OSM one shot multispeaker
1.0.0
One-Shot-Systeme mit mehreren Sprechern (OS-MS TTS) -Systemen (OS-MS MS TTS) sollen Text in Sprache umwandeln, wobei durch kleine einzelne Probe bestimmt wird. Das Hauptproblem hier ist, die neue unsichtbare Stimme zu reproduzieren, ohne das Netzwerk umzusetzen. Es gibt einen Ansatz mit drei Hauptstufen, mit denen dieses Problem gelöst werden kann. Die einzigartigen für jeden Sprachlautsprecher -Einbettungen, die die Sprachmerkmale zeigen, werden in der ersten Stufe ( Sprecher -Encoder ) erzeugt. In der zweiten Stufe ( Synthesizer ) wird der Text unter Verwendung zuvor erhaltener Einbettungen in Melspektrogramm transformiert. Schließlich wird die Sprache aus dem Melspektogramm mit dem Vokoder reproduziert. Es fehlt jedoch an Implementierungen mit diesen drei Teilen, die richtig kombiniert werden. Ziel unseres Projekts ist es daher, ein flexibles Rahmen zu erstellen, um diese Teile zu kombinieren und in jedem Teil austauschbare Module und Methoden bereitzustellen.
Inzwischen sehen wir die folgenden Hauptherausforderungen:
Wir wählen die von den Ausbildern vorgeschlagene Lösung als Basislinie, die hier zu finden ist. Es handelt sich um die Implementierung von [1] in Google im Jahr 2018. Hier verwenden Autoren den in [2] dargestellten Sprecher-Encoder, der einen festgelegten Einbettungsvektor generiert, der als D-Vektor bekannt ist. In Bezug auf Synthesizer verwenden sie ein Modell basierend auf Tacotron 2 [3], während ein automatisch-regressives Wellenetbasis als Vocoder verwendet wird [4]. Das folgende Bild aus [1] stellt den Modellüberblick dar: 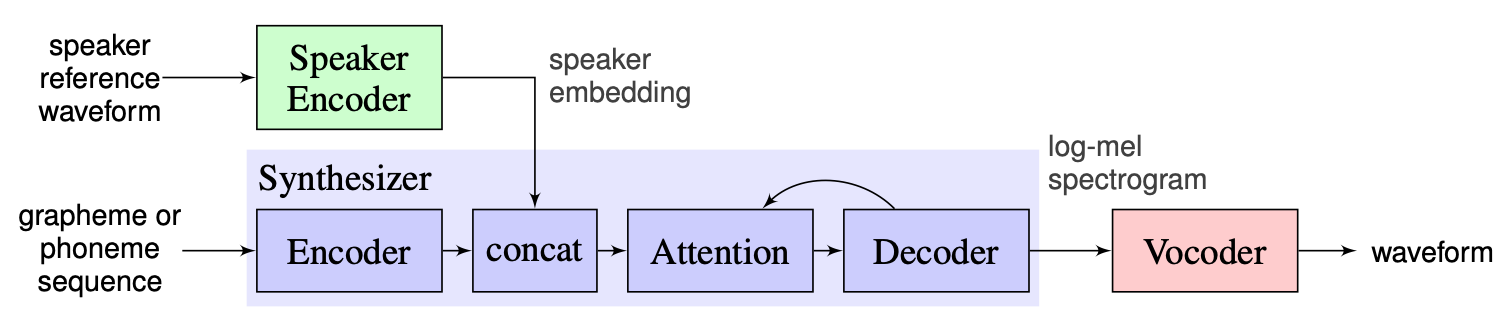
Das Echtzeit-Voice-Kloning enthält die Erkenntnisse von Encoder, Tacotron 2 und Regemn. Die in [1] beschriebene gesamte Pipeline, einschließlich der Vorverarbeitungsschritte, wird in diesem Repository ebenfalls implementiert. Das Projekt ist jedoch nicht flexibel genug. Insbesondere kann es im aktuellen Zustand nicht als Framework für ein Schuss-Text-zu-Sprache-System mit mehreren Sprechern verwendet werden, da es keine bequemen Mechanismen zum Manipulieren mit den drei Hauptmodulen gibt. Beispielsweise kann das vorgeschlagene Multi-Sprecher-TTS-System in [5] mit Hilfe der Echtzeit-Voice-Klonierung nicht einfach implementiert werden, da es keine Erweiterbarkeitspunkte gibt, die es ermöglichen, die Pipeline für die neue Methode anzupassen.
Unser Plan ist es, die Echtzeit-Voice-Klonierung als Ausgangspunkt mit der implementierten Basislinie zu verwenden. Wir werden das flexible modulare Design des Gerüsts einführen. Ein solcher Ansatz hilft uns, die bequeme API für externe Benutzer zu erstellen, die in der Lage sind, unser Rahmen für die Einbeziehung des TTS-Systems mit mehreren Lautsprechern in ihre Produkte einzubeziehen. Mit der API können die Benutzer auch Module und Pipeline -Schritte anpassen, ohne den Quellcode des Frameworks bei Bedarf zu ändern. Wir werden mehrere Sprecher -Encoder (LDE, TDNN) implementieren und sie auch zu unserem Rahmen hinzufügen.
Aus einem Höhepunkt besteht unser Projekt aus 3 Hauptelementen: Sprecher -Encoder, Synthesizer, Vocoder. Für jeden von ihnen wird ein Manager implementiert, mit dem man auf die Parameter zugreifen und Standardaktionen wie Inferenz und Schulung ausführen kann. Über ihnen haben wir das OS MS TTS Manager implementiert, der alle drei Teile zusammenbringt und es ermöglicht, alle Pipeline zu machen und Sprache mit der erforderlichen Stimme zu erzeugen. Jedes dieser Teile besteht auch aus elementaren Unterteilungen, die für die entsprechenden Elemente typisch sind. Sie können wie folgt beschrieben werden:
In unserem Repository haben wir das Notebook hinzugefügt, in dem man die Sprach -Audio -TXT -Datei hochladen und Sprache mit geklonter Stimme erstellen kann. Trotz der Gewichte der vorbereiteten Modelle werden beim ersten Lauf automatisch heruntergeladen, der Benutzer kann hier weiterhin das Archiv herunterladen. Weitere Anweisungen finden Sie hier im Notebook
Nikolay wird die modulare Architektur, API für externe Nutzung und Trainingspipeline entwerfen. Gleb wird den Arbeitsstapel von Modellen, Schreibdokumentationen und Nutzungsbeispiele implementieren.
.
└── osms
├── __init__.py
├── common
│ ├── __init__.py
│ ├── configs
│ │ ├── __init__.py
│ │ ├── config.py
│ │ └── main_config.yaml
│ └── multispeaker.py
├── main.py
├── tts_modules
│ ├── __init__.py
│ ├── encoder
│ │ ├── __init__.py
│ │ ├── configs
│ │ │ ├── AudioConfig.yaml
│ │ │ ├── __init__.py
│ │ │ ├── config.py
│ │ │ └── dVecModelConfig.yaml
│ │ ├── data
│ │ │ ├── DataObjects.py
│ │ │ ├── __init__.py
│ │ │ ├── dataset.py
│ │ │ ├── wav2mel.py
│ │ │ └── wav_preprocessing.py
│ │ ├── models
│ │ │ ├── __init__.py
│ │ │ └── dVecModel.py
│ │ ├── speaker_encoder_manager.py
│ │ └── utils
│ │ ├── Trainer.py
│ │ └── __init__.py
│ ├── synthesizer
│ │ ├── LICENSE.md
│ │ ├── __init__.py
│ │ ├── configs
│ │ │ ├── __init__.py
│ │ │ ├── config.py
│ │ │ ├── hparams.py
│ │ │ └── tacotron_config.yaml
│ │ ├── data
│ │ │ ├── __init__.py
│ │ │ ├── audio.py
│ │ │ ├── dataset.py
│ │ │ └── preprocess.py
│ │ ├── models
│ │ │ ├── __init__.py
│ │ │ └── tacotron.py
│ │ ├── synthesize.py
│ │ ├── synthesizer_manager.py
│ │ ├── trainer.py
│ │ └── utils
│ │ ├── __init__.py
│ │ ├── cleaners.py
│ │ ├── logmmse.py
│ │ ├── numbers.py
│ │ ├── plot.py
│ │ ├── symbols.py
│ │ └── text.py
│ ├── tts_module_manager.py
│ └── vocoder
│ ├── __init__.py
│ ├── configs
│ │ ├── __init__.py
│ │ ├── config.py
│ │ ├── hparams.py
│ │ └── wavernn_config.yaml
│ ├── data
│ │ ├── __init__.py
│ │ ├── dataset.py
│ │ └── preprocess.py
│ ├── models
│ │ ├── __init__.py
│ │ └── wavernn.py
│ ├── utils
│ │ ├── Trainer.py
│ │ ├── __init__.py
│ │ ├── audio.py
│ │ ├── distribution.py
│ │ └── gen_wavernn.py
│ └── vocoder_manager.py
└── utils
└── __init__.py pip3 install . aus dem Wurzelverzeichnis.
Wir haben die vollständige Verarbeitung für Libraspeech -Datensatz für Sprecher -Encoder, Synthesizer und Vocoder implementiert. Man kann Libraspeech -Datensatz über diesen Link herunterladen. Für den Sprecher -Encoder haben wir auch die Schnittstelle implementiert, um benutzerdefinierten Datensatz zu verwenden. Man muss PreprocessDataset -Schnittstellenfunktionen, WavPreprocessor -Schnittstellenfunktionen, WavPreprocessor -Schnittstellenfunktionen oder implementierten verwenden.
Für Basismodelle werden die Standardkonfigurationen automatisch geladen. Um sie zu ändern, kann man update_config(...) in osms/common/configs/config.py verwenden. So laden Sie die Standardkonfiguration. Sie können get_default_<module_name>_config(...) verwenden. Außerdem kann man seine eigenen Konfigurationen implementieren, um sie für andere Modelle zu verwenden.
Um mit allen drei Modulen zu arbeiten, haben wir seinen eigenen Manager implementiert: SpeakerEncoderManager , SynthesizerManager , VocoderManager . Als Hauptmanager haben wir MustiSpreakerManager implementiert, die alle drei Manager zugreifen. Man kann sie verwenden, um das gesamte TTS -Modell zu entsprechen und jedes Modulen separat oder zusammen zu trainieren. Das Beispiel für die Nutzung finden Sie in Notebook.
Baseline -Checkpoints werden automatisch im checkpoints -Verzeichnis mit der Erstellung eines Multispeaker -Objekts heruntergeladen. Außerdem kann man andere Checkpoints verwenden, indem es einfach aktualisiert wird (Änderung ... checkpoint_dir_path, checkpoint_name).


