FlashRank
Minor fixes

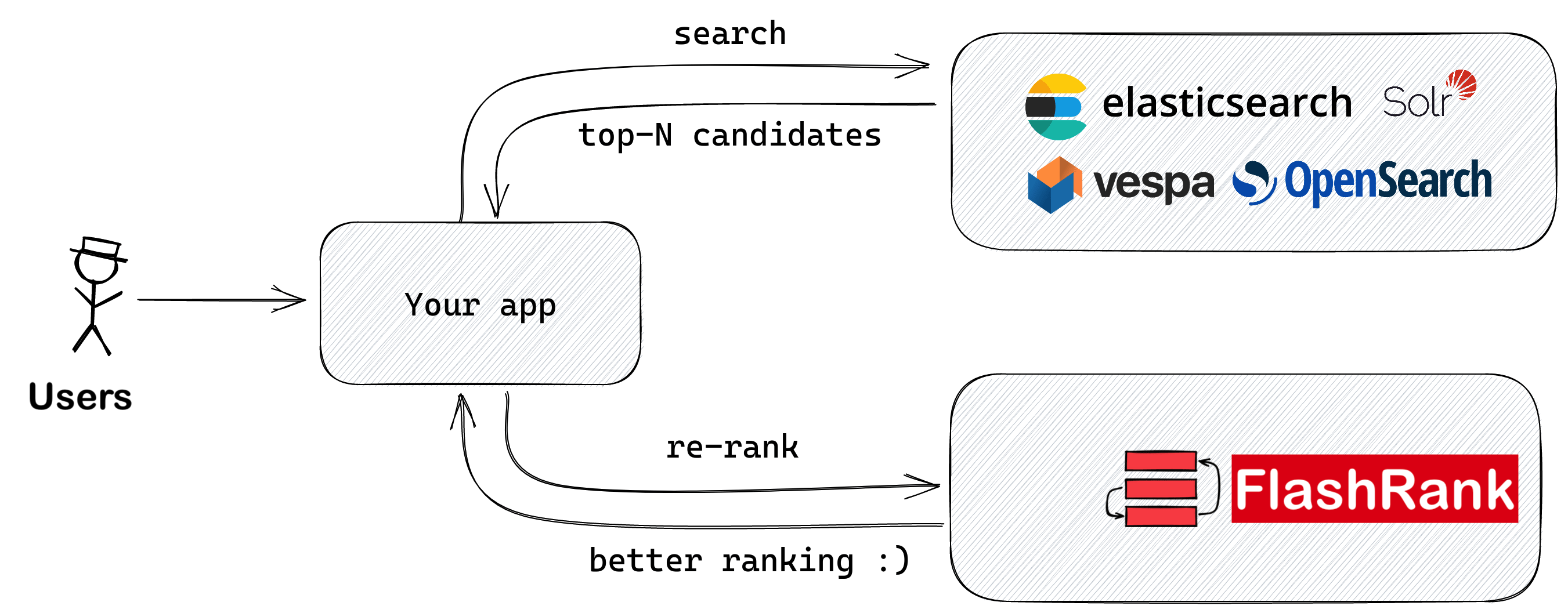
Ringen Sie Ihre Suchergebnisse erneut mit SOTA paarweise oder Listheitsverkleidung, bevor Sie in Ihre LLMs einfügen
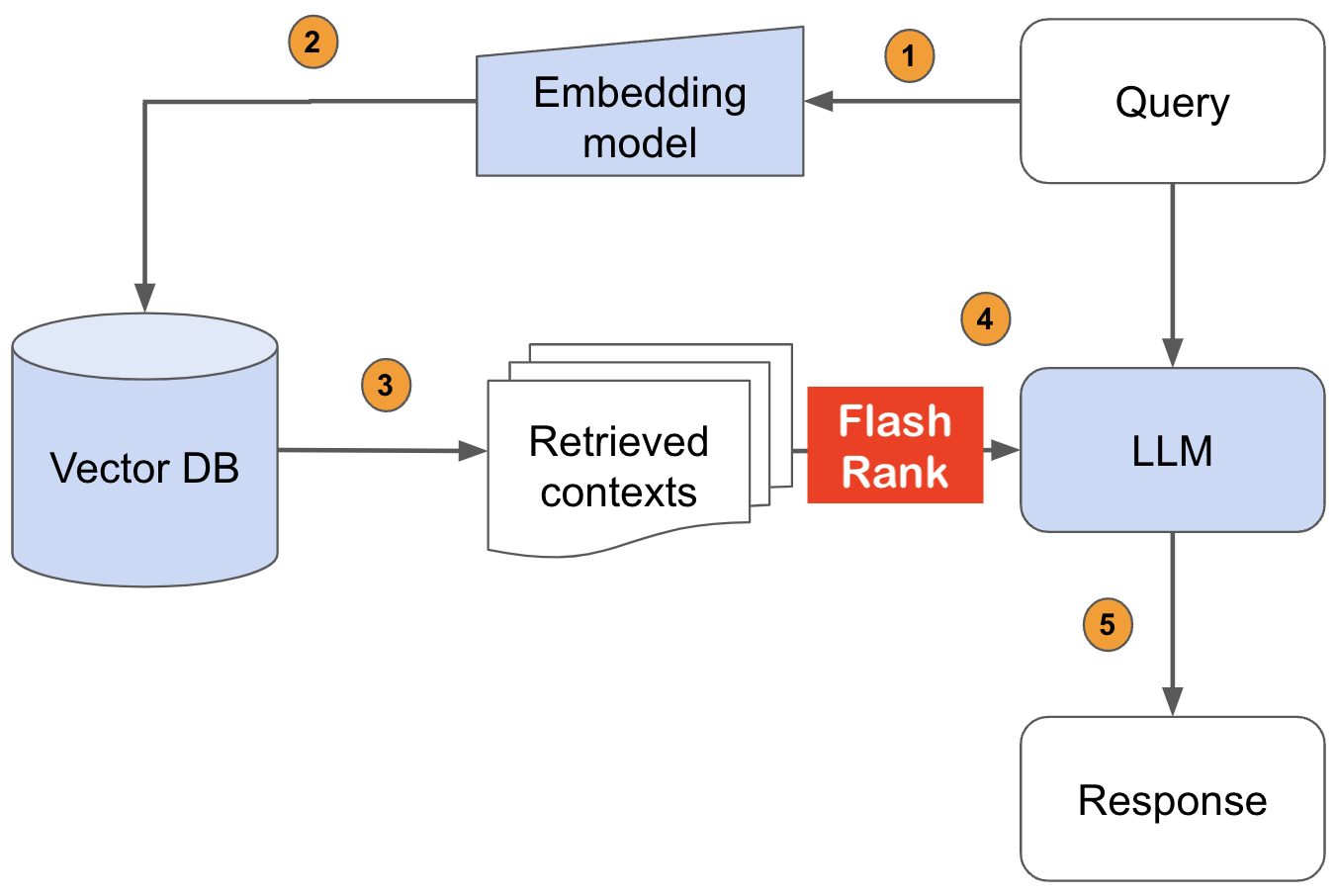
Ultra-Lite & Super-Fast-Python-Bibliothek, um Ihre vorhandenen Such- und Abrufpipelines erneut zu ranken. Es basiert auf SOTA LLMS und Cross-Codern, mit Dankbarkeit allen Modellbesitzern.
Unterstützung:
Max tokens = 512 )Max tokens = 8192 )⚡ Ultra-Lite :
⏱️ superschnitzer :

? $ bekontral :
Basierend auf SOTA Cross-Codern und anderen Modellen :
| Modellname | Beschreibung | Größe | Notizen |
|---|---|---|---|
ms-marco-TinyBERT-L-2-v2 | Standardmodell | ~ 4 MB | Modellkarte |
ms-marco-MiniLM-L-12-v2 | Best Cross-encoder reranker | ~ 34MB | Modellkarte |
rank-T5-flan | Bester Non-Cross-Coder-Reranker | ~ 110 MB | Modellkarte |
ms-marco-MultiBERT-L-12 | Multi-Lingual unterstützt mehr als 100 Sprachen | ~ 150 MB | Unterstützte Sprachen |
ce-esci-MiniLM-L12-v2 | Fein abgestimmt auf Amazon Esci-Datensatz | - - | Modellkarte |
rank_zephyr_7b_v1_full | 4-Bit-quantisierter GGUF | ~ 4 GB | Modellkarte |
miniReranker_arabic_v1 | Only dedicated Arabic Reranker | - - | Modellkarte |
pip install flashrank pip install flashrank [ listwise ] max_length -Wert sollte groß sein, um Ihre längste Passage zu erhalten. Mit anderen Worten, wenn Ihre längste Passage (100 Token) + Abfrage (16 Token) nach einer Token -Schätzung 116 ist, sagen Sie, dass max_length = 128 gut genug ist, einschließlich Raum für reservierte Token wie [CLS] und [Sep]. Verwenden Sie Openai Tiktoken wie Bibliotheken, um die Token -Dichte abzuschätzen, wenn die Leistung pro Token für Sie von entscheidender Bedeutung ist. Nichtchalant eine längere max_length wie 512 für kleinere Durchgangsgrößen wirkt sich negativ auf die Reaktionszeit aus.
from flashrank import Ranker , RerankRequest
# Nano (~4MB), blazing fast model & competitive performance (ranking precision).
ranker = Ranker ( max_length = 128 )
or
# Small (~34MB), slightly slower & best performance (ranking precision).
ranker = Ranker ( model_name = "ms-marco-MiniLM-L-12-v2" , cache_dir = "/opt" )
or
# Medium (~110MB), slower model with best zeroshot performance (ranking precision) on out of domain data.
ranker = Ranker ( model_name = "rank-T5-flan" , cache_dir = "/opt" )
or
# Medium (~150MB), slower model with competitive performance (ranking precision) for 100+ languages (don't use for english)
ranker = Ranker ( model_name = "ms-marco-MultiBERT-L-12" , cache_dir = "/opt" )
or
ranker = Ranker ( model_name = "rank_zephyr_7b_v1_full" , max_length = 1024 ) # adjust max_length based on your passage length # Metadata is optional, Id can be your DB ids from your retrieval stage or simple numeric indices.
query = "How to speedup LLMs?"
passages = [
{
"id" : 1 ,
"text" : "Introduce *lookahead decoding*: - a parallel decoding algo to accelerate LLM inference - w/o the need for a draft model or a data store - linearly decreases # decoding steps relative to log(FLOPs) used per decoding step." ,
"meta" : { "additional" : "info1" }
},
{
"id" : 2 ,
"text" : "LLM inference efficiency will be one of the most crucial topics for both industry and academia, simply because the more efficient you are, the more $$$ you will save. vllm project is a must-read for this direction, and now they have just released the paper" ,
"meta" : { "additional" : "info2" }
},
{
"id" : 3 ,
"text" : "There are many ways to increase LLM inference throughput (tokens/second) and decrease memory footprint, sometimes at the same time. Here are a few methods I’ve found effective when working with Llama 2. These methods are all well-integrated with Hugging Face. This list is far from exhaustive; some of these techniques can be used in combination with each other and there are plenty of others to try. - Bettertransformer (Optimum Library): Simply call `model.to_bettertransformer()` on your Hugging Face model for a modest improvement in tokens per second. - Fp4 Mixed-Precision (Bitsandbytes): Requires minimal configuration and dramatically reduces the model's memory footprint. - AutoGPTQ: Time-consuming but leads to a much smaller model and faster inference. The quantization is a one-time cost that pays off in the long run." ,
"meta" : { "additional" : "info3" }
},
{
"id" : 4 ,
"text" : "Ever want to make your LLM inference go brrrrr but got stuck at implementing speculative decoding and finding the suitable draft model? No more pain! Thrilled to unveil Medusa, a simple framework that removes the annoying draft model while getting 2x speedup." ,
"meta" : { "additional" : "info4" }
},
{
"id" : 5 ,
"text" : "vLLM is a fast and easy-to-use library for LLM inference and serving. vLLM is fast with: State-of-the-art serving throughput Efficient management of attention key and value memory with PagedAttention Continuous batching of incoming requests Optimized CUDA kernels" ,
"meta" : { "additional" : "info5" }
}
]
rerankrequest = RerankRequest ( query = query , passages = passages )
results = ranker . rerank ( rerankrequest )
print ( results ) # Reranked output from default reranker
[
{
"id" : 4 ,
"text" : "Ever want to make your LLM inference go brrrrr but got stuck at implementing speculative decoding and finding the suitable draft model? No more pain! Thrilled to unveil Medusa, a simple framework that removes the annoying draft model while getting 2x speedup." ,
"meta" :{
"additional" : "info4"
},
"score" : 0.016847236
},
{
"id" : 5 ,
"text" : "vLLM is a fast and easy-to-use library for LLM inference and serving. vLLM is fast with: State-of-the-art serving throughput Efficient management of attention key and value memory with PagedAttention Continuous batching of incoming requests Optimized CUDA kernels" ,
"meta" :{
"additional" : "info5"
},
"score" : 0.011563735
},
{
"id" : 3 ,
"text" : "There are many ways to increase LLM inference throughput (tokens/second) and decrease memory footprint, sometimes at the same time. Here are a few methods I’ve found effective when working with Llama 2. These methods are all well-integrated with Hugging Face. This list is far from exhaustive; some of these techniques can be used in combination with each other and there are plenty of others to try. - Bettertransformer (Optimum Library): Simply call `model.to_bettertransformer()` on your Hugging Face model for a modest improvement in tokens per second. - Fp4 Mixed-Precision (Bitsandbytes): Requires minimal configuration and dramatically reduces the model's memory footprint. - AutoGPTQ: Time-consuming but leads to a much smaller model and faster inference. The quantization is a one-time cost that pays off in the long run." ,
"meta" :{
"additional" : "info3"
},
"score" : 0.00081340264
},
{
"id" : 1 ,
"text" : "Introduce *lookahead decoding*: - a parallel decoding algo to accelerate LLM inference - w/o the need for a draft model or a data store - linearly decreases # decoding steps relative to log(FLOPs) used per decoding step." ,
"meta" :{
"additional" : "info1"
},
"score" : 0.00063596206
},
{
"id" : 2 ,
"text" : "LLM inference efficiency will be one of the most crucial topics for both industry and academia, simply because the more efficient you are, the more $$$ you will save. vllm project is a must-read for this direction, and now they have just released the paper" ,
"meta" :{
"additional" : "info2"
},
"score" : 0.00024851
}
]

In AWS oder anderen serverlosen Umgebungen ist die gesamte VM schreibgeschützt. Möglicherweise müssen Sie möglicherweise Ihr eigenes benutzerdefiniertes Dir erstellen. Sie können dies in Ihrer Dockerfile tun und sie zum Laden der Modelle verwenden (und schließlich als Cache zwischen warmen Aufrufen). Sie können dies während der Init mit dem Parameter cache_dir tun.
ranker = Ranker ( model_name = "ms-marco-MiniLM-L-12-v2" , cache_dir = "/opt" )
Um dieses Repository in Ihrer Arbeit zu zitieren, klicken Sie auf der rechten Seite auf den Link "dieses Repository zitieren" (Bewlow Repo -Beschreibungen und -Tags).
COS-MIX: Ähnlichkeit der Cosinus und Distanzfusion für ein verbessertes Informationsabruf
Bryndza bei ClimateActivism 2024: Erkennung von Haltung, Ziel- und Hass-Ereignis durch retrieval-aushusterte GPT-4 und Lama
Erkennung von Haltung und Hassereignis in Tweets im Zusammenhang mit Klimaaktivismus - gemeinsame Aufgabe bei Fall 2024
Eine Klonbibliothek namens Swiftrank zeigt auf unsere Modellkläger. Wir arbeiten an einer Zwischenlösung, um dieses Diebstahl zu vermeiden . Vielen Dank für Geduld und Verständnis.
Dieses Problem ist behoben, die Modelle sind jetzt in HF. Bitte upgraden Sie ein Upgrade, um die PIP Install -u FlashRank fortzusetzen . Vielen Dank für Geduld und Verständnis


