OSM one shot multispeaker
1.0.0
원샷 멀티 스피커 텍스트-음성 (OS MS TTS) 시스템은 작은 단일 샘플에 의해 결정된 음성으로 텍스트를 음성으로 변환하는 것을 목표로합니다. 여기서 주요 문제는 네트워크를 재교육하지 않고 보이지 않는 새로운 음성을 재현하는 것입니다. 이 문제를 해결하는 데 사용되는 세 가지 주요 단계가있는 접근 방식이 있습니다. 음성 특성을 나타내는 각 음성 스피커 임베딩에 대한 고유는 첫 번째 단계 ( 스피커 인코더 )에서 생성됩니다. 두 번째 단계 ( 신시사이저 )에서 텍스트는 이전에 얻은 임베딩을 사용하여 멜 스피어 그램으로 변환됩니다. 마지막으로, 음성은 멜 스피어 그램에서 보코더 와 함께 재현됩니다. 그러나이 세 부분이 올바르게 결합 된 구현이 부족합니다. 따라서 프로젝트의 목표는 이러한 부분을 결합하고 각 부분에 교체 가능한 모듈과 방법을 제공하는 유연한 프레임 워크를 만드는 것입니다.
지금까지 우리는 다음과 같은 주요 과제를 봅니다.
우리는 여기에서 찾을 수있는 기준선으로 강사가 제안한 솔루션을 선택합니다. 2018 년 Google에서 만든 [1]의 구현입니다. 여기서 저자는 [2]에 표시된 스피커 인코더를 사용하여 D- 벡터로 알려진 고정 차원 임베딩 벡터를 생성합니다. 신시사이저는 타코트론 2 [3]를 기반으로 한 모델을 사용하는 반면, 자동 반복 웨이브 넷 기반은 보코더로 사용됩니다 [4]. [1]에서 찍은 다음 이미지는 모델 개요를 나타냅니다. 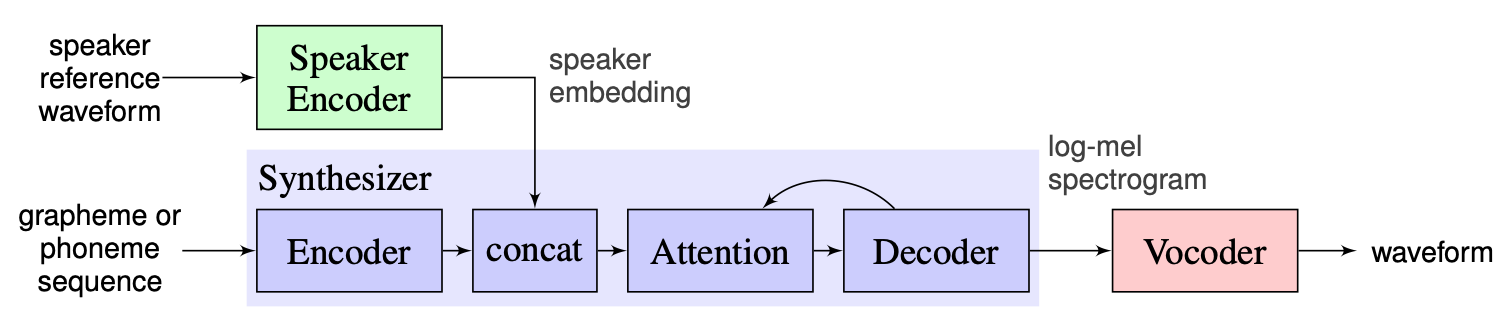
실시간 음성 클로닝에는 인코더, 타코트론 2 및 Wavernn의 실현이 포함되어 있습니다. 전처리 단계를 포함하여 [1]에 설명 된 전체 파이프 라인 도이 저장소에서 구현됩니다. 그러나 프로젝트는 충분히 유연하지 않습니다. 보다 구체적으로, 현재 상태에서는 세 가지 주요 모듈과 조작하기위한 편리한 메커니즘이 없기 때문에 원샷 멀티 스피커 텍스트 음성 연사 시스템의 프레임 워크로 사용할 수 없습니다. 예를 들어, [5]의 제안 된 멀티 스피커 TTS 시스템은 새로운 방법의 파이프 라인을 조정할 수있는 확장 성 지점이 없으므로 실시간 음성 클로닝을 통해 쉽게 구현할 수 없습니다.
우리의 계획은 실시간 음성 클로닝을 구현 된 기준선의 시작점으로 사용하는 것입니다. 프레임 워크의 유연한 모듈 식 디자인을 소개합니다. 이러한 접근 방식은 제품에 멀티 스피커 TTS 시스템을 통합하기 위해 프레임 워크를 사용할 수있는 외부 사용자를위한 편리한 API를 만들 수 있습니다. API는 또한 사용자가 필요한 경우 프레임 워크의 소스 코드를 변경하지 않고 모듈 및 파이프 라인 단계를 사용자 정의 할 수 있도록합니다. 우리는 여러 스피커 인코더 (LDE, TDNN)를 구현하여 프레임 워크에도 추가 할 것입니다.
높은 지점에서 우리 프로젝트는 스피커 인코더, 신시사이저, 보코더의 3 가지 주요 요소로 구성됩니다. 각각에 대해 매개 변수에 액세스하고 추론 및 훈련과 같은 표준 작업을 수행 할 수있는 관리자가 구현됩니다. 그 위에서, 우리는 OS MS TTS 관리자를 구현하여 세 부분을 모두 모아서 모든 파이프 라인을 만들고 필요한 음성으로 음성을 생성 할 수 있습니다. 이들 각각은 또한 해당 요소에 대해 전형적인 기본 하위 파트로 구성됩니다. 다음과 같이 설명 할 수 있습니다.
우리의 저장소에는 음성 오디오, .txt 파일을 업로드하고 복제 된 음성으로 음성을 생성 할 수있는 노트북을 추가했습니다. 사전 처리 된 모델의 가중치는 첫 번째 실행에서 자동으로 다운로드되었지만 사용자는 여기에서 아카이브를 다운로드 할 수 있습니다. 다른 지침은 여기서 노트에 있습니다.
Nikolay는 외부 사용 및 교육 파이프 라인을위한 모듈 식 아키텍처, API를 설계합니다. GLEB는 모델의 작업 스택을 구현하고 문서 작성 및 사용 예제를 작성합니다.
.
└── osms
├── __init__.py
├── common
│ ├── __init__.py
│ ├── configs
│ │ ├── __init__.py
│ │ ├── config.py
│ │ └── main_config.yaml
│ └── multispeaker.py
├── main.py
├── tts_modules
│ ├── __init__.py
│ ├── encoder
│ │ ├── __init__.py
│ │ ├── configs
│ │ │ ├── AudioConfig.yaml
│ │ │ ├── __init__.py
│ │ │ ├── config.py
│ │ │ └── dVecModelConfig.yaml
│ │ ├── data
│ │ │ ├── DataObjects.py
│ │ │ ├── __init__.py
│ │ │ ├── dataset.py
│ │ │ ├── wav2mel.py
│ │ │ └── wav_preprocessing.py
│ │ ├── models
│ │ │ ├── __init__.py
│ │ │ └── dVecModel.py
│ │ ├── speaker_encoder_manager.py
│ │ └── utils
│ │ ├── Trainer.py
│ │ └── __init__.py
│ ├── synthesizer
│ │ ├── LICENSE.md
│ │ ├── __init__.py
│ │ ├── configs
│ │ │ ├── __init__.py
│ │ │ ├── config.py
│ │ │ ├── hparams.py
│ │ │ └── tacotron_config.yaml
│ │ ├── data
│ │ │ ├── __init__.py
│ │ │ ├── audio.py
│ │ │ ├── dataset.py
│ │ │ └── preprocess.py
│ │ ├── models
│ │ │ ├── __init__.py
│ │ │ └── tacotron.py
│ │ ├── synthesize.py
│ │ ├── synthesizer_manager.py
│ │ ├── trainer.py
│ │ └── utils
│ │ ├── __init__.py
│ │ ├── cleaners.py
│ │ ├── logmmse.py
│ │ ├── numbers.py
│ │ ├── plot.py
│ │ ├── symbols.py
│ │ └── text.py
│ ├── tts_module_manager.py
│ └── vocoder
│ ├── __init__.py
│ ├── configs
│ │ ├── __init__.py
│ │ ├── config.py
│ │ ├── hparams.py
│ │ └── wavernn_config.yaml
│ ├── data
│ │ ├── __init__.py
│ │ ├── dataset.py
│ │ └── preprocess.py
│ ├── models
│ │ ├── __init__.py
│ │ └── wavernn.py
│ ├── utils
│ │ ├── Trainer.py
│ │ ├── __init__.py
│ │ ├── audio.py
│ │ ├── distribution.py
│ │ └── gen_wavernn.py
│ └── vocoder_manager.py
└── utils
└── __init__.py pip3 install . 루트 디렉토리에서.
스피커 인코더, 신시사이저 및 보코더 용 Libraspeech 데이터 세트에 대한 완전한 처리를 구현했습니다. 이 링크를 통해 libraspeech 데이터 세트를 다운로드 할 수 있습니다. 또한 스피커 인코더의 경우 사용자 정의 데이터 세트를 사용하기 위해 인터페이스를 구현했습니다. PreprocessDataset 인터페이스 함수, WavPreprocessor 인터페이스 함수, WavPreprocessor 인터페이스 기능을 구현하거나 구현 된 구현을 구현해야합니다.
기준선 모델의 경우 기본 구성이 자동으로로드됩니다. 변경하려면 osms/common/configs/config.py 에서 update_config(...) 사용할 수 있습니다. 기본 구성을로드하려면 하나는 get_default_<module_name>_config(...) 사용할 수 있습니다. 또한 다른 모델에 사용하기 위해 자신의 구성을 구현할 수 있습니다.
각 세 가지 모듈에서 작업하기 위해 자체 관리자 인 SpeakerEncoderManager , SynthesizerManager , VocoderManager 구현했습니다. 메인 관리자로서 우리는 3 명의 관리자 모두에게 액세스 할 수있는 MustiSpreakerManager 구현했습니다. 이들을 사용하여 전체 TTS 모델을 추론하고 각 모듈을 개별적으로 또는 함께 훈련시킬 수 있습니다. 사용의 예는 노트북에서 찾을 수 있습니다.
기준 체크 포인트는 'Multispeaker'객체를 생성하여 checkpoints 디렉토리에서 자동으로 다운로드됩니다. 또한 config를 간단하게 업데이트하여 다른 체크 포인트를 사용할 수 있습니다 (Change ... Checkpoint_Dir_Path, Checkpoint_name).


