OSM one shot multispeaker
1.0.0
ワンショットマルチスピーカーテキストツースピーチ(OS MS TTS)システムは、小さな単一のサンプルで決定された音声を使用してテキストを音声に変換することを目的としています。ここでの主な問題は、ネットワークを再訓練せずに新しい目に見えない音声を再現することです。この問題を解決するために使用される3つの主要な段階を持つアプローチがあります。音声特性を明らかにする各音声スピーカーの埋め込みに一意のものは、最初の段階で生成されます(スピーカーエンコーダー)。第2段階(シンセサイザー)では、テキストは、以前に取得した埋め込みを使用してメルスペクトルグラムに変換されます。最後に、音声はボコーダーを使用してMel-Spectrogramから再現されます。しかし、これらの3つの部分が適切に組み合わされて、実装が不足しています。したがって、私たちのプロジェクトの目標は、これらのパーツを組み合わせて、各パートに交換可能なモジュールとメソッドを提供する柔軟なフレームワークを作成することです。
今では、次の主な課題が見られます。
インストラクターが提案したソリューションをベースラインとして選択します。これはここで見つけることができます。これは、2018年にGoogleで作成された[1]の実装です。ここでは、著者は[2]で提示されたスピーカーエンコーダーを使用して、Dベクトルとして知られる固定次元の埋め込みベクターを生成します。シンセサイザーに関しては、タコトロン2 [3]に基づいたモデルを使用しますが、自動回帰ウェーブネットベースはボコーダーとして使用されます[4]。 [1]から取得した次の画像は、モデルの概要を表しています。 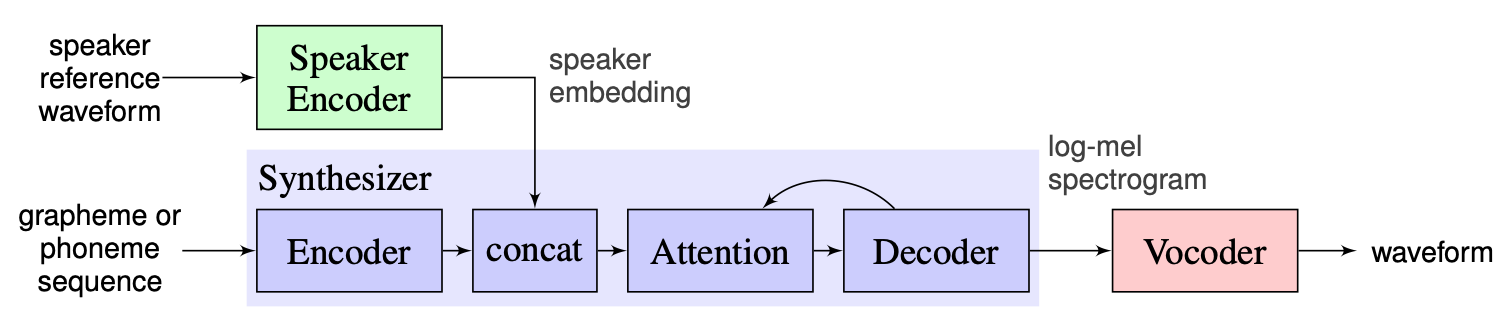
リアルタイムボイスクローニングには、エンコーダー、タコトロン2、およびwavernnの実現が含まれています。 [1]で説明されているパイプライン全体(前処理手順を含む)もこのリポジトリに実装されています。ただし、プロジェクトは十分に柔軟ではありません。より具体的には、現在の状態では、3つの主要なモジュールを操作するための便利なメカニズムがないため、ワンショットマルチスピーカーテキストからスピーチシステムのフレームワークとして使用することはできません。たとえば、[5]で提案されているマルチスピーカーTTSシステムは、新しい方法のパイプラインを調整できる拡張性ポイントがないため、リアルタイム声クローニングの助けを借りて簡単に実装できません。
私たちの計画は、実装されたベースラインの出発点としてリアルタイムボイスクローニングを使用することです。フレームワークの柔軟なモジュラー設計を紹介します。このようなアプローチは、製品にマルチスピーカーTTSシステムを組み込むためにフレームワークを使用できる外部ユーザー向けの便利なAPIを作成するのに役立ちます。また、APIは、必要に応じてフレームワークのソースコードを変更せずに、ユーザーがモジュールとパイプラインの手順をカスタマイズすることができます。いくつかのスピーカーエンコーダー(LDE、TDNN)を実装し、フレームワークにも追加します。
ハイポイントから、私たちのプロジェクトは、スピーカーエンコーダー、シンセサイザー、ボコーダーの3つの主要な要素で構成されています。それらのそれぞれについて、マネージャーが実装され、パラメーターにアクセスし、推論やトレーニングなどの標準アクションを実行できます。その上に、OS MS TTSマネージャーを実装しました。これにより、3つのパートすべてがまとめられ、すべてのパイプラインを作成し、必要な音声でスピーチを作成できます。これらの各部分は、対応する要素に典型的な基本サブパートで構成されています。次のように説明できます。
リポジトリには、音声オーディオ、.txtファイルをアップロードし、クローン音声でスピーチを作成できるノートブックを追加しました。最初の実行時には、事前に保護されたモデルの重みが自動的にダウンロードされていますが、ユーザーはここでアーカイブをダウンロードできます。
Nikolayは、モジュラーアーキテクチャ、外部使用およびトレーニングパイプラインのAPIを設計します。 Glebは、モデルの作業スタックを実装し、ドキュメントを書き、使用例を使用します。
.
└── osms
├── __init__.py
├── common
│ ├── __init__.py
│ ├── configs
│ │ ├── __init__.py
│ │ ├── config.py
│ │ └── main_config.yaml
│ └── multispeaker.py
├── main.py
├── tts_modules
│ ├── __init__.py
│ ├── encoder
│ │ ├── __init__.py
│ │ ├── configs
│ │ │ ├── AudioConfig.yaml
│ │ │ ├── __init__.py
│ │ │ ├── config.py
│ │ │ └── dVecModelConfig.yaml
│ │ ├── data
│ │ │ ├── DataObjects.py
│ │ │ ├── __init__.py
│ │ │ ├── dataset.py
│ │ │ ├── wav2mel.py
│ │ │ └── wav_preprocessing.py
│ │ ├── models
│ │ │ ├── __init__.py
│ │ │ └── dVecModel.py
│ │ ├── speaker_encoder_manager.py
│ │ └── utils
│ │ ├── Trainer.py
│ │ └── __init__.py
│ ├── synthesizer
│ │ ├── LICENSE.md
│ │ ├── __init__.py
│ │ ├── configs
│ │ │ ├── __init__.py
│ │ │ ├── config.py
│ │ │ ├── hparams.py
│ │ │ └── tacotron_config.yaml
│ │ ├── data
│ │ │ ├── __init__.py
│ │ │ ├── audio.py
│ │ │ ├── dataset.py
│ │ │ └── preprocess.py
│ │ ├── models
│ │ │ ├── __init__.py
│ │ │ └── tacotron.py
│ │ ├── synthesize.py
│ │ ├── synthesizer_manager.py
│ │ ├── trainer.py
│ │ └── utils
│ │ ├── __init__.py
│ │ ├── cleaners.py
│ │ ├── logmmse.py
│ │ ├── numbers.py
│ │ ├── plot.py
│ │ ├── symbols.py
│ │ └── text.py
│ ├── tts_module_manager.py
│ └── vocoder
│ ├── __init__.py
│ ├── configs
│ │ ├── __init__.py
│ │ ├── config.py
│ │ ├── hparams.py
│ │ └── wavernn_config.yaml
│ ├── data
│ │ ├── __init__.py
│ │ ├── dataset.py
│ │ └── preprocess.py
│ ├── models
│ │ ├── __init__.py
│ │ └── wavernn.py
│ ├── utils
│ │ ├── Trainer.py
│ │ ├── __init__.py
│ │ ├── audio.py
│ │ ├── distribution.py
│ │ └── gen_wavernn.py
│ └── vocoder_manager.py
└── utils
└── __init__.pypip3 install .ルートディレクトリから。
スピーカーエンコーダー、シンセサイザー、ボコーダー用のLibraspeechデータセットの完全な処理を実装しました。このリンクからLibraspeechデータセットをダウンロードできます。また、スピーカーエンコーダーには、カスタムデータセットを使用するインターフェイスを実装しました。 PreprocessDatasetインターフェイス関数、 WavPreprocessorインターフェイス関数、 WavPreprocessorインターフェイス関数を実装するか、実装されたものを使用する必要があります。
ベースラインモデルの場合、デフォルトの構成は自動的にロードされます。それらを変更するにはosms/common/configs/config.pyでupdate_config(...)を使用できます。デフォルトの構成をロードするにはget_default_<module_name>_config(...)を使用できます。また、他のモデルに使用する独自の構成を実装できます。
3つのモジュールごとに作業するために、独自のマネージャー、 SpeakerEncoderManager 、 SynthesizerManager 、 VocoderManagerを実装しました。メインマネージャーとして、3人のマネージャー全員にアクセスできるMustiSpreakerManagerを実装しました。それらを使用して、TTSモデル全体を推論し、各モジュールを個別にまたは一緒にトレーニングできます。使用の例は、ノートブックにあります。
ベースラインチェックポイントは、「マルチスピーカー」オブジェクトを作成したcheckpointsディレクトリから自動的にダウンロードされます。また、構成(CheckPoint_Dir_Path、CheckPoint_Name)を簡単に更新することで、他のチェックポイントを使用できます。


