FlashRank
Minor fixes

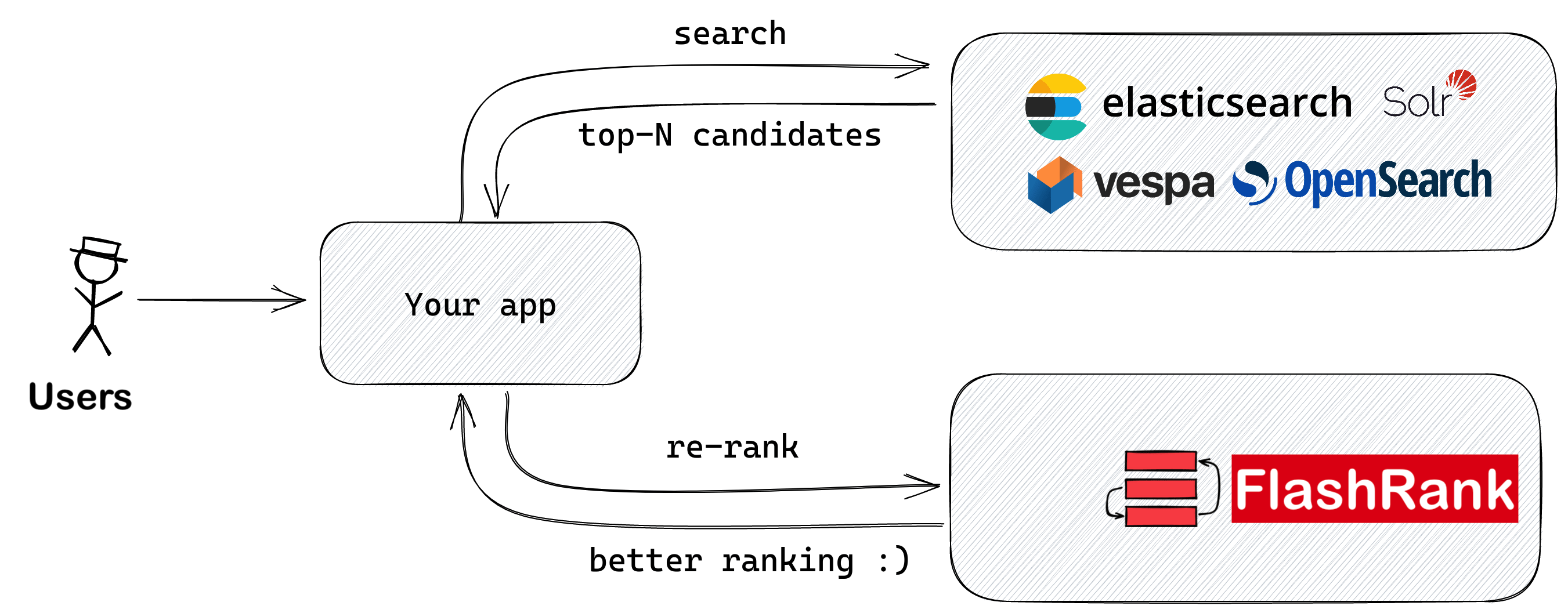
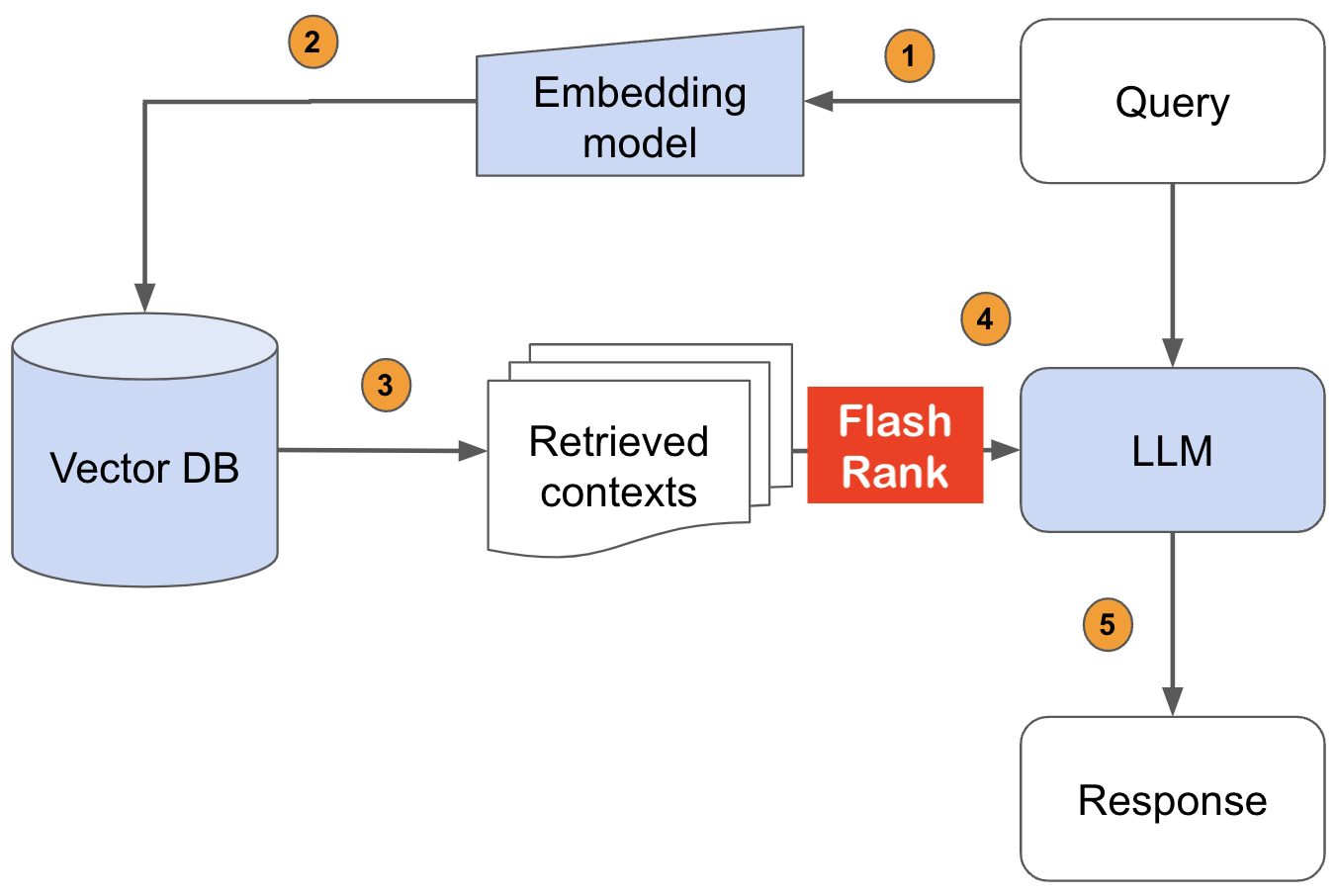
Peringkat ulang hasil pencarian Anda dengan sota berpasangan atau listwise rerankers sebelum dimasukkan ke dalam LLMS Anda
Perpustakaan Python ultra-lite & super cepat untuk menambahkan peringkat ulang ke pipa pencarian & pengambilan yang ada. Ini didasarkan pada sota llms dan cross-encoder, dengan rasa terima kasih kepada semua pemilik model.
Dukungan:
Max tokens = 512 )Max tokens = 8192 )⚡ Ultra-Lite :
⏱️ Super-Fast :

? $ sadar :
Berdasarkan sota silang sota dan model lainnya :
| Nama model | Keterangan | Ukuran | Catatan |
|---|---|---|---|
ms-marco-TinyBERT-L-2-v2 | Model default | ~ 4MB | Kartu model |
ms-marco-MiniLM-L-12-v2 | Best Cross-encoder reranker | ~ 34MB | Kartu model |
rank-T5-flan | Reranker non-cross-encoder terbaik | ~ 110MB | Kartu model |
ms-marco-MultiBERT-L-12 | Multi-bahasa, mendukung 100+ bahasa | ~ 150MB | Bahasa yang didukung |
ce-esci-MiniLM-L12-v2 | Dataset Amazon Esci yang disempurnakan | - | Kartu model |
rank_zephyr_7b_v1_full | GGUF 4-bit-quantised | ~ 4GB | Kartu model |
miniReranker_arabic_v1 | Only dedicated Arabic Reranker | - | Kartu model |
pip install flashrank pip install flashrank [ listwise ] Nilai max_length harus besar dapat mengakomodasi bagian terpanjang Anda. Dengan kata lain jika bagian terpanjang Anda (100 token) + kueri (16 token) berpasangan dengan perkiraan token adalah 116 lalu katakan pengaturan max_length = 128 adalah ruang termasuk yang cukup baik untuk token yang dipesan seperti [cls] dan [sep] Gunakan Openai Tiktoken seperti perpustakaan untuk memperkirakan kepadatan token, jika kinerja per token sangat penting bagi Anda. Non-Chalal memberikan max_length yang lebih panjang seperti 512 untuk ukuran bagian yang lebih kecil akan secara negatif mempengaruhi waktu respons.
from flashrank import Ranker , RerankRequest
# Nano (~4MB), blazing fast model & competitive performance (ranking precision).
ranker = Ranker ( max_length = 128 )
or
# Small (~34MB), slightly slower & best performance (ranking precision).
ranker = Ranker ( model_name = "ms-marco-MiniLM-L-12-v2" , cache_dir = "/opt" )
or
# Medium (~110MB), slower model with best zeroshot performance (ranking precision) on out of domain data.
ranker = Ranker ( model_name = "rank-T5-flan" , cache_dir = "/opt" )
or
# Medium (~150MB), slower model with competitive performance (ranking precision) for 100+ languages (don't use for english)
ranker = Ranker ( model_name = "ms-marco-MultiBERT-L-12" , cache_dir = "/opt" )
or
ranker = Ranker ( model_name = "rank_zephyr_7b_v1_full" , max_length = 1024 ) # adjust max_length based on your passage length # Metadata is optional, Id can be your DB ids from your retrieval stage or simple numeric indices.
query = "How to speedup LLMs?"
passages = [
{
"id" : 1 ,
"text" : "Introduce *lookahead decoding*: - a parallel decoding algo to accelerate LLM inference - w/o the need for a draft model or a data store - linearly decreases # decoding steps relative to log(FLOPs) used per decoding step." ,
"meta" : { "additional" : "info1" }
},
{
"id" : 2 ,
"text" : "LLM inference efficiency will be one of the most crucial topics for both industry and academia, simply because the more efficient you are, the more $$$ you will save. vllm project is a must-read for this direction, and now they have just released the paper" ,
"meta" : { "additional" : "info2" }
},
{
"id" : 3 ,
"text" : "There are many ways to increase LLM inference throughput (tokens/second) and decrease memory footprint, sometimes at the same time. Here are a few methods I’ve found effective when working with Llama 2. These methods are all well-integrated with Hugging Face. This list is far from exhaustive; some of these techniques can be used in combination with each other and there are plenty of others to try. - Bettertransformer (Optimum Library): Simply call `model.to_bettertransformer()` on your Hugging Face model for a modest improvement in tokens per second. - Fp4 Mixed-Precision (Bitsandbytes): Requires minimal configuration and dramatically reduces the model's memory footprint. - AutoGPTQ: Time-consuming but leads to a much smaller model and faster inference. The quantization is a one-time cost that pays off in the long run." ,
"meta" : { "additional" : "info3" }
},
{
"id" : 4 ,
"text" : "Ever want to make your LLM inference go brrrrr but got stuck at implementing speculative decoding and finding the suitable draft model? No more pain! Thrilled to unveil Medusa, a simple framework that removes the annoying draft model while getting 2x speedup." ,
"meta" : { "additional" : "info4" }
},
{
"id" : 5 ,
"text" : "vLLM is a fast and easy-to-use library for LLM inference and serving. vLLM is fast with: State-of-the-art serving throughput Efficient management of attention key and value memory with PagedAttention Continuous batching of incoming requests Optimized CUDA kernels" ,
"meta" : { "additional" : "info5" }
}
]
rerankrequest = RerankRequest ( query = query , passages = passages )
results = ranker . rerank ( rerankrequest )
print ( results ) # Reranked output from default reranker
[
{
"id" : 4 ,
"text" : "Ever want to make your LLM inference go brrrrr but got stuck at implementing speculative decoding and finding the suitable draft model? No more pain! Thrilled to unveil Medusa, a simple framework that removes the annoying draft model while getting 2x speedup." ,
"meta" :{
"additional" : "info4"
},
"score" : 0.016847236
},
{
"id" : 5 ,
"text" : "vLLM is a fast and easy-to-use library for LLM inference and serving. vLLM is fast with: State-of-the-art serving throughput Efficient management of attention key and value memory with PagedAttention Continuous batching of incoming requests Optimized CUDA kernels" ,
"meta" :{
"additional" : "info5"
},
"score" : 0.011563735
},
{
"id" : 3 ,
"text" : "There are many ways to increase LLM inference throughput (tokens/second) and decrease memory footprint, sometimes at the same time. Here are a few methods I’ve found effective when working with Llama 2. These methods are all well-integrated with Hugging Face. This list is far from exhaustive; some of these techniques can be used in combination with each other and there are plenty of others to try. - Bettertransformer (Optimum Library): Simply call `model.to_bettertransformer()` on your Hugging Face model for a modest improvement in tokens per second. - Fp4 Mixed-Precision (Bitsandbytes): Requires minimal configuration and dramatically reduces the model's memory footprint. - AutoGPTQ: Time-consuming but leads to a much smaller model and faster inference. The quantization is a one-time cost that pays off in the long run." ,
"meta" :{
"additional" : "info3"
},
"score" : 0.00081340264
},
{
"id" : 1 ,
"text" : "Introduce *lookahead decoding*: - a parallel decoding algo to accelerate LLM inference - w/o the need for a draft model or a data store - linearly decreases # decoding steps relative to log(FLOPs) used per decoding step." ,
"meta" :{
"additional" : "info1"
},
"score" : 0.00063596206
},
{
"id" : 2 ,
"text" : "LLM inference efficiency will be one of the most crucial topics for both industry and academia, simply because the more efficient you are, the more $$$ you will save. vllm project is a must-read for this direction, and now they have just released the paper" ,
"meta" :{
"additional" : "info2"
},
"score" : 0.00024851
}
]

Di AWS atau lingkungan tanpa server lainnya, seluruh VM hanya baca-baca, Anda mungkin harus membuat Dir kustom Anda sendiri. Anda dapat melakukannya di dockerfile Anda dan menggunakannya untuk memuat model (dan akhirnya sebagai cache di antara panggilan hangat). Anda dapat melakukannya selama init dengan parameter Cache_dir.
ranker = Ranker ( model_name = "ms-marco-MiniLM-L-12-v2" , cache_dir = "/opt" )
Untuk mengutip repositori ini dalam karya Anda, klik tautan "CITE This Repository" di sisi kanan (deskripsi dan tag repo bewlow)
COS-MIX: Kesamaan kosinus dan fusi jarak untuk peningkatan pengambilan informasi
Bryndza di klimateaktivisme 2024: deteksi peristiwa target, target dan kebencian melalui pengambilan gpt-4 dan llama pengambilan
Deteksi peristiwa pendirian dan kebencian dalam tweet terkait dengan aktivisme iklim - tugas bersama pada kasus 2024
Perpustakaan klon yang disebut SwifTrank menunjuk ke ember model kami, kami sedang mengerjakan solusi sementara untuk menghindari pencurian ini . Terima kasih atas kesabaran dan pengertiannya.
Masalah ini diselesaikan, modelnya ada di HF sekarang. Harap upgrade untuk melanjutkan pemasangan PIP -U FlashRank. Terima kasih atas kesabaran dan pengertian


