OSM one shot multispeaker
1.0.0
One-Shot Multi-Speaker Text-to-Speech (OS MS TTS) systems are aimed to transform text into speech with voice determined by small single sample. The main problem here is to reproduce the new unseen voice without retraining the network. There is an approach with three main stages which is used to solve this problem. The unique for each voice speaker embeddings, which reveal the voice characteristics, are generated at the first stage (Speaker Encoder). At the second stage (Synthesizer) the text is transformed to mel-spectrogram using previously obtained embeddings. Finally, the speech is reproduced from the mel-spectrogram with the Vocoder. But there is lack of implementations with these three parts properly combined. So the goal of our project is to create a flexible framework to combine these parts and provide replaceable modules and methods in each part.
By now we see the following main challenges:
We choose solution proposed by the instructors as a baseline, which can be found here.
It is the implementation of [1] made in Google in 2018.
Here authors use the speaker encoder, presented in [2], which generates a fixed-dimensional embedding vector known as d-vector.
As for Synthesizer they use model based on Tacotron 2 [3] while an auto-regressive WaveNet-based is used as the Vocoder [4].
The following image taken from [1] represents the model overview:
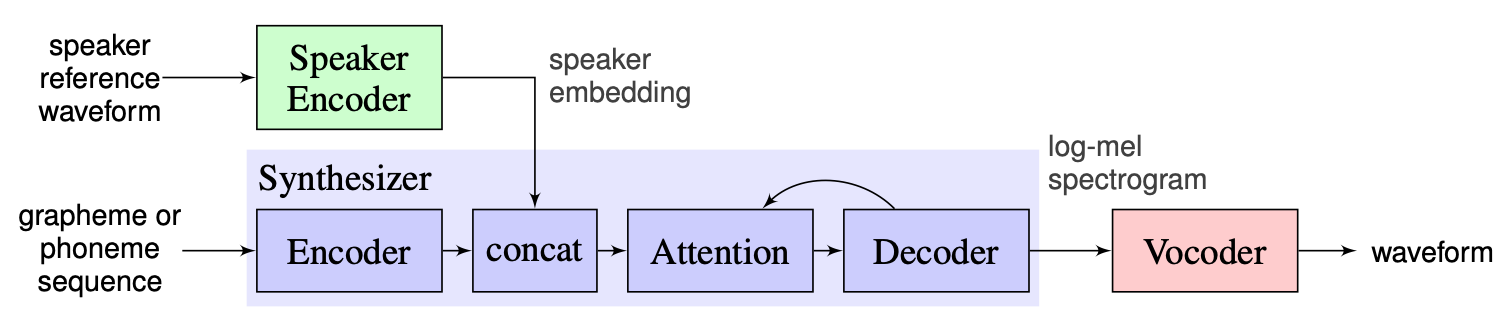
The Real-Time-Voice-Cloning contains the realizations of encoder, Tacotron 2 and WaveRNN. The whole pipeline described in [1], including preprocessing steps, is also implemented in this repository. However, the project is not flexible enough. More specifically, in the current state it cannot be used as the framework for One-Shot Multi-Speaker Text-to-Speech system as there are no convenient mechanisms for manipulating with the three main modules. For example, the proposed multi-speaker TTS system in [5] cannot be easily implemented with the help of Real-Time-Voice-Cloning as there are no extensibility points which allow to adjust the pipeline for the new method.
Our plan is to use the Real-Time-Voice-Cloning as starting point with implemented baseline. We will introduce the flexible modular design of the framework. Such approach will help us to create the convenient API for external users who will be able to use our framework for incorporating the Multi-Speaker TTS system in their products. The API will also let the users customize modules and pipeline steps without changing the source code of the framework if needed. We will implement several Speaker Encoders (LDE, TDNN) and add them to our framework as well.
From a high point, our project consists of 3 main elements: Speaker Encoder, Synthesizer, Vocoder. For each of them, a manager is implemented that allows one to access the parameters and perform standard actions such as inference and training. Above them, we implemented OS MS TTS manager, which brings together all three parts and allows one to make all pipeline and produce speech with needed voice. Each of these parts is also consist from elementary sub-parts typical for the corresponding elements. They can be described as follows:
In our repository we added notebook, where one can upload the voice audio, .txt file and produce speech with cloned voice. Despite the weights of pretrained models are downloaded automatically at the first run, the user can still download archive here Other instructions are in the notebook here
Nikolay will design the modular architecture, API for external usage and training pipeline. Gleb will implement the working stack of models, write documentations and usage examples.
.
└── osms
├── __init__.py
├── common
│ ├── __init__.py
│ ├── configs
│ │ ├── __init__.py
│ │ ├── config.py
│ │ └── main_config.yaml
│ └── multispeaker.py
├── main.py
├── tts_modules
│ ├── __init__.py
│ ├── encoder
│ │ ├── __init__.py
│ │ ├── configs
│ │ │ ├── AudioConfig.yaml
│ │ │ ├── __init__.py
│ │ │ ├── config.py
│ │ │ └── dVecModelConfig.yaml
│ │ ├── data
│ │ │ ├── DataObjects.py
│ │ │ ├── __init__.py
│ │ │ ├── dataset.py
│ │ │ ├── wav2mel.py
│ │ │ └── wav_preprocessing.py
│ │ ├── models
│ │ │ ├── __init__.py
│ │ │ └── dVecModel.py
│ │ ├── speaker_encoder_manager.py
│ │ └── utils
│ │ ├── Trainer.py
│ │ └── __init__.py
│ ├── synthesizer
│ │ ├── LICENSE.md
│ │ ├── __init__.py
│ │ ├── configs
│ │ │ ├── __init__.py
│ │ │ ├── config.py
│ │ │ ├── hparams.py
│ │ │ └── tacotron_config.yaml
│ │ ├── data
│ │ │ ├── __init__.py
│ │ │ ├── audio.py
│ │ │ ├── dataset.py
│ │ │ └── preprocess.py
│ │ ├── models
│ │ │ ├── __init__.py
│ │ │ └── tacotron.py
│ │ ├── synthesize.py
│ │ ├── synthesizer_manager.py
│ │ ├── trainer.py
│ │ └── utils
│ │ ├── __init__.py
│ │ ├── cleaners.py
│ │ ├── logmmse.py
│ │ ├── numbers.py
│ │ ├── plot.py
│ │ ├── symbols.py
│ │ └── text.py
│ ├── tts_module_manager.py
│ └── vocoder
│ ├── __init__.py
│ ├── configs
│ │ ├── __init__.py
│ │ ├── config.py
│ │ ├── hparams.py
│ │ └── wavernn_config.yaml
│ ├── data
│ │ ├── __init__.py
│ │ ├── dataset.py
│ │ └── preprocess.py
│ ├── models
│ │ ├── __init__.py
│ │ └── wavernn.py
│ ├── utils
│ │ ├── Trainer.py
│ │ ├── __init__.py
│ │ ├── audio.py
│ │ ├── distribution.py
│ │ └── gen_wavernn.py
│ └── vocoder_manager.py
└── utils
└── __init__.pyRun pip3 install . from root directory.
We have implemented complete processing for LibraSpeech Dataset for Speaker Encoder, Synthesizer and Vocoder . One can download LibraSpeech dataset via this link. Also, for Speaker Encoder we implemented interface to use custom dataset. One needs to implement PreprocessDataset interface functions, WavPreprocessor interface functions, WavPreprocessor interface functions, or use implemented ones.
For baseline models the default configs will be loaded automatically. To change them one can use update_config(...) in osms/common/configs/config.py. To load default config one can use get_default_<module_name>_config(...). Also, one can implement his own configs to use them for other models.
To work with each three modules we implemented its own manager: SpeakerEncoderManager, SynthesizerManager, VocoderManager. As main manager we implemented MustiSpreakerManager which give access to all three managers. One can use them to inference the whole TTS model and train each modules separately or together. The example of usage can be found in notebook.
Baseline checkpoints are downloaded automatically in checkpoints directory with creation of 'MultiSpeaker' object. Also, one can use other checkpoints by simple updating of config (change ...CHECKPOINT_DIR_PATH, CHECKPOINT_NAME).


