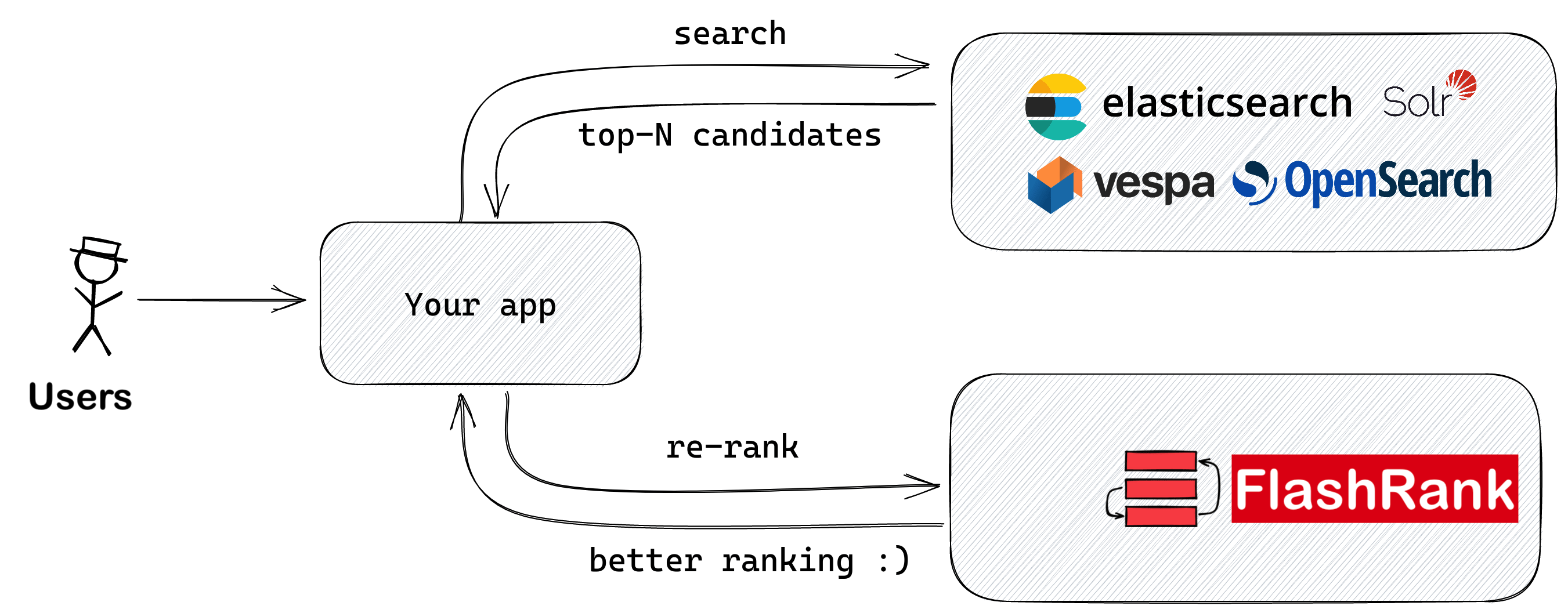
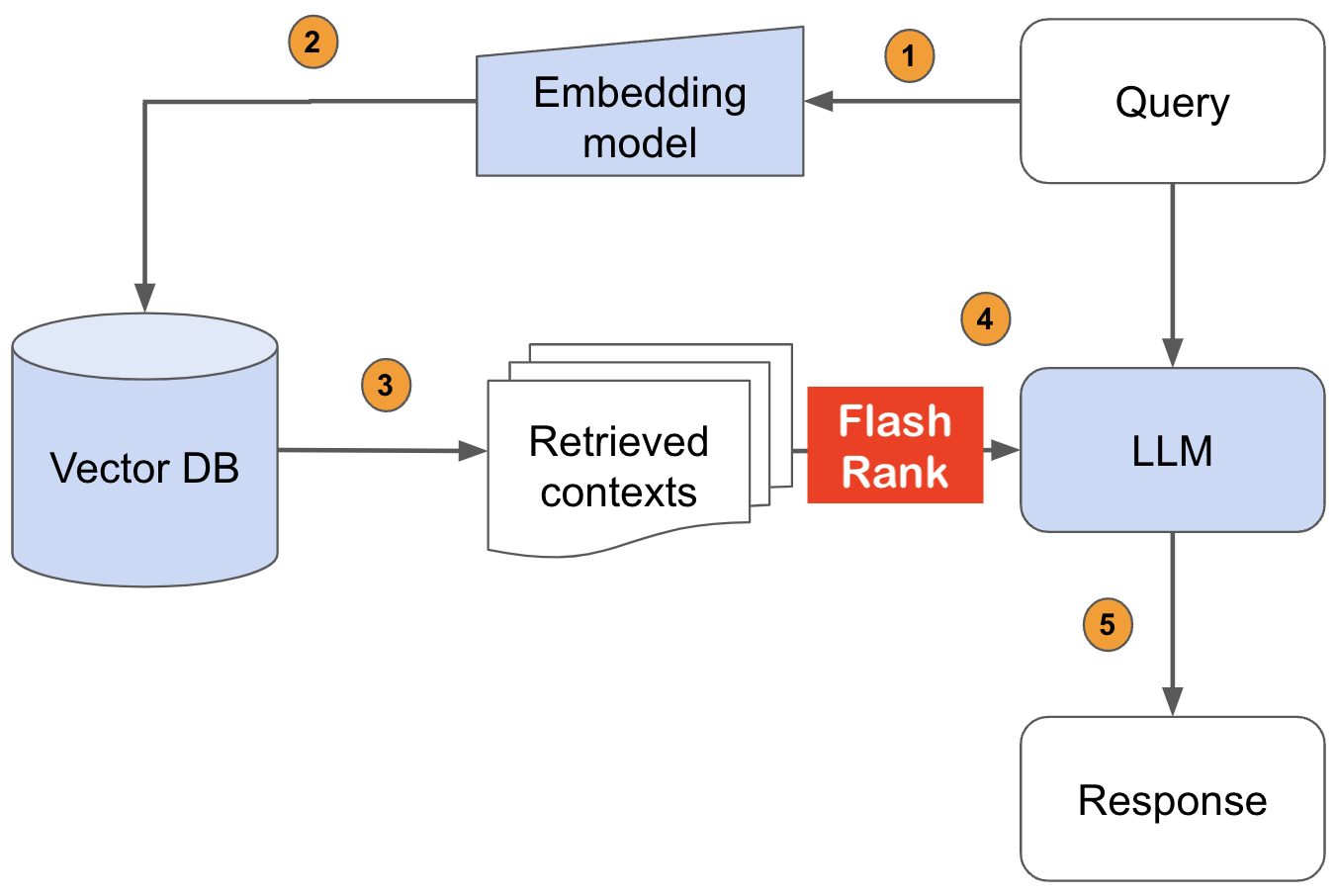
FlashRank
Minor fixes

أعد تشغيل نتائج البحث الخاصة بك مع SOTA Pairwise أو Listwise Rerankers قبل التغذية في LLMS
مكتبة Python Ultra-Lite و Super-Fast لإضافة إعادة التصنيف إلى خطوط أنابيب البحث والاسترجاع الحالية. يعتمد على Sota LLMs و Acteders ، مع امتنان لجميع مالكي النماذج.
يدعم:
Max tokens = 512 )Max tokens = 8192 )⚡ Ultra-Lite :
⏱ فائق السرعة :

؟ $ cincious :
استنادًا إلى أجهزة الترميز المتقاطعة SOTA والنماذج الأخرى :
| اسم النموذج | وصف | مقاس | ملحوظات |
|---|---|---|---|
ms-marco-TinyBERT-L-2-v2 | النموذج الافتراضي | ~ 4MB | بطاقة النموذج |
ms-marco-MiniLM-L-12-v2 | Best Cross-encoder reranker | ~ 34 ميجابايت | بطاقة النموذج |
rank-T5-flan | أفضل عارض غير مشفر | ~ 110 ميجابايت | بطاقة النموذج |
ms-marco-MultiBERT-L-12 | متعدد اللغات ، يدعم 100+ لغة | ~ 150 ميجابايت | اللغات المدعومة |
ce-esci-MiniLM-L12-v2 | تم ضبطها على مجموعة بيانات Amazon Esci | - | بطاقة النموذج |
rank_zephyr_7b_v1_full | 4 بت gguf المسبق | ~ 4 جيجابايت | بطاقة النموذج |
miniReranker_arabic_v1 | Only dedicated Arabic Reranker | - | بطاقة النموذج |
pip install flashrank pip install flashrank [ listwise ] يجب أن تكون قيمة max_length كبيرة قادرة على استيعاب أطول ممر. بمعنى آخر ، إذا كان أطول ممر (100 رمز) + زوج الاستعلام (16 رمزًا) حسب تقدير الرمز المميز هو 116 ، فقل أن الإعداد max_length = 128 هو غرفة جيدة بما فيه الكفاية للرموز المحجوزة مثل [CLS] و [SEP]. استخدم Openai Tiktoken مثل المكتبات لتقدير كثافة الرمز المميز ، إذا كان الأداء لكل رمز أمرًا بالغ الأهمية بالنسبة لك. إن إعطاء max_length أطول مثل 512 لأحجام المرور الأصغر سيؤثر سلبًا على وقت الاستجابة.
from flashrank import Ranker , RerankRequest
# Nano (~4MB), blazing fast model & competitive performance (ranking precision).
ranker = Ranker ( max_length = 128 )
or
# Small (~34MB), slightly slower & best performance (ranking precision).
ranker = Ranker ( model_name = "ms-marco-MiniLM-L-12-v2" , cache_dir = "/opt" )
or
# Medium (~110MB), slower model with best zeroshot performance (ranking precision) on out of domain data.
ranker = Ranker ( model_name = "rank-T5-flan" , cache_dir = "/opt" )
or
# Medium (~150MB), slower model with competitive performance (ranking precision) for 100+ languages (don't use for english)
ranker = Ranker ( model_name = "ms-marco-MultiBERT-L-12" , cache_dir = "/opt" )
or
ranker = Ranker ( model_name = "rank_zephyr_7b_v1_full" , max_length = 1024 ) # adjust max_length based on your passage length # Metadata is optional, Id can be your DB ids from your retrieval stage or simple numeric indices.
query = "How to speedup LLMs?"
passages = [
{
"id" : 1 ,
"text" : "Introduce *lookahead decoding*: - a parallel decoding algo to accelerate LLM inference - w/o the need for a draft model or a data store - linearly decreases # decoding steps relative to log(FLOPs) used per decoding step." ,
"meta" : { "additional" : "info1" }
},
{
"id" : 2 ,
"text" : "LLM inference efficiency will be one of the most crucial topics for both industry and academia, simply because the more efficient you are, the more $$$ you will save. vllm project is a must-read for this direction, and now they have just released the paper" ,
"meta" : { "additional" : "info2" }
},
{
"id" : 3 ,
"text" : "There are many ways to increase LLM inference throughput (tokens/second) and decrease memory footprint, sometimes at the same time. Here are a few methods I’ve found effective when working with Llama 2. These methods are all well-integrated with Hugging Face. This list is far from exhaustive; some of these techniques can be used in combination with each other and there are plenty of others to try. - Bettertransformer (Optimum Library): Simply call `model.to_bettertransformer()` on your Hugging Face model for a modest improvement in tokens per second. - Fp4 Mixed-Precision (Bitsandbytes): Requires minimal configuration and dramatically reduces the model's memory footprint. - AutoGPTQ: Time-consuming but leads to a much smaller model and faster inference. The quantization is a one-time cost that pays off in the long run." ,
"meta" : { "additional" : "info3" }
},
{
"id" : 4 ,
"text" : "Ever want to make your LLM inference go brrrrr but got stuck at implementing speculative decoding and finding the suitable draft model? No more pain! Thrilled to unveil Medusa, a simple framework that removes the annoying draft model while getting 2x speedup." ,
"meta" : { "additional" : "info4" }
},
{
"id" : 5 ,
"text" : "vLLM is a fast and easy-to-use library for LLM inference and serving. vLLM is fast with: State-of-the-art serving throughput Efficient management of attention key and value memory with PagedAttention Continuous batching of incoming requests Optimized CUDA kernels" ,
"meta" : { "additional" : "info5" }
}
]
rerankrequest = RerankRequest ( query = query , passages = passages )
results = ranker . rerank ( rerankrequest )
print ( results ) # Reranked output from default reranker
[
{
"id" : 4 ,
"text" : "Ever want to make your LLM inference go brrrrr but got stuck at implementing speculative decoding and finding the suitable draft model? No more pain! Thrilled to unveil Medusa, a simple framework that removes the annoying draft model while getting 2x speedup." ,
"meta" :{
"additional" : "info4"
},
"score" : 0.016847236
},
{
"id" : 5 ,
"text" : "vLLM is a fast and easy-to-use library for LLM inference and serving. vLLM is fast with: State-of-the-art serving throughput Efficient management of attention key and value memory with PagedAttention Continuous batching of incoming requests Optimized CUDA kernels" ,
"meta" :{
"additional" : "info5"
},
"score" : 0.011563735
},
{
"id" : 3 ,
"text" : "There are many ways to increase LLM inference throughput (tokens/second) and decrease memory footprint, sometimes at the same time. Here are a few methods I’ve found effective when working with Llama 2. These methods are all well-integrated with Hugging Face. This list is far from exhaustive; some of these techniques can be used in combination with each other and there are plenty of others to try. - Bettertransformer (Optimum Library): Simply call `model.to_bettertransformer()` on your Hugging Face model for a modest improvement in tokens per second. - Fp4 Mixed-Precision (Bitsandbytes): Requires minimal configuration and dramatically reduces the model's memory footprint. - AutoGPTQ: Time-consuming but leads to a much smaller model and faster inference. The quantization is a one-time cost that pays off in the long run." ,
"meta" :{
"additional" : "info3"
},
"score" : 0.00081340264
},
{
"id" : 1 ,
"text" : "Introduce *lookahead decoding*: - a parallel decoding algo to accelerate LLM inference - w/o the need for a draft model or a data store - linearly decreases # decoding steps relative to log(FLOPs) used per decoding step." ,
"meta" :{
"additional" : "info1"
},
"score" : 0.00063596206
},
{
"id" : 2 ,
"text" : "LLM inference efficiency will be one of the most crucial topics for both industry and academia, simply because the more efficient you are, the more $$$ you will save. vllm project is a must-read for this direction, and now they have just released the paper" ,
"meta" :{
"additional" : "info2"
},
"score" : 0.00024851
}
]

في AWS أو غيرها من البيئات بدون خادم ، يكون VM بالكامل للقراءة فقط لإنشاء DIR المخصص الخاص بك. يمكنك القيام بذلك في Dockerfile واستخدامه لتحميل النماذج (وفي النهاية كذاكرة التخزين المؤقت بين المكالمات الدافئة). يمكنك القيام بذلك خلال init مع معلمة Cache_Dir.
ranker = Ranker ( model_name = "ms-marco-MiniLM-L-12-v2" , cache_dir = "/opt" )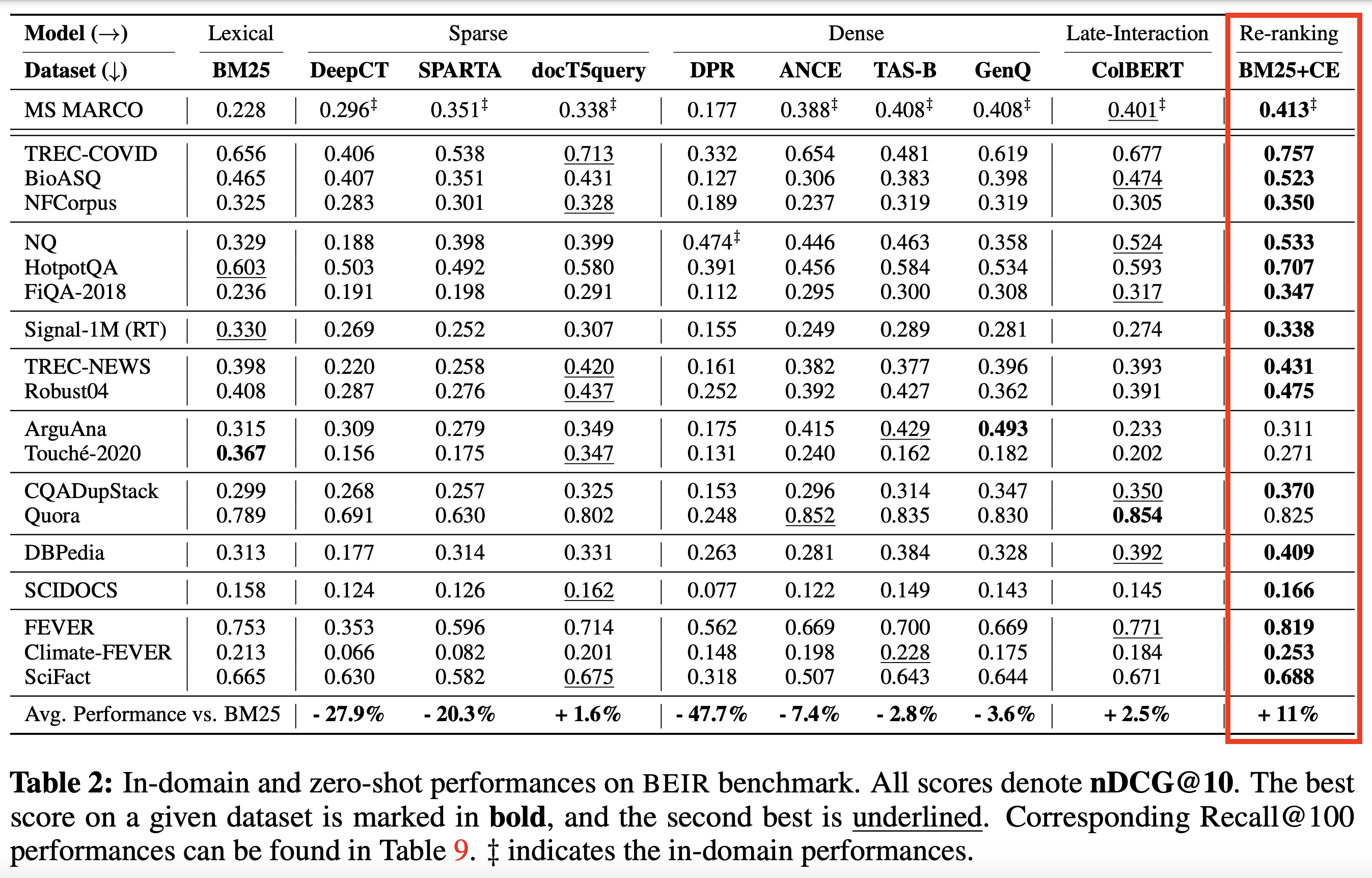
للاستشهاد بهذا المستودع في عملك ، يرجى النقر على رابط "استشهد هذا المستودع" على الجانب الأيمن (أوصاف وعلامات ريبو Bewlow)
COS-MIX: جيب التمام التشابه والانصهار المسافة لتحسين استرجاع المعلومات
بريندزا في ClimateActivism 2024: موقف الموقف والهدف والكراهية عن طريق GPT-4 و Llama.
الكشف عن حدث الموقف والكراهية في التغريدات المتعلقة بنشاط المناخ - المهمة المشتركة في الحالة 2024
تشير مكتبة استنساخ تسمى Swiftrank إلى دلاء النموذج لدينا ، ونحن نعمل على حل مؤقت لتجنب هذا السرقة . شكرا لك على الصبر والتفاهم.
يتم حل هذه المشكلة ، النماذج موجودة في HF الآن. يرجى الترقية لمتابعة تثبيت PIP -U FlashRank. شكرا لك على الصبر والتفاهم


