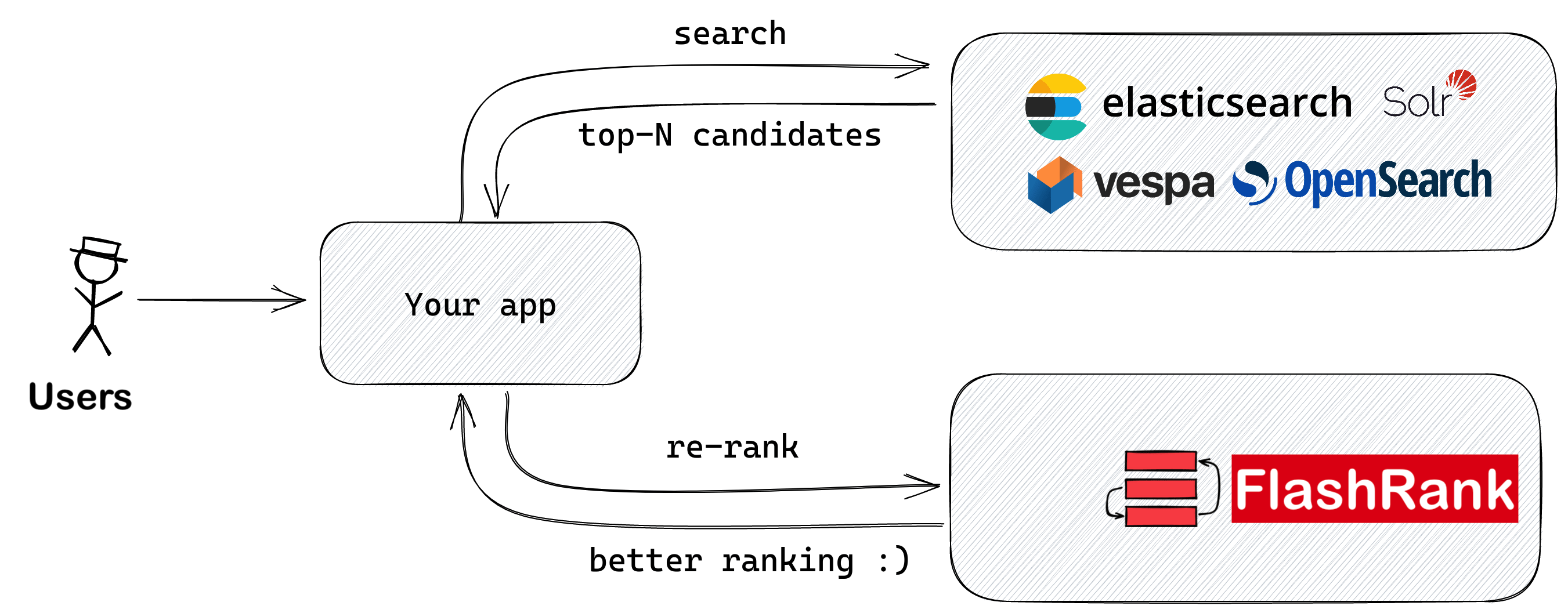
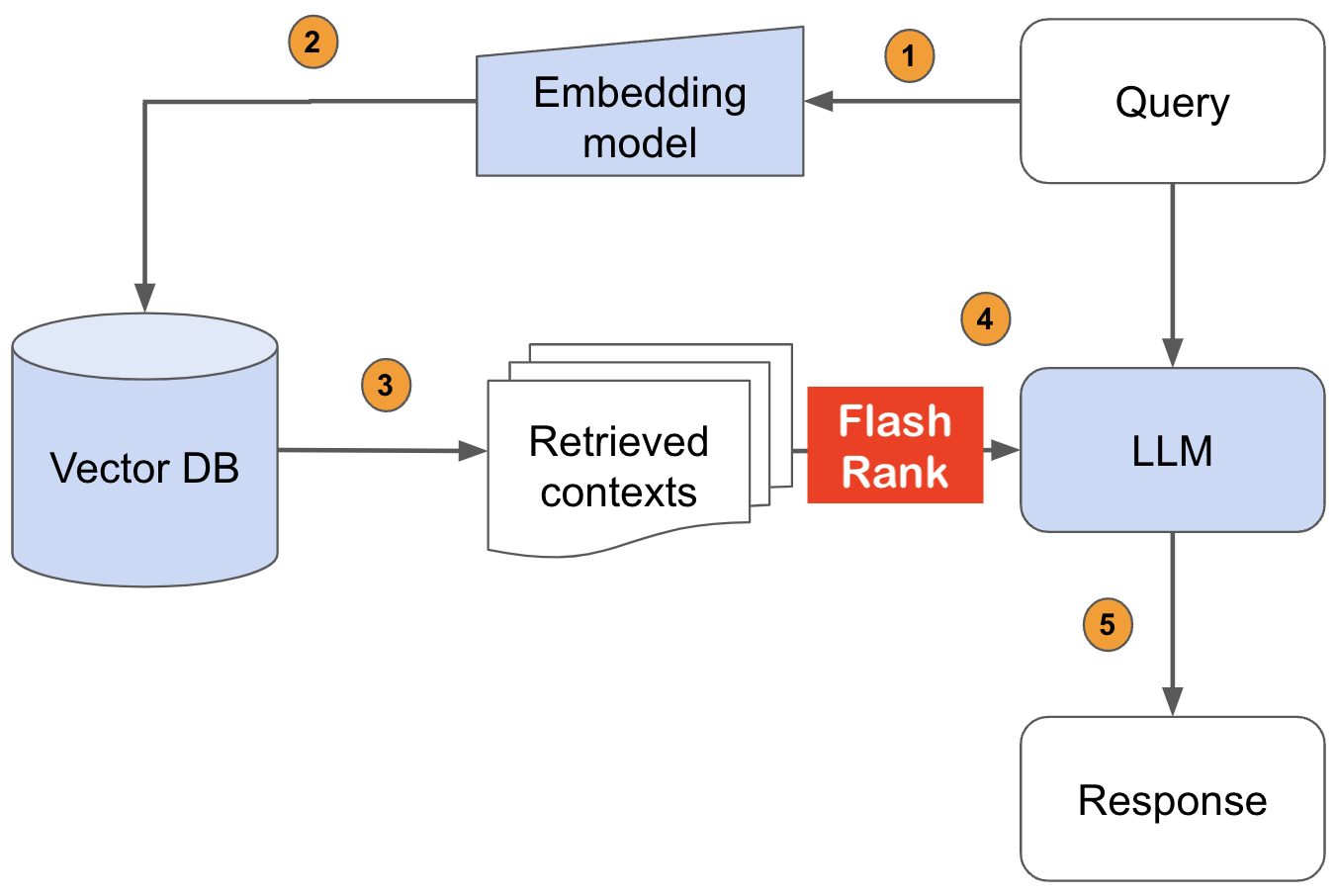
FlashRank
Minor fixes

在输入LLMS之前,将与SOTA成对或ListWise Rerankers重新排列您的搜索结果
Ultra-lite&Super-Fast Python库,可在您现有的搜索和检索管道中添加重新排列。它基于Sota LLM和交叉编码器,并感谢所有模型所有者。
支持:
Max tokens = 512 )Max tokens = 8192 )⚡超轻型:
⏱️超级快:

? $ concious :
基于SOTA跨编码器和其他模型:
| 模型名称 | 描述 | 尺寸 | 笔记 |
|---|---|---|---|
ms-marco-TinyBERT-L-2-v2 | 默认模型 | 〜4MB | 型号卡 |
ms-marco-MiniLM-L-12-v2 | Best Cross-encoder reranker | 〜34MB | 型号卡 |
rank-T5-flan | 最佳的非跨编码器reranker | 〜110MB | 型号卡 |
ms-marco-MultiBERT-L-12 | 多语言,支持100多种语言 | 〜150MB | 支持的语言 |
ce-esci-MiniLM-L12-v2 | 在Amazon ESCI数据集上进行了微调 | - | 型号卡 |
rank_zephyr_7b_v1_full | 4位定量的GGUF | 〜4GB | 型号卡 |
miniReranker_arabic_v1 | Only dedicated Arabic Reranker | - | 型号卡 |
pip install flashrank pip install flashrank [ listwise ] max_length值应该很大,能够适应您最长的段落。换句话说,如果您最长的段落(100个令牌) +查询(16个令牌)对代币估计为116,然后说设置max_length = 128足够好,以适合[cls]和[sep]之类的保留令牌。使用Openai Tiktoken库库估算令牌密度,如果每个令牌的性能对您来说至关重要。对于较小的通道大小,给出更长的max_length (例如512)将对响应时间产生负面影响。
from flashrank import Ranker , RerankRequest
# Nano (~4MB), blazing fast model & competitive performance (ranking precision).
ranker = Ranker ( max_length = 128 )
or
# Small (~34MB), slightly slower & best performance (ranking precision).
ranker = Ranker ( model_name = "ms-marco-MiniLM-L-12-v2" , cache_dir = "/opt" )
or
# Medium (~110MB), slower model with best zeroshot performance (ranking precision) on out of domain data.
ranker = Ranker ( model_name = "rank-T5-flan" , cache_dir = "/opt" )
or
# Medium (~150MB), slower model with competitive performance (ranking precision) for 100+ languages (don't use for english)
ranker = Ranker ( model_name = "ms-marco-MultiBERT-L-12" , cache_dir = "/opt" )
or
ranker = Ranker ( model_name = "rank_zephyr_7b_v1_full" , max_length = 1024 ) # adjust max_length based on your passage length # Metadata is optional, Id can be your DB ids from your retrieval stage or simple numeric indices.
query = "How to speedup LLMs?"
passages = [
{
"id" : 1 ,
"text" : "Introduce *lookahead decoding*: - a parallel decoding algo to accelerate LLM inference - w/o the need for a draft model or a data store - linearly decreases # decoding steps relative to log(FLOPs) used per decoding step." ,
"meta" : { "additional" : "info1" }
},
{
"id" : 2 ,
"text" : "LLM inference efficiency will be one of the most crucial topics for both industry and academia, simply because the more efficient you are, the more $$$ you will save. vllm project is a must-read for this direction, and now they have just released the paper" ,
"meta" : { "additional" : "info2" }
},
{
"id" : 3 ,
"text" : "There are many ways to increase LLM inference throughput (tokens/second) and decrease memory footprint, sometimes at the same time. Here are a few methods I’ve found effective when working with Llama 2. These methods are all well-integrated with Hugging Face. This list is far from exhaustive; some of these techniques can be used in combination with each other and there are plenty of others to try. - Bettertransformer (Optimum Library): Simply call `model.to_bettertransformer()` on your Hugging Face model for a modest improvement in tokens per second. - Fp4 Mixed-Precision (Bitsandbytes): Requires minimal configuration and dramatically reduces the model's memory footprint. - AutoGPTQ: Time-consuming but leads to a much smaller model and faster inference. The quantization is a one-time cost that pays off in the long run." ,
"meta" : { "additional" : "info3" }
},
{
"id" : 4 ,
"text" : "Ever want to make your LLM inference go brrrrr but got stuck at implementing speculative decoding and finding the suitable draft model? No more pain! Thrilled to unveil Medusa, a simple framework that removes the annoying draft model while getting 2x speedup." ,
"meta" : { "additional" : "info4" }
},
{
"id" : 5 ,
"text" : "vLLM is a fast and easy-to-use library for LLM inference and serving. vLLM is fast with: State-of-the-art serving throughput Efficient management of attention key and value memory with PagedAttention Continuous batching of incoming requests Optimized CUDA kernels" ,
"meta" : { "additional" : "info5" }
}
]
rerankrequest = RerankRequest ( query = query , passages = passages )
results = ranker . rerank ( rerankrequest )
print ( results ) # Reranked output from default reranker
[
{
"id" : 4 ,
"text" : "Ever want to make your LLM inference go brrrrr but got stuck at implementing speculative decoding and finding the suitable draft model? No more pain! Thrilled to unveil Medusa, a simple framework that removes the annoying draft model while getting 2x speedup." ,
"meta" :{
"additional" : "info4"
},
"score" : 0.016847236
},
{
"id" : 5 ,
"text" : "vLLM is a fast and easy-to-use library for LLM inference and serving. vLLM is fast with: State-of-the-art serving throughput Efficient management of attention key and value memory with PagedAttention Continuous batching of incoming requests Optimized CUDA kernels" ,
"meta" :{
"additional" : "info5"
},
"score" : 0.011563735
},
{
"id" : 3 ,
"text" : "There are many ways to increase LLM inference throughput (tokens/second) and decrease memory footprint, sometimes at the same time. Here are a few methods I’ve found effective when working with Llama 2. These methods are all well-integrated with Hugging Face. This list is far from exhaustive; some of these techniques can be used in combination with each other and there are plenty of others to try. - Bettertransformer (Optimum Library): Simply call `model.to_bettertransformer()` on your Hugging Face model for a modest improvement in tokens per second. - Fp4 Mixed-Precision (Bitsandbytes): Requires minimal configuration and dramatically reduces the model's memory footprint. - AutoGPTQ: Time-consuming but leads to a much smaller model and faster inference. The quantization is a one-time cost that pays off in the long run." ,
"meta" :{
"additional" : "info3"
},
"score" : 0.00081340264
},
{
"id" : 1 ,
"text" : "Introduce *lookahead decoding*: - a parallel decoding algo to accelerate LLM inference - w/o the need for a draft model or a data store - linearly decreases # decoding steps relative to log(FLOPs) used per decoding step." ,
"meta" :{
"additional" : "info1"
},
"score" : 0.00063596206
},
{
"id" : 2 ,
"text" : "LLM inference efficiency will be one of the most crucial topics for both industry and academia, simply because the more efficient you are, the more $$$ you will save. vllm project is a must-read for this direction, and now they have just released the paper" ,
"meta" :{
"additional" : "info2"
},
"score" : 0.00024851
}
]

在AWS或其他无服务器环境中,整个VM仅读取,您可能必须创建自己的自定义DIR。您可以在Dockerfile中这样做,并将其用于加载模型(最终作为温暖呼叫之间的缓存)。您可以在INIT期间使用CACHE_DIR参数进行操作。
ranker = Ranker ( model_name = "ms-marco-MiniLM-L-12-v2" , cache_dir = "/opt" )
要在您的工作中引用此存储库,请单击右侧的“引用此存储库”链接(Bewlow Repo描述和标签)
cos-mix:余弦相似性和距离融合以改进信息检索
bryndza在2024年的气候主义中:姿态,目标和仇恨事件检测通过检索型GPT-4和Llama
与气候行动主义有关的推文中的态度和仇恨事件检测 - 案例2024年共享任务
一个名为Swiftrank的克隆库指向我们的模型存储库,我们正在使用临时解决方案来避免这种偷窃。感谢您的耐心和理解。
这个问题已经解决,模型现在在HF中。请升级以继续PIP安装-U闪存。谢谢您的耐心理解


