OSM one shot multispeaker
1.0.0
تهدف أنظمة النص إلى نص إلى خطاب واحد (OS MS TTS) لطيخ واحدة إلى تحويل النص إلى خطاب مع الصوت الذي يحدده عينة واحدة صغيرة. المشكلة الرئيسية هنا هي إعادة إنتاج الصوت غير المرئي الجديد دون إعادة تدريب الشبكة. هناك نهج مع ثلاث مراحل رئيسية تستخدم لحل هذه المشكلة. يتم إنشاء فريدة من نوعها لكل مكبر صوت صوتي ، والتي تكشف عن خصائص الصوت ، في المرحلة الأولى ( تشفير مكبر الصوت ). في المرحلة الثانية ( المزج ) يتم تحويل النص إلى طيف الميل باستخدام التضمينات التي تم الحصول عليها مسبقًا. أخيرًا ، يتم استنساخ الكلام من طيف الميل مع المتفرج . ولكن هناك نقص في التطبيقات مع هذه الأجزاء الثلاثة مجتمعة بشكل صحيح. لذا فإن الهدف من مشروعنا هو إنشاء إطار عمل مرن لدمج هذه الأجزاء وتوفير الوحدات والأساليب القابلة للاستبدال في كل جزء.
الآن نرى التحديات الرئيسية التالية:
نختار الحل الذي اقترحه المدربون كخط أساس ، والذي يمكن العثور عليه هنا. إنه تطبيق [1] الذي تم في Google في عام 2018. هنا يستخدم المؤلفون تشفير السماعات ، المقدم في [2] ، والذي يولد متجهًا ثابتًا ثنائي الأبعاد يعرف باسم D-Vector. أما بالنسبة لموازخ ، فإنهم يستخدمون النموذج القائم على Tacotron 2 [3] بينما يتم استخدام Wavenet التلقائي القائم على الموجود [4]. تمثل الصورة التالية المأخوذة من [1] نظرة عامة على النموذج: 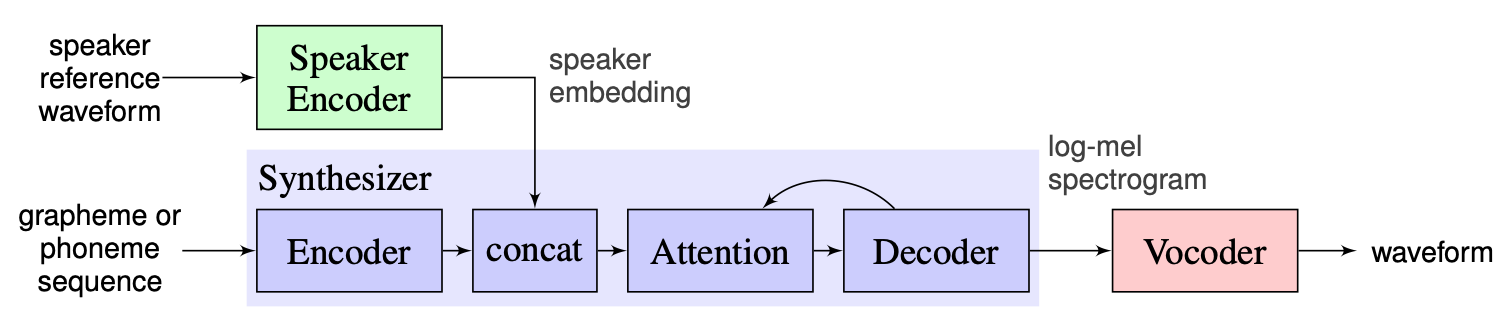
يحتوي التراجع في الوقت الفعلي على تحقيقات التشفير ، Tacotron 2 و Wavernn. يتم تنفيذ خط الأنابيب بأكمله الموصوف في [1] ، بما في ذلك خطوات المعالجة المسبقة ، في هذا المستودع. ومع ذلك ، فإن المشروع غير مرن بما فيه الكفاية. وبشكل أكثر تحديداً ، لا يمكن استخدامه في الحالة الحالية كإطار لنظام النص إلى الكلام متعدد اللقطات ، حيث لا توجد آليات مريحة للتلاعب مع الوحدات الرئيسية الثلاث. على سبيل المثال ، لا يمكن تنفيذ نظام TTS متعدد الحواف المقترح في [5] بسهولة بمساعدة التراجع في الوقت الفعلي حيث لا توجد نقاط تمديد تسمح بضبط خط الأنابيب للطريقة الجديدة.
تتمثل خطتنا في استخدام التراجع في الوقت الفعلي كنقطة انطلاق مع خط الأساس المنفذ. سنقدم التصميم المعياري المرن للإطار. سيساعدنا هذا النهج على إنشاء واجهة برمجة التطبيقات المريحة للمستخدمين الخارجيين الذين سيتمكنون من استخدام إطار عملنا لدمج نظام TTS متعدد الحوامل في منتجاتهم. سيسمح API أيضًا للمستخدمين بتخصيص الوحدات النمطية وخطوات خطوط الأنابيب دون تغيير الكود المصدري للإطار إذا لزم الأمر. سنقوم بتنفيذ العديد من ترميزات السماعات (LDE ، TDNN) وإضافتها إلى إطار عملنا أيضًا.
من نقطة عالية ، يتكون مشروعنا من 3 عناصر رئيسية: مشفر مكبر الصوت ، مزج ، فوتودر. لكل منهم ، يتم تنفيذ المدير يسمح للمرء بالوصول إلى المعلمات وإجراء الإجراءات القياسية مثل الاستدلال والتدريب. فوقهم ، قمنا بتطبيق OS MS TTS Manager ، الذي يجمع بين جميع الأجزاء الثلاثة ويسمح للمرء بصنع جميع خطوط الأنابيب وإنتاج الكلام بصوت مطلوب. يتكون كل من هذه الأجزاء أيضًا من أجزاء فرعية أولية نموذجية للعناصر المقابلة. يمكن وصفها على النحو التالي:
في مستودعنا ، أضفنا دفتر ملاحظات ، حيث يمكن للمرء تحميل صوت الصوت وملف .txt وإنتاج الكلام بصوت مستنسخ. على الرغم من أن أوزان النماذج المسبقة يتم تنزيلها تلقائيًا في المدى الأول ، لا يزال بإمكان المستخدم تنزيل الأرشيف هنا
سيقوم نيكولاي بتصميم الهندسة المعيارية ، واجهة برمجة التطبيقات للاستخدام الخارجي وتدريب خط أنابيب. سيقوم GLEB بتنفيذ كومة العمل من النماذج ، وكتابة الوثائق وأمثلة الاستخدام.
.
└── osms
├── __init__.py
├── common
│ ├── __init__.py
│ ├── configs
│ │ ├── __init__.py
│ │ ├── config.py
│ │ └── main_config.yaml
│ └── multispeaker.py
├── main.py
├── tts_modules
│ ├── __init__.py
│ ├── encoder
│ │ ├── __init__.py
│ │ ├── configs
│ │ │ ├── AudioConfig.yaml
│ │ │ ├── __init__.py
│ │ │ ├── config.py
│ │ │ └── dVecModelConfig.yaml
│ │ ├── data
│ │ │ ├── DataObjects.py
│ │ │ ├── __init__.py
│ │ │ ├── dataset.py
│ │ │ ├── wav2mel.py
│ │ │ └── wav_preprocessing.py
│ │ ├── models
│ │ │ ├── __init__.py
│ │ │ └── dVecModel.py
│ │ ├── speaker_encoder_manager.py
│ │ └── utils
│ │ ├── Trainer.py
│ │ └── __init__.py
│ ├── synthesizer
│ │ ├── LICENSE.md
│ │ ├── __init__.py
│ │ ├── configs
│ │ │ ├── __init__.py
│ │ │ ├── config.py
│ │ │ ├── hparams.py
│ │ │ └── tacotron_config.yaml
│ │ ├── data
│ │ │ ├── __init__.py
│ │ │ ├── audio.py
│ │ │ ├── dataset.py
│ │ │ └── preprocess.py
│ │ ├── models
│ │ │ ├── __init__.py
│ │ │ └── tacotron.py
│ │ ├── synthesize.py
│ │ ├── synthesizer_manager.py
│ │ ├── trainer.py
│ │ └── utils
│ │ ├── __init__.py
│ │ ├── cleaners.py
│ │ ├── logmmse.py
│ │ ├── numbers.py
│ │ ├── plot.py
│ │ ├── symbols.py
│ │ └── text.py
│ ├── tts_module_manager.py
│ └── vocoder
│ ├── __init__.py
│ ├── configs
│ │ ├── __init__.py
│ │ ├── config.py
│ │ ├── hparams.py
│ │ └── wavernn_config.yaml
│ ├── data
│ │ ├── __init__.py
│ │ ├── dataset.py
│ │ └── preprocess.py
│ ├── models
│ │ ├── __init__.py
│ │ └── wavernn.py
│ ├── utils
│ │ ├── Trainer.py
│ │ ├── __init__.py
│ │ ├── audio.py
│ │ ├── distribution.py
│ │ └── gen_wavernn.py
│ └── vocoder_manager.py
└── utils
└── __init__.py تشغيل pip3 install . من دليل الجذر.
لقد قمنا بتطبيق معالجة كاملة لمجموعة بيانات المكبرات من مكبرات الصوت وموزعة مكبر الصوت وموزعة الصوت. يمكن للمرء تنزيل مجموعة بيانات Libraspesh عبر هذا الرابط. أيضًا ، بالنسبة لمشفر مكبر الصوت ، قمنا بتطبيق واجهة لاستخدام مجموعة بيانات مخصصة. يحتاج المرء إلى تنفيذ وظائف واجهة PreprocessDataset ، أو وظائف واجهة WavPreprocessor ، أو وظائف واجهة WavPreprocessor ، أو استخدام وظائف تنفيذها.
بالنسبة للطرز الأساسية ، سيتم تحميل التكوينات الافتراضية تلقائيًا. لتغييرها ، يمكن للمرء استخدام update_config(...) في osms/common/configs/config.py . لتحميل التكوين الافتراضي ، يمكن للمرء استخدام get_default_<module_name>_config(...) . أيضا ، يمكن للمرء تنفيذ تكويناته الخاصة لاستخدامها في الطرز الأخرى.
للعمل مع كل وحدات ثلاث وحدات ، قمنا بتنفيذ مديرها الخاص: SpeakerEncoderManager ، SynthesizerManager ، VocoderManager . كمدير رئيسي قمنا بتنفيذ MustiSpreakerManager الذي يتيح الوصول إلى جميع المديرين الثلاثة. يمكن للمرء استخدامها لاستنتاج نموذج TTS بالكامل وتدريب كل وحدات بشكل منفصل أو معًا. يمكن العثور على مثال الاستخدام في دفتر الملاحظات.
يتم تنزيل نقاط التفتيش الأساسية تلقائيًا في دليل checkpoints مع إنشاء كائن "multispeaker". أيضًا ، يمكن للمرء استخدام نقاط التفتيش الأخرى عن طريق التحديث البسيط للتكوين (Change ... checkpoint_dir_path ، checkpoint_name).


