FlashRank
Minor fixes

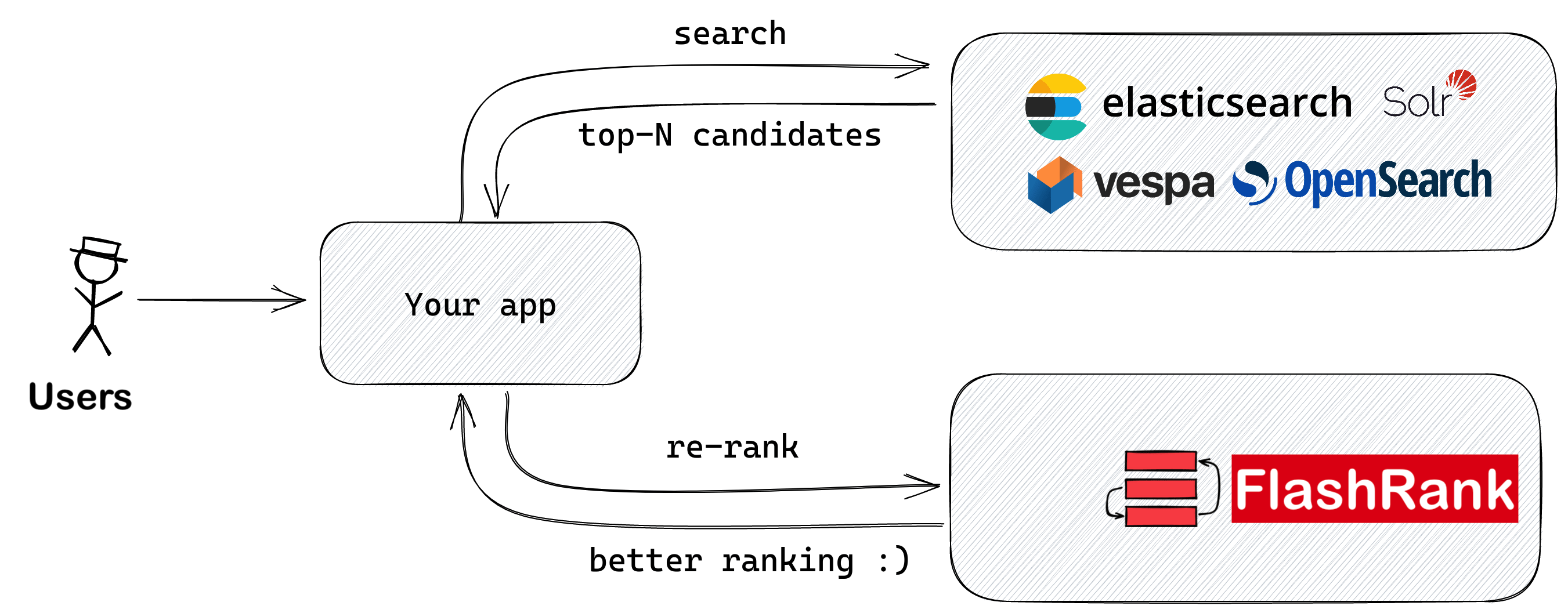
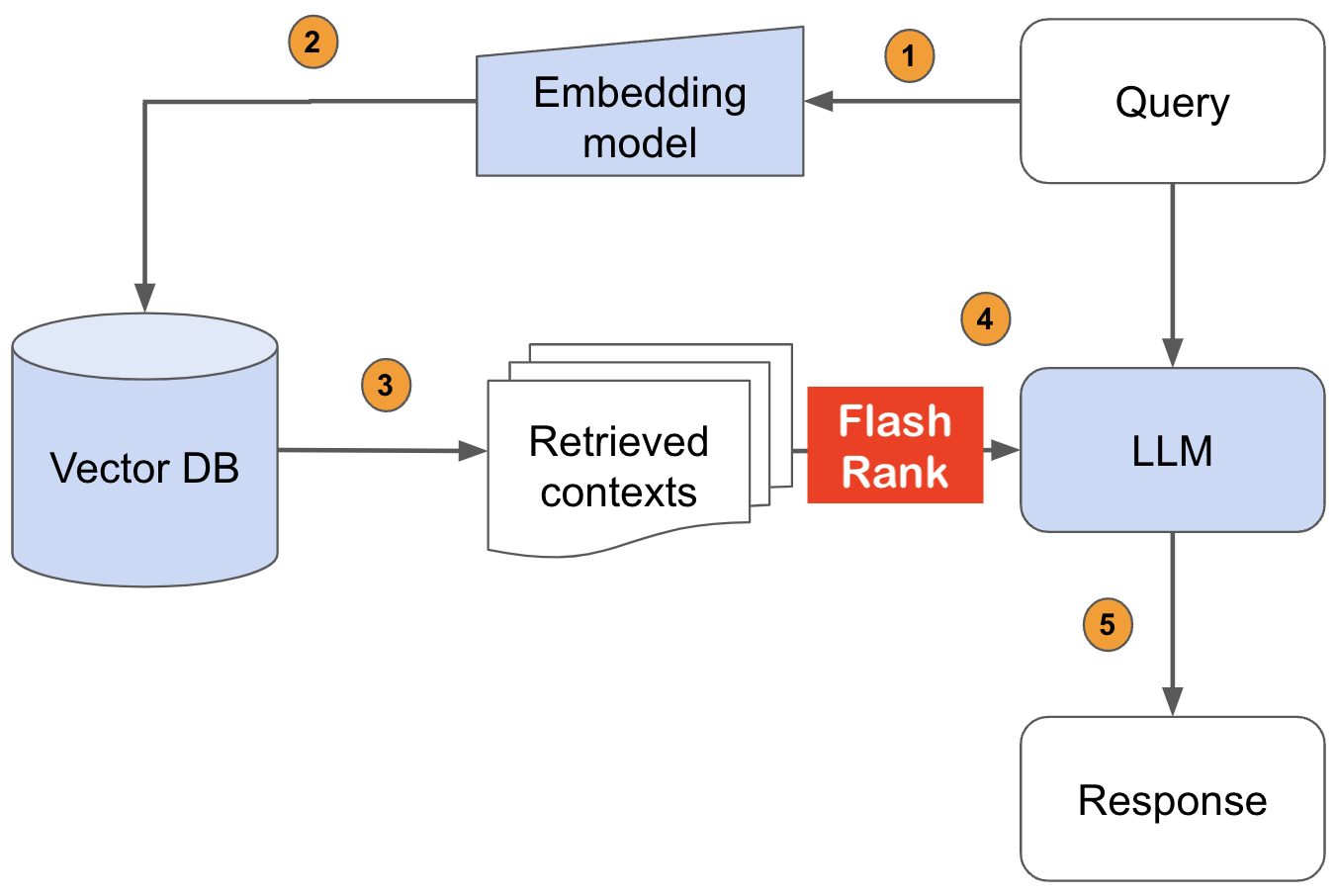
LLM에 공급하기 전에 Sota Pairwise 또는 Listwise Rerankers로 검색 결과를 다시 평가하십시오.
기존 검색 및 검색 파이프 라인에 다시 랭킹을 추가하려면 Ultra-Lite & Super-Fast Python 라이브러리. 그것은 모든 모델 소유자에게 감사를 표하며 Sota LLM 및 크로스 코더를 기반으로합니다.
지원 :
Max tokens = 512 )Max tokens = 8192 )⚡ 울트라 라이트 :
⏱️ 초고속 :

? $ affious :
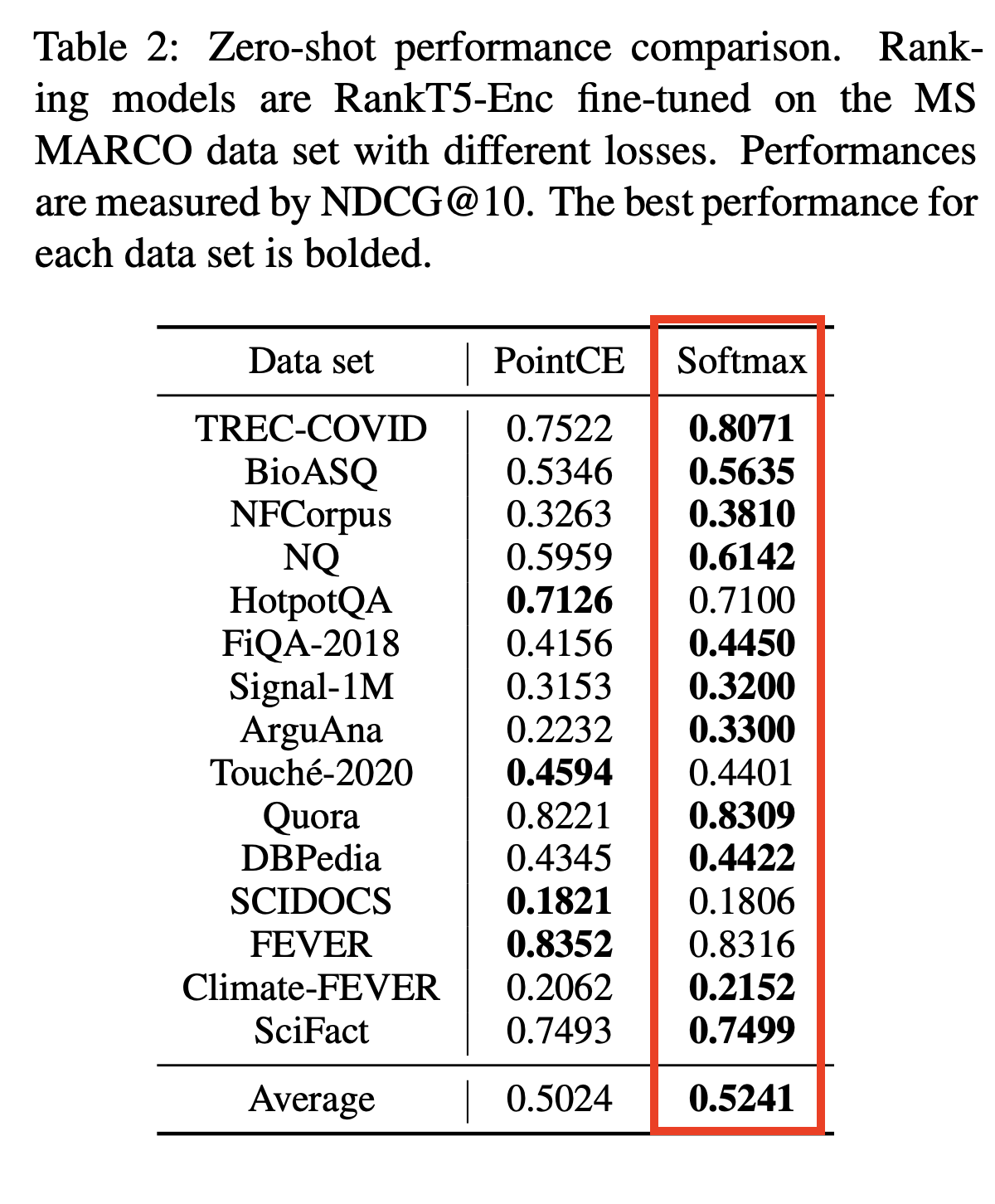
SOTA 크로스 코더 및 기타 모델을 기반으로합니다 .
| 모델 이름 | 설명 | 크기 | 메모 |
|---|---|---|---|
ms-marco-TinyBERT-L-2-v2 | 기본 모델 | ~ 4MB | 모델 카드 |
ms-marco-MiniLM-L-12-v2 | Best Cross-encoder reranker | ~ 34MB | 모델 카드 |
rank-T5-flan | 최고의 비 크로스 코더 재선자 | ~ 110MB | 모델 카드 |
ms-marco-MultiBERT-L-12 | 다국어는 100 개 이상의 언어를 지원합니다 | ~ 150MB | 지원되는 언어 |
ce-esci-MiniLM-L12-v2 | Amazon ESCI 데이터 세트에서 미세 조정 | - | 모델 카드 |
rank_zephyr_7b_v1_full | 4 비트 정량 GGUF | ~ 4GB | 모델 카드 |
miniReranker_arabic_v1 | Only dedicated Arabic Reranker | - | 모델 카드 |
pip install flashrank pip install flashrank [ listwise ] max_length 값은 가장 긴 구절을 호소 할 수 있어야합니다. 다시 말해서, 가장 긴 구절 (100 토큰) + 쿼리 (16 개의 토큰) 쌍 쌍 쌍은 116이면 max_length = 128 을 설정하는 것이 [CLS] 및 [SEP]와 같은 예약 된 토큰을위한 공간을 둘러보기에 충분하다고 가정합니다. 토큰 당 성능이 중요한 경우 토큰 밀도를 추정하기 위해 Openai Tiktoken을 사용하여 토큰 밀도를 추정하십시오. 더 작은 통과 크기에 대해 512와 같은 더 긴 max_length 제공하지 않으면 응답 시간에 부정적인 영향을 미칩니다.
from flashrank import Ranker , RerankRequest
# Nano (~4MB), blazing fast model & competitive performance (ranking precision).
ranker = Ranker ( max_length = 128 )
or
# Small (~34MB), slightly slower & best performance (ranking precision).
ranker = Ranker ( model_name = "ms-marco-MiniLM-L-12-v2" , cache_dir = "/opt" )
or
# Medium (~110MB), slower model with best zeroshot performance (ranking precision) on out of domain data.
ranker = Ranker ( model_name = "rank-T5-flan" , cache_dir = "/opt" )
or
# Medium (~150MB), slower model with competitive performance (ranking precision) for 100+ languages (don't use for english)
ranker = Ranker ( model_name = "ms-marco-MultiBERT-L-12" , cache_dir = "/opt" )
or
ranker = Ranker ( model_name = "rank_zephyr_7b_v1_full" , max_length = 1024 ) # adjust max_length based on your passage length # Metadata is optional, Id can be your DB ids from your retrieval stage or simple numeric indices.
query = "How to speedup LLMs?"
passages = [
{
"id" : 1 ,
"text" : "Introduce *lookahead decoding*: - a parallel decoding algo to accelerate LLM inference - w/o the need for a draft model or a data store - linearly decreases # decoding steps relative to log(FLOPs) used per decoding step." ,
"meta" : { "additional" : "info1" }
},
{
"id" : 2 ,
"text" : "LLM inference efficiency will be one of the most crucial topics for both industry and academia, simply because the more efficient you are, the more $$$ you will save. vllm project is a must-read for this direction, and now they have just released the paper" ,
"meta" : { "additional" : "info2" }
},
{
"id" : 3 ,
"text" : "There are many ways to increase LLM inference throughput (tokens/second) and decrease memory footprint, sometimes at the same time. Here are a few methods I’ve found effective when working with Llama 2. These methods are all well-integrated with Hugging Face. This list is far from exhaustive; some of these techniques can be used in combination with each other and there are plenty of others to try. - Bettertransformer (Optimum Library): Simply call `model.to_bettertransformer()` on your Hugging Face model for a modest improvement in tokens per second. - Fp4 Mixed-Precision (Bitsandbytes): Requires minimal configuration and dramatically reduces the model's memory footprint. - AutoGPTQ: Time-consuming but leads to a much smaller model and faster inference. The quantization is a one-time cost that pays off in the long run." ,
"meta" : { "additional" : "info3" }
},
{
"id" : 4 ,
"text" : "Ever want to make your LLM inference go brrrrr but got stuck at implementing speculative decoding and finding the suitable draft model? No more pain! Thrilled to unveil Medusa, a simple framework that removes the annoying draft model while getting 2x speedup." ,
"meta" : { "additional" : "info4" }
},
{
"id" : 5 ,
"text" : "vLLM is a fast and easy-to-use library for LLM inference and serving. vLLM is fast with: State-of-the-art serving throughput Efficient management of attention key and value memory with PagedAttention Continuous batching of incoming requests Optimized CUDA kernels" ,
"meta" : { "additional" : "info5" }
}
]
rerankrequest = RerankRequest ( query = query , passages = passages )
results = ranker . rerank ( rerankrequest )
print ( results ) # Reranked output from default reranker
[
{
"id" : 4 ,
"text" : "Ever want to make your LLM inference go brrrrr but got stuck at implementing speculative decoding and finding the suitable draft model? No more pain! Thrilled to unveil Medusa, a simple framework that removes the annoying draft model while getting 2x speedup." ,
"meta" :{
"additional" : "info4"
},
"score" : 0.016847236
},
{
"id" : 5 ,
"text" : "vLLM is a fast and easy-to-use library for LLM inference and serving. vLLM is fast with: State-of-the-art serving throughput Efficient management of attention key and value memory with PagedAttention Continuous batching of incoming requests Optimized CUDA kernels" ,
"meta" :{
"additional" : "info5"
},
"score" : 0.011563735
},
{
"id" : 3 ,
"text" : "There are many ways to increase LLM inference throughput (tokens/second) and decrease memory footprint, sometimes at the same time. Here are a few methods I’ve found effective when working with Llama 2. These methods are all well-integrated with Hugging Face. This list is far from exhaustive; some of these techniques can be used in combination with each other and there are plenty of others to try. - Bettertransformer (Optimum Library): Simply call `model.to_bettertransformer()` on your Hugging Face model for a modest improvement in tokens per second. - Fp4 Mixed-Precision (Bitsandbytes): Requires minimal configuration and dramatically reduces the model's memory footprint. - AutoGPTQ: Time-consuming but leads to a much smaller model and faster inference. The quantization is a one-time cost that pays off in the long run." ,
"meta" :{
"additional" : "info3"
},
"score" : 0.00081340264
},
{
"id" : 1 ,
"text" : "Introduce *lookahead decoding*: - a parallel decoding algo to accelerate LLM inference - w/o the need for a draft model or a data store - linearly decreases # decoding steps relative to log(FLOPs) used per decoding step." ,
"meta" :{
"additional" : "info1"
},
"score" : 0.00063596206
},
{
"id" : 2 ,
"text" : "LLM inference efficiency will be one of the most crucial topics for both industry and academia, simply because the more efficient you are, the more $$$ you will save. vllm project is a must-read for this direction, and now they have just released the paper" ,
"meta" :{
"additional" : "info2"
},
"score" : 0.00024851
}
]

AWS 또는 기타 서버리스 환경에서 전체 VM이 읽기 전용으로 고유 한 사용자 지정 디어를 만들어야 할 수도 있습니다. Dockerfile에서 그렇게하고 모델을로드하는 데 사용할 수 있습니다 (그리고 결국 따뜻한 통화 사이의 캐시). CACHE_DIR 매개 변수를 사용하여이를 수행 할 수 있습니다.
ranker = Ranker ( model_name = "ms-marco-MiniLM-L-12-v2" , cache_dir = "/opt" )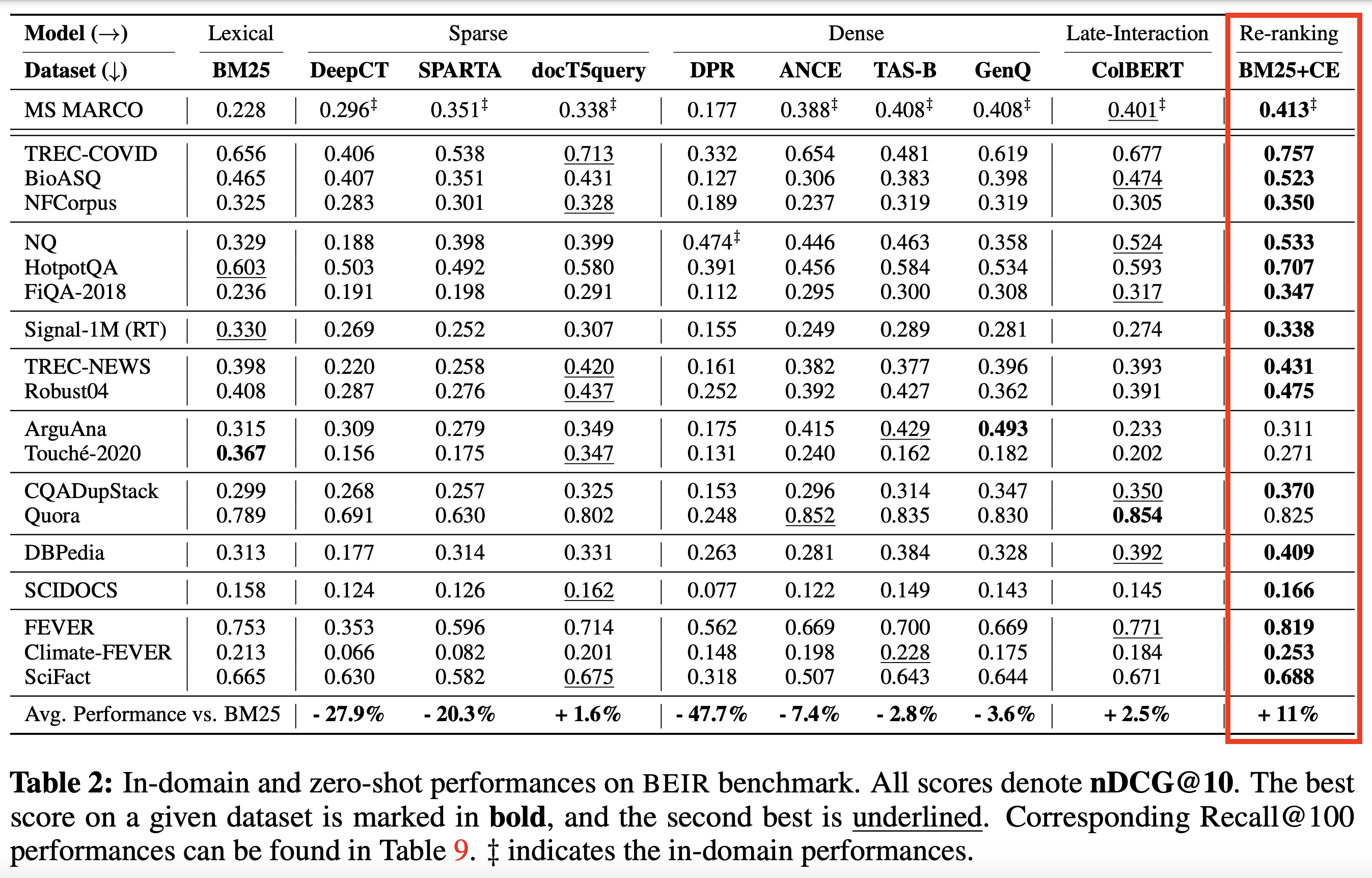
작업 에서이 저장소를 인용하려면 오른쪽에있는 "이 저장소 인용"링크를 클릭하십시오 (Bewlow Repo 설명 및 태그).
COS-MIX : 개선 된 정보 검색을위한 코사인 유사성 및 거리 융합
ClimateActivism의 Bryndza 2024 : 검색 gpt-4 및 llama를 통한 자세, 목표 및 증오 이벤트 탐지
기후 운동과 관련된 트윗에서의 자세와 증오 사건 탐지 - 사례 2024의 공유 과제
Swiftrank라는 클론 라이브러리가 모델 버킷을 가리키고 있습니다. 우리는이 도둑질을 피하기 위해 중간 솔루션을 연구하고 있습니다 . 인내와 이해에 감사드립니다.
이 문제는 해결되며 모델은 현재 HF에 있습니다. 계속 PIP 설치 -U FlashRank로 업그레이드하십시오 . 인내와 이해에 감사드립니다


