos de verificação da linha de base são baixados automaticamente no diretório checkpoints com a criação do objeto 'multispeaker'. Além disso, pode -se usar outros pontos de verificação por atualização simples de configuração (alteração ... verificação_dir_path, checkpoint_name).


