FlashRank
Minor fixes

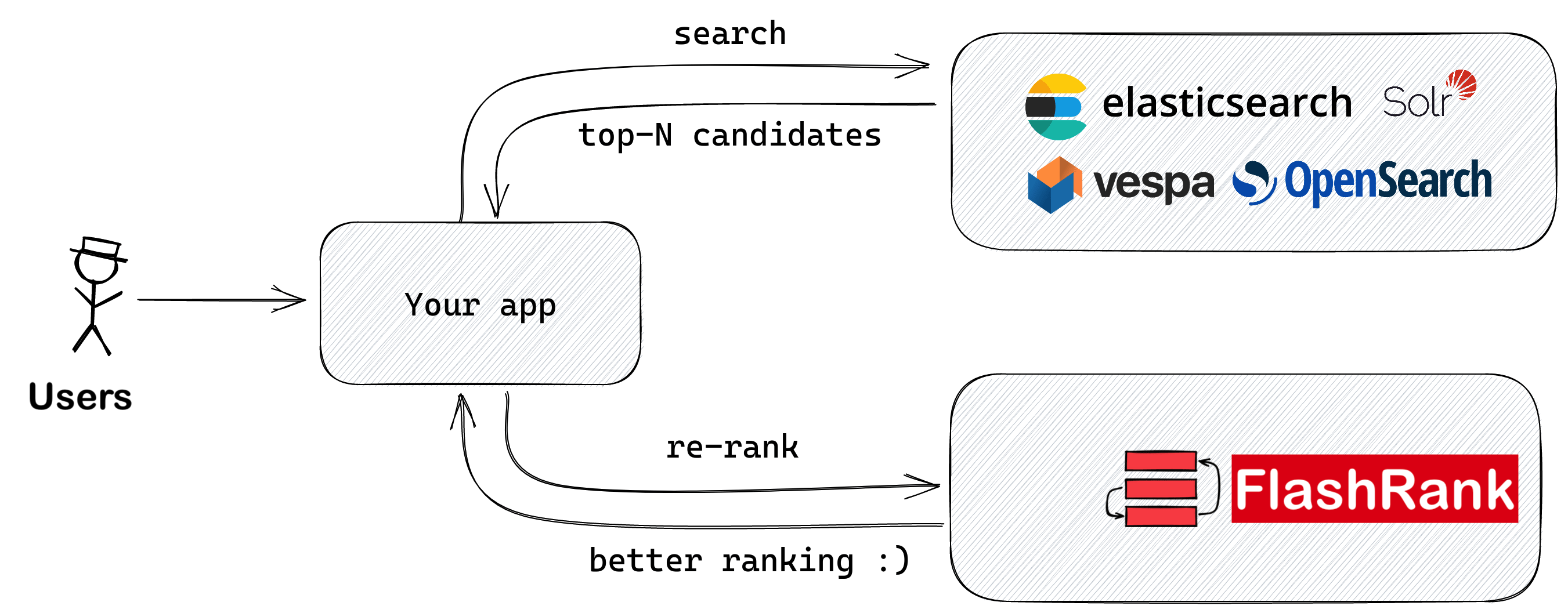
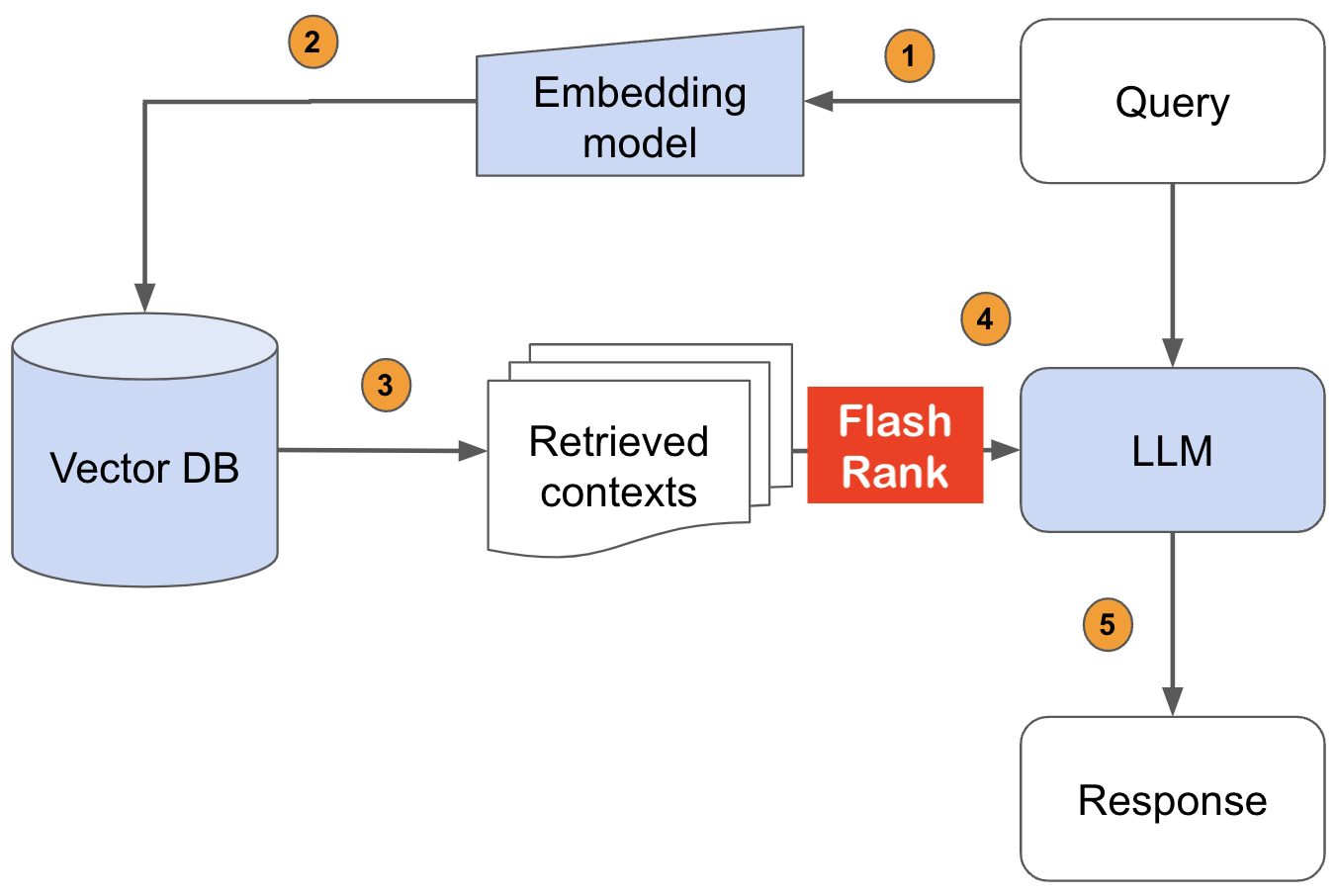
Vuelva a clasificar sus resultados de búsqueda con Sota por pares o en Listwise Rerankers antes de alimentar a sus LLMS
Biblioteca de Python Ultra-Lite & Super-Fast para agregar un reanimiento a sus tuberías de búsqueda y recuperación existentes. Se basa en SOTA LLMS y los codificadores cruzados, con gratitud a todos los propietarios de modelos.
Soporte:
Max tokens = 512 )Max tokens = 8192 )⚡ Ultra-lite :
⏱️ Super rápido :

? $ conciencia :
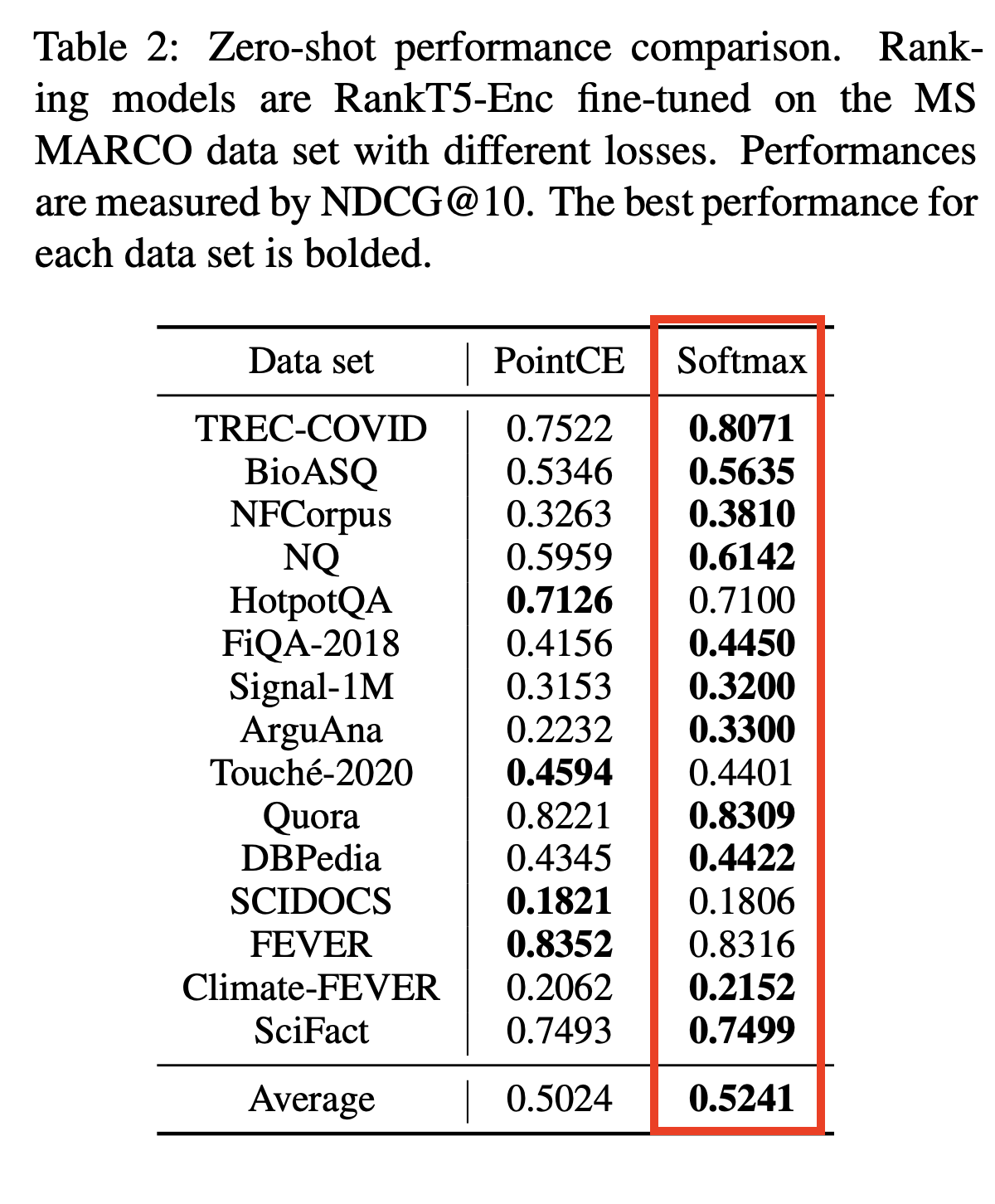
Basado en los codificadores cruzados de SOTA y otros modelos :
| Nombre del modelo | Descripción | Tamaño | Notas |
|---|---|---|---|
ms-marco-TinyBERT-L-2-v2 | Modelo predeterminado | ~ 4MB | Tarjeta modelo |
ms-marco-MiniLM-L-12-v2 | Best Cross-encoder reranker | ~ 34 MB | Tarjeta modelo |
rank-T5-flan | Mejor no cruzado Reranker | ~ 110 MB | Tarjeta modelo |
ms-marco-MultiBERT-L-12 | Multilingüe, admite más de 100 idiomas | ~ 150 MB | Idiomas compatibles |
ce-esci-MiniLM-L12-v2 | Ajustado en el conjunto de datos de Amazon ESCI | - | Tarjeta modelo |
rank_zephyr_7b_v1_full | Gguf de 4 bits | ~ 4GB | Tarjeta modelo |
miniReranker_arabic_v1 | Only dedicated Arabic Reranker | - | Tarjeta modelo |
pip install flashrank pip install flashrank [ listwise ] El valor max_length debe ser grande capaz de acomodar su pasaje más largo. En otras palabras, si su pasaje más largo (100 tokens) + consulta (16 tokens) par de la estimación de tokens es 116, entonces digamos que el ajuste max_length = 128 es lo suficientemente bueno, incluido el espacio para tokens reservados como [CLS] y [SEP]. Use Operai Tiktoken como bibliotecas para estimar la densidad del token, si el rendimiento por token es crítico para usted. Darles no patrocinadamente una max_length más larga como 512 para tamaños de pasaje más pequeños afectará negativamente el tiempo de respuesta.
from flashrank import Ranker , RerankRequest
# Nano (~4MB), blazing fast model & competitive performance (ranking precision).
ranker = Ranker ( max_length = 128 )
or
# Small (~34MB), slightly slower & best performance (ranking precision).
ranker = Ranker ( model_name = "ms-marco-MiniLM-L-12-v2" , cache_dir = "/opt" )
or
# Medium (~110MB), slower model with best zeroshot performance (ranking precision) on out of domain data.
ranker = Ranker ( model_name = "rank-T5-flan" , cache_dir = "/opt" )
or
# Medium (~150MB), slower model with competitive performance (ranking precision) for 100+ languages (don't use for english)
ranker = Ranker ( model_name = "ms-marco-MultiBERT-L-12" , cache_dir = "/opt" )
or
ranker = Ranker ( model_name = "rank_zephyr_7b_v1_full" , max_length = 1024 ) # adjust max_length based on your passage length # Metadata is optional, Id can be your DB ids from your retrieval stage or simple numeric indices.
query = "How to speedup LLMs?"
passages = [
{
"id" : 1 ,
"text" : "Introduce *lookahead decoding*: - a parallel decoding algo to accelerate LLM inference - w/o the need for a draft model or a data store - linearly decreases # decoding steps relative to log(FLOPs) used per decoding step." ,
"meta" : { "additional" : "info1" }
},
{
"id" : 2 ,
"text" : "LLM inference efficiency will be one of the most crucial topics for both industry and academia, simply because the more efficient you are, the more $$$ you will save. vllm project is a must-read for this direction, and now they have just released the paper" ,
"meta" : { "additional" : "info2" }
},
{
"id" : 3 ,
"text" : "There are many ways to increase LLM inference throughput (tokens/second) and decrease memory footprint, sometimes at the same time. Here are a few methods I’ve found effective when working with Llama 2. These methods are all well-integrated with Hugging Face. This list is far from exhaustive; some of these techniques can be used in combination with each other and there are plenty of others to try. - Bettertransformer (Optimum Library): Simply call `model.to_bettertransformer()` on your Hugging Face model for a modest improvement in tokens per second. - Fp4 Mixed-Precision (Bitsandbytes): Requires minimal configuration and dramatically reduces the model's memory footprint. - AutoGPTQ: Time-consuming but leads to a much smaller model and faster inference. The quantization is a one-time cost that pays off in the long run." ,
"meta" : { "additional" : "info3" }
},
{
"id" : 4 ,
"text" : "Ever want to make your LLM inference go brrrrr but got stuck at implementing speculative decoding and finding the suitable draft model? No more pain! Thrilled to unveil Medusa, a simple framework that removes the annoying draft model while getting 2x speedup." ,
"meta" : { "additional" : "info4" }
},
{
"id" : 5 ,
"text" : "vLLM is a fast and easy-to-use library for LLM inference and serving. vLLM is fast with: State-of-the-art serving throughput Efficient management of attention key and value memory with PagedAttention Continuous batching of incoming requests Optimized CUDA kernels" ,
"meta" : { "additional" : "info5" }
}
]
rerankrequest = RerankRequest ( query = query , passages = passages )
results = ranker . rerank ( rerankrequest )
print ( results ) # Reranked output from default reranker
[
{
"id" : 4 ,
"text" : "Ever want to make your LLM inference go brrrrr but got stuck at implementing speculative decoding and finding the suitable draft model? No more pain! Thrilled to unveil Medusa, a simple framework that removes the annoying draft model while getting 2x speedup." ,
"meta" :{
"additional" : "info4"
},
"score" : 0.016847236
},
{
"id" : 5 ,
"text" : "vLLM is a fast and easy-to-use library for LLM inference and serving. vLLM is fast with: State-of-the-art serving throughput Efficient management of attention key and value memory with PagedAttention Continuous batching of incoming requests Optimized CUDA kernels" ,
"meta" :{
"additional" : "info5"
},
"score" : 0.011563735
},
{
"id" : 3 ,
"text" : "There are many ways to increase LLM inference throughput (tokens/second) and decrease memory footprint, sometimes at the same time. Here are a few methods I’ve found effective when working with Llama 2. These methods are all well-integrated with Hugging Face. This list is far from exhaustive; some of these techniques can be used in combination with each other and there are plenty of others to try. - Bettertransformer (Optimum Library): Simply call `model.to_bettertransformer()` on your Hugging Face model for a modest improvement in tokens per second. - Fp4 Mixed-Precision (Bitsandbytes): Requires minimal configuration and dramatically reduces the model's memory footprint. - AutoGPTQ: Time-consuming but leads to a much smaller model and faster inference. The quantization is a one-time cost that pays off in the long run." ,
"meta" :{
"additional" : "info3"
},
"score" : 0.00081340264
},
{
"id" : 1 ,
"text" : "Introduce *lookahead decoding*: - a parallel decoding algo to accelerate LLM inference - w/o the need for a draft model or a data store - linearly decreases # decoding steps relative to log(FLOPs) used per decoding step." ,
"meta" :{
"additional" : "info1"
},
"score" : 0.00063596206
},
{
"id" : 2 ,
"text" : "LLM inference efficiency will be one of the most crucial topics for both industry and academia, simply because the more efficient you are, the more $$$ you will save. vllm project is a must-read for this direction, and now they have just released the paper" ,
"meta" :{
"additional" : "info2"
},
"score" : 0.00024851
}
]

En AWS u otros entornos sin servidor, todo VM es de solo lectura, es posible que deba crear su propio DIR personalizado. Puede hacerlo en su Dockerfile y usarlo para cargar los modelos (y eventualmente como un caché entre llamadas cálidas). Puede hacerlo durante el init con el parámetro CACHE_DIR.
ranker = Ranker ( model_name = "ms-marco-MiniLM-L-12-v2" , cache_dir = "/opt" )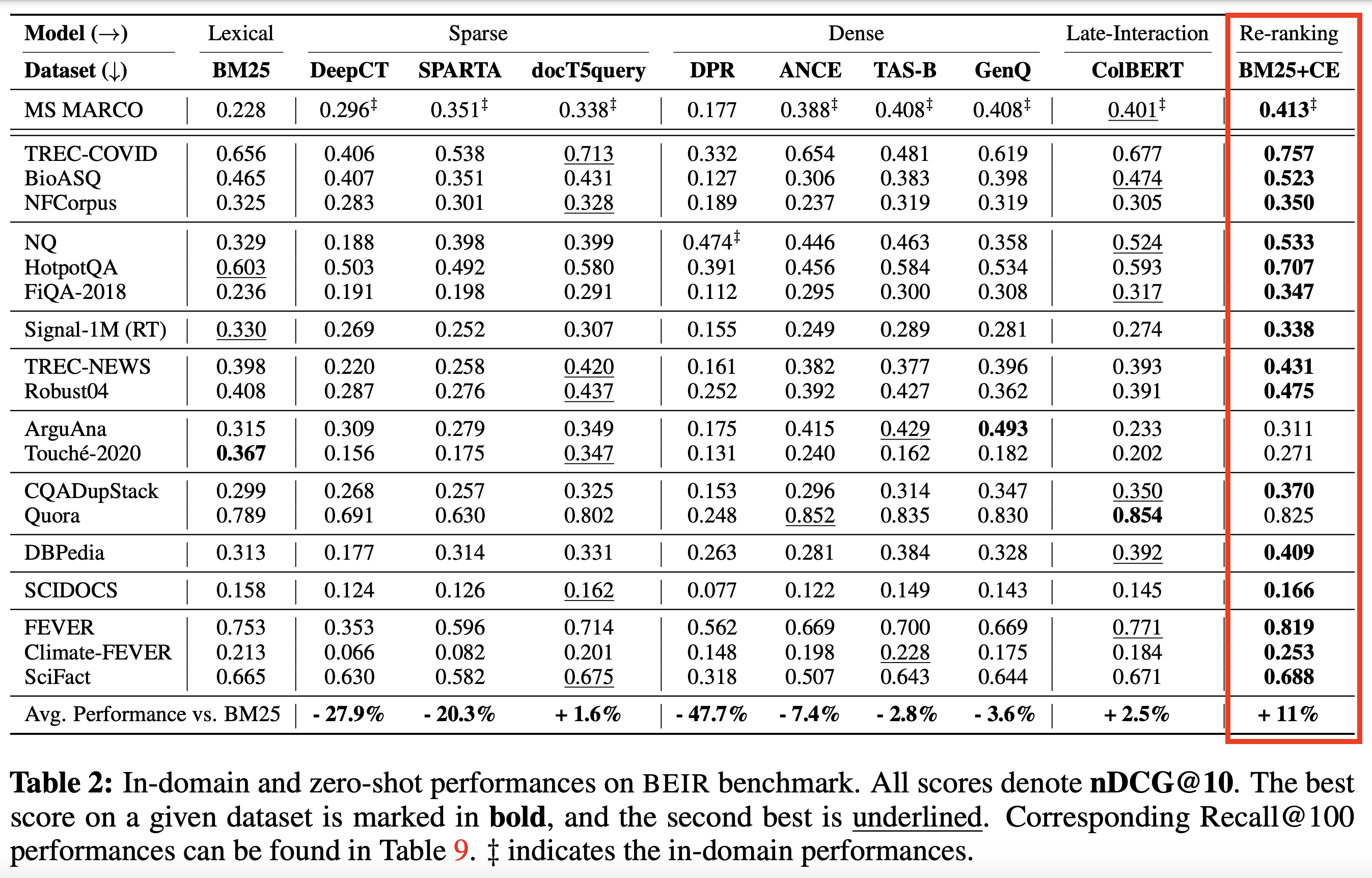
Para citar este repositorio en su trabajo, haga clic en el enlace "Cite este repositorio" en el lado derecho (descripciones y etiquetas de repositorio de Bewlow)
COS-MIX: Similitud de coseno y fusión de distancia para una mejor recuperación de información
Bryndza en ClimateActivism 2024: Detección de eventos de postura, objetivo y odio a través de GPT-4 y LLAMA augsados por recuperación
Detección de eventos de postura y odio en tweets relacionados con el activismo climático: tarea compartida en el caso 2024
Una biblioteca de clon llamada Swiftrank está apuntando a nuestros cubos modelo, estamos trabajando en una solución provisional para evitar este robo . Gracias por la paciencia y la comprensión.
Este problema se resuelve, los modelos están en HF ahora. Actualice para continuar PIP Install -U FlashRank. Gracias por la paciencia y la comprensión


