OSM one shot multispeaker
1.0.0
Системы с несколькими высказываниями текста в речь (OS MS TTS) направлены на преобразование текста в речь с голосом, определяемым небольшим отдельным образцом. Основная проблема здесь - воспроизвести новый невидимый голос, не переподшив сеть. Существует подход с тремя основными этапами, который используется для решения этой проблемы. Уникальные для каждого голосового динамика, которые показывают характеристики голоса, генерируются на первом этапе ( энкодер динамика ). На втором этапе ( синтезатор ) текст преобразуется в мель-спектрограмму с использованием ранее полученных встроений. Наконец, речь воспроизводится из мель-спектрограммы с помощью вокадера . Но не хватает реализаций с этими тремя частями, правильно объединенными. Таким образом, цель нашего проекта состоит в том, чтобы создать гибкую структуру для объединения этих деталей и предоставления сменных модулей и методов в каждой части.
К настоящему времени мы видим следующие основные проблемы:
Мы выбираем решение, предложенное инструкторами в качестве базовой линии, которую можно найти здесь. Это реализация [1], сделанного в Google в 2018 году. Здесь авторы используют энкодер динамика, представленный в [2], который генерирует вектор фиксированного встроенного встраивания, известный как D-вектор. Что касается синтезатора, они используют модель на основе такотрона 2 [3], в то время как в качестве вокадера используется на основе авторегрессивного волны [4]. Следующее изображение, взятое из [1], представляет обзор модели: 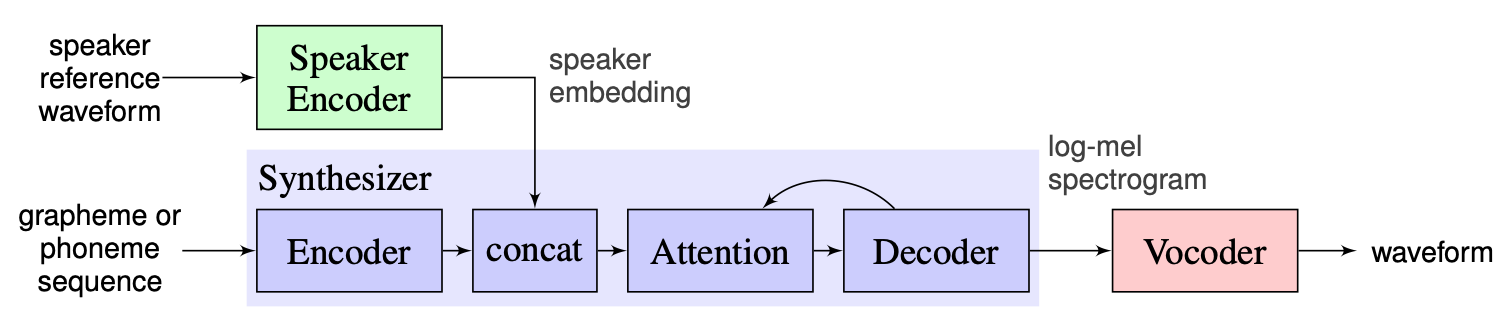
Клонирование в реальном времени содержит реализацию Encoder, Tacotron 2 и Wavernn. Весь трубопровод, описанный в [1], включая этапы предварительной обработки, также реализуется в этом хранилище. Тем не менее, проект недостаточно гибкий. Более конкретно, в текущем состоянии он не может быть использован в качестве структуры для системы с несколькими выстрелами из системы текста в речь, поскольку нет удобных механизмов для манипулирования тремя основными модулями. Например, предлагаемая система многопрофильных TTS в [5] не может быть легко реализована с помощью голосования в реальном времени, поскольку нет точек расширяемости, которые позволяют регулировать трубопровод для нового метода.
Наш план состоит в том, чтобы использовать клонирование голоса в реальном времени в качестве отправной точки с реализованной базовой линией. Мы представим гибкую модульную конструкцию каркаса. Такой подход поможет нам создать удобный API для внешних пользователей, которые смогут использовать нашу структуру для включения многопрофильной системы TTS в свои продукты. API также позволит пользователям настраивать модули и шаги трубопровода без изменения исходного кода структуры, если это необходимо. Мы будем реализовать несколько энкодеров динамиков (LDE, TDNN) и добавим их в нашу структуру.
С высокой точки наш проект состоит из 3 основных элементов: энкодера динамика, синтезатор, Vocoder. Для каждого из них реализован менеджер, который позволяет получить доступ к параметрам и выполнять стандартные действия, такие как вывод и обучение. Над ними мы внедрили MS TTS Manager OS, которая объединяет все три части и позволяет выполнять все трубопроводы и произвести речь с необходимым голосом. Каждая из этих частей также состоят из элементарных подразделений, типичных для соответствующих элементов. Их можно описать следующим образом:
В нашем репозитории мы добавили ноутбук, где можно загрузить голосовой звук, файл .txt и произвести речь с помощью клонированного голоса. Несмотря на то, что веса предварительно проведенных моделей загружаются автоматически при первом заезде, пользователь все еще может загрузить архив здесь другие инструкции в записной книжке здесь
Nikolay разработает модульную архитектуру, API для внешнего использования и тренировочного трубопровода. GLEB будет реализовать рабочую стопку моделей, записывать документации и примеры использования.
.
└── osms
├── __init__.py
├── common
│ ├── __init__.py
│ ├── configs
│ │ ├── __init__.py
│ │ ├── config.py
│ │ └── main_config.yaml
│ └── multispeaker.py
├── main.py
├── tts_modules
│ ├── __init__.py
│ ├── encoder
│ │ ├── __init__.py
│ │ ├── configs
│ │ │ ├── AudioConfig.yaml
│ │ │ ├── __init__.py
│ │ │ ├── config.py
│ │ │ └── dVecModelConfig.yaml
│ │ ├── data
│ │ │ ├── DataObjects.py
│ │ │ ├── __init__.py
│ │ │ ├── dataset.py
│ │ │ ├── wav2mel.py
│ │ │ └── wav_preprocessing.py
│ │ ├── models
│ │ │ ├── __init__.py
│ │ │ └── dVecModel.py
│ │ ├── speaker_encoder_manager.py
│ │ └── utils
│ │ ├── Trainer.py
│ │ └── __init__.py
│ ├── synthesizer
│ │ ├── LICENSE.md
│ │ ├── __init__.py
│ │ ├── configs
│ │ │ ├── __init__.py
│ │ │ ├── config.py
│ │ │ ├── hparams.py
│ │ │ └── tacotron_config.yaml
│ │ ├── data
│ │ │ ├── __init__.py
│ │ │ ├── audio.py
│ │ │ ├── dataset.py
│ │ │ └── preprocess.py
│ │ ├── models
│ │ │ ├── __init__.py
│ │ │ └── tacotron.py
│ │ ├── synthesize.py
│ │ ├── synthesizer_manager.py
│ │ ├── trainer.py
│ │ └── utils
│ │ ├── __init__.py
│ │ ├── cleaners.py
│ │ ├── logmmse.py
│ │ ├── numbers.py
│ │ ├── plot.py
│ │ ├── symbols.py
│ │ └── text.py
│ ├── tts_module_manager.py
│ └── vocoder
│ ├── __init__.py
│ ├── configs
│ │ ├── __init__.py
│ │ ├── config.py
│ │ ├── hparams.py
│ │ └── wavernn_config.yaml
│ ├── data
│ │ ├── __init__.py
│ │ ├── dataset.py
│ │ └── preprocess.py
│ ├── models
│ │ ├── __init__.py
│ │ └── wavernn.py
│ ├── utils
│ │ ├── Trainer.py
│ │ ├── __init__.py
│ │ ├── audio.py
│ │ ├── distribution.py
│ │ └── gen_wavernn.py
│ └── vocoder_manager.py
└── utils
└── __init__.py Запустите pip3 install . из корневого каталога.
Мы внедрили полную обработку для набора данных Libraspeech для энкодера, синтезатора и Vocoder. Можно скачать набор данных Libraspeech по этой ссылке. Кроме того, для динамика Encoder мы реализовали интерфейс для использования пользовательского набора данных. Нужно реализовать функции интерфейса PreprocessDataset , функции интерфейса WavPreprocessor , функции интерфейса WavPreprocessor или использовать реализованные.
Для базовых моделей конфигурации по умолчанию будут загружены автоматически. Чтобы изменить их, можно использовать update_config(...) в osms/common/configs/config.py . Для загрузки конфигурации по умолчанию можно использовать get_default_<module_name>_config(...) . Кроме того, можно реализовать свои собственные конфигурации, чтобы использовать их для других моделей.
Для работы с каждым тремя модулями мы реализовали его собственного менеджера: SpeakerEncoderManager , SynthesizerManager , VocoderManager . Как главный менеджер, мы внедрили MustiSpreakerManager , который дает доступ ко всем трем менеджерам. Можно использовать их для вывода всей модели TTS и обучать каждые модули отдельно или вместе. Пример использования можно найти в записной книжке.
Базовые контрольные точки загружаются автоматически в каталоге checkpoints с созданием объекта Multipeaker. Кроме того, можно использовать другие контрольно -пропускные пункты, путем простого обновления конфигурации (изменить ... CAPEPOINT_DIR_PATH, CHACKPOINT_NAME).


