FlashRank
Minor fixes

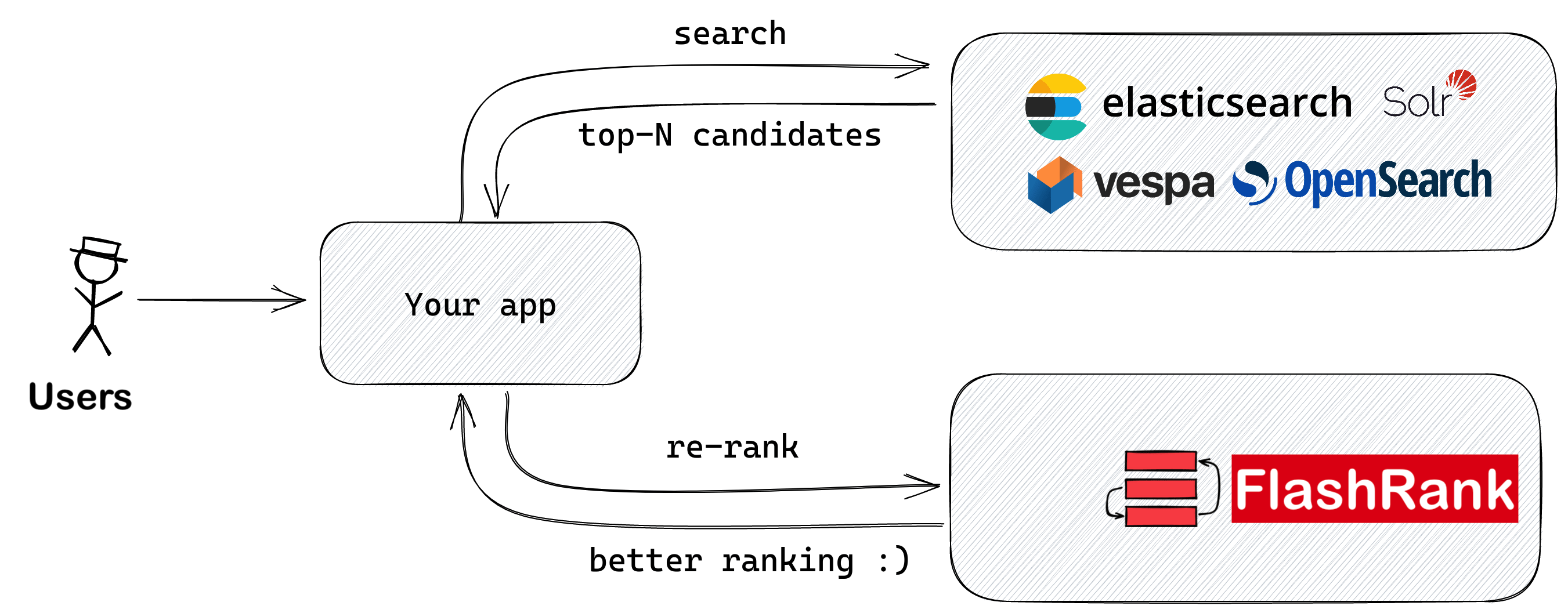
Robre seus resultados de pesquisa com SOTA em pares ou listwise Rerrankers antes de se alimentar para o seu LLMS
Biblioteca Ultra-Lite e Super-Fast Python para adicionar novamente os pipelines de pesquisa e recuperação existentes. É baseado em Sota LLMS e codificadores cruzados, com gratidão a todos os proprietários de modelos.
Suportes:
Max tokens = 512 )Max tokens = 8192 )⚡ Ultra-Lite :
⏱️ Super-Fast :

? $ Concioso :
Baseado em codificadores SOTA e outros modelos :
| Nome do modelo | Descrição | Tamanho | Notas |
|---|---|---|---|
ms-marco-TinyBERT-L-2-v2 | Modelo padrão | ~ 4MB | Cartão modelo |
ms-marco-MiniLM-L-12-v2 | Best Cross-encoder reranker | ~ 34MB | Cartão modelo |
rank-T5-flan | Melhor Reranker não codificado | ~ 110 MB | Cartão modelo |
ms-marco-MultiBERT-L-12 | Multi-Linguual, suporta mais de 100 idiomas | ~ 150 MB | Idiomas suportados |
ce-esci-MiniLM-L12-v2 | Tuneado no conjunto de dados da Amazon Esci | - | Cartão modelo |
rank_zephyr_7b_v1_full | GGUF de 4 bits | ~ 4 GB | Cartão modelo |
miniReranker_arabic_v1 | Only dedicated Arabic Reranker | - | Cartão modelo |
pip install flashrank pip install flashrank [ listwise ] O valor max_length deve ser grande capaz de acomodar sua passagem mais longa. Em outras palavras, se a sua passagem mais longa (100 tokens) + consulta (16 tokens) por estimativa de token for 116, digamos, configurar max_length = 128 é bom o suficiente, incluindo espaço para tokens reservados como [CLS] e [setembro]. Use bibliotecas do Openai Tiktoken para estimar a densidade do token, se o desempenho por token for fundamental para você. Dar um pouco mais de um max_length mais longo como 512 para tamanhos de passagem menores afetará negativamente o tempo de resposta.
from flashrank import Ranker , RerankRequest
# Nano (~4MB), blazing fast model & competitive performance (ranking precision).
ranker = Ranker ( max_length = 128 )
or
# Small (~34MB), slightly slower & best performance (ranking precision).
ranker = Ranker ( model_name = "ms-marco-MiniLM-L-12-v2" , cache_dir = "/opt" )
or
# Medium (~110MB), slower model with best zeroshot performance (ranking precision) on out of domain data.
ranker = Ranker ( model_name = "rank-T5-flan" , cache_dir = "/opt" )
or
# Medium (~150MB), slower model with competitive performance (ranking precision) for 100+ languages (don't use for english)
ranker = Ranker ( model_name = "ms-marco-MultiBERT-L-12" , cache_dir = "/opt" )
or
ranker = Ranker ( model_name = "rank_zephyr_7b_v1_full" , max_length = 1024 ) # adjust max_length based on your passage length # Metadata is optional, Id can be your DB ids from your retrieval stage or simple numeric indices.
query = "How to speedup LLMs?"
passages = [
{
"id" : 1 ,
"text" : "Introduce *lookahead decoding*: - a parallel decoding algo to accelerate LLM inference - w/o the need for a draft model or a data store - linearly decreases # decoding steps relative to log(FLOPs) used per decoding step." ,
"meta" : { "additional" : "info1" }
},
{
"id" : 2 ,
"text" : "LLM inference efficiency will be one of the most crucial topics for both industry and academia, simply because the more efficient you are, the more $$$ you will save. vllm project is a must-read for this direction, and now they have just released the paper" ,
"meta" : { "additional" : "info2" }
},
{
"id" : 3 ,
"text" : "There are many ways to increase LLM inference throughput (tokens/second) and decrease memory footprint, sometimes at the same time. Here are a few methods I’ve found effective when working with Llama 2. These methods are all well-integrated with Hugging Face. This list is far from exhaustive; some of these techniques can be used in combination with each other and there are plenty of others to try. - Bettertransformer (Optimum Library): Simply call `model.to_bettertransformer()` on your Hugging Face model for a modest improvement in tokens per second. - Fp4 Mixed-Precision (Bitsandbytes): Requires minimal configuration and dramatically reduces the model's memory footprint. - AutoGPTQ: Time-consuming but leads to a much smaller model and faster inference. The quantization is a one-time cost that pays off in the long run." ,
"meta" : { "additional" : "info3" }
},
{
"id" : 4 ,
"text" : "Ever want to make your LLM inference go brrrrr but got stuck at implementing speculative decoding and finding the suitable draft model? No more pain! Thrilled to unveil Medusa, a simple framework that removes the annoying draft model while getting 2x speedup." ,
"meta" : { "additional" : "info4" }
},
{
"id" : 5 ,
"text" : "vLLM is a fast and easy-to-use library for LLM inference and serving. vLLM is fast with: State-of-the-art serving throughput Efficient management of attention key and value memory with PagedAttention Continuous batching of incoming requests Optimized CUDA kernels" ,
"meta" : { "additional" : "info5" }
}
]
rerankrequest = RerankRequest ( query = query , passages = passages )
results = ranker . rerank ( rerankrequest )
print ( results ) # Reranked output from default reranker
[
{
"id" : 4 ,
"text" : "Ever want to make your LLM inference go brrrrr but got stuck at implementing speculative decoding and finding the suitable draft model? No more pain! Thrilled to unveil Medusa, a simple framework that removes the annoying draft model while getting 2x speedup." ,
"meta" :{
"additional" : "info4"
},
"score" : 0.016847236
},
{
"id" : 5 ,
"text" : "vLLM is a fast and easy-to-use library for LLM inference and serving. vLLM is fast with: State-of-the-art serving throughput Efficient management of attention key and value memory with PagedAttention Continuous batching of incoming requests Optimized CUDA kernels" ,
"meta" :{
"additional" : "info5"
},
"score" : 0.011563735
},
{
"id" : 3 ,
"text" : "There are many ways to increase LLM inference throughput (tokens/second) and decrease memory footprint, sometimes at the same time. Here are a few methods I’ve found effective when working with Llama 2. These methods are all well-integrated with Hugging Face. This list is far from exhaustive; some of these techniques can be used in combination with each other and there are plenty of others to try. - Bettertransformer (Optimum Library): Simply call `model.to_bettertransformer()` on your Hugging Face model for a modest improvement in tokens per second. - Fp4 Mixed-Precision (Bitsandbytes): Requires minimal configuration and dramatically reduces the model's memory footprint. - AutoGPTQ: Time-consuming but leads to a much smaller model and faster inference. The quantization is a one-time cost that pays off in the long run." ,
"meta" :{
"additional" : "info3"
},
"score" : 0.00081340264
},
{
"id" : 1 ,
"text" : "Introduce *lookahead decoding*: - a parallel decoding algo to accelerate LLM inference - w/o the need for a draft model or a data store - linearly decreases # decoding steps relative to log(FLOPs) used per decoding step." ,
"meta" :{
"additional" : "info1"
},
"score" : 0.00063596206
},
{
"id" : 2 ,
"text" : "LLM inference efficiency will be one of the most crucial topics for both industry and academia, simply because the more efficient you are, the more $$$ you will save. vllm project is a must-read for this direction, and now they have just released the paper" ,
"meta" :{
"additional" : "info2"
},
"score" : 0.00024851
}
]
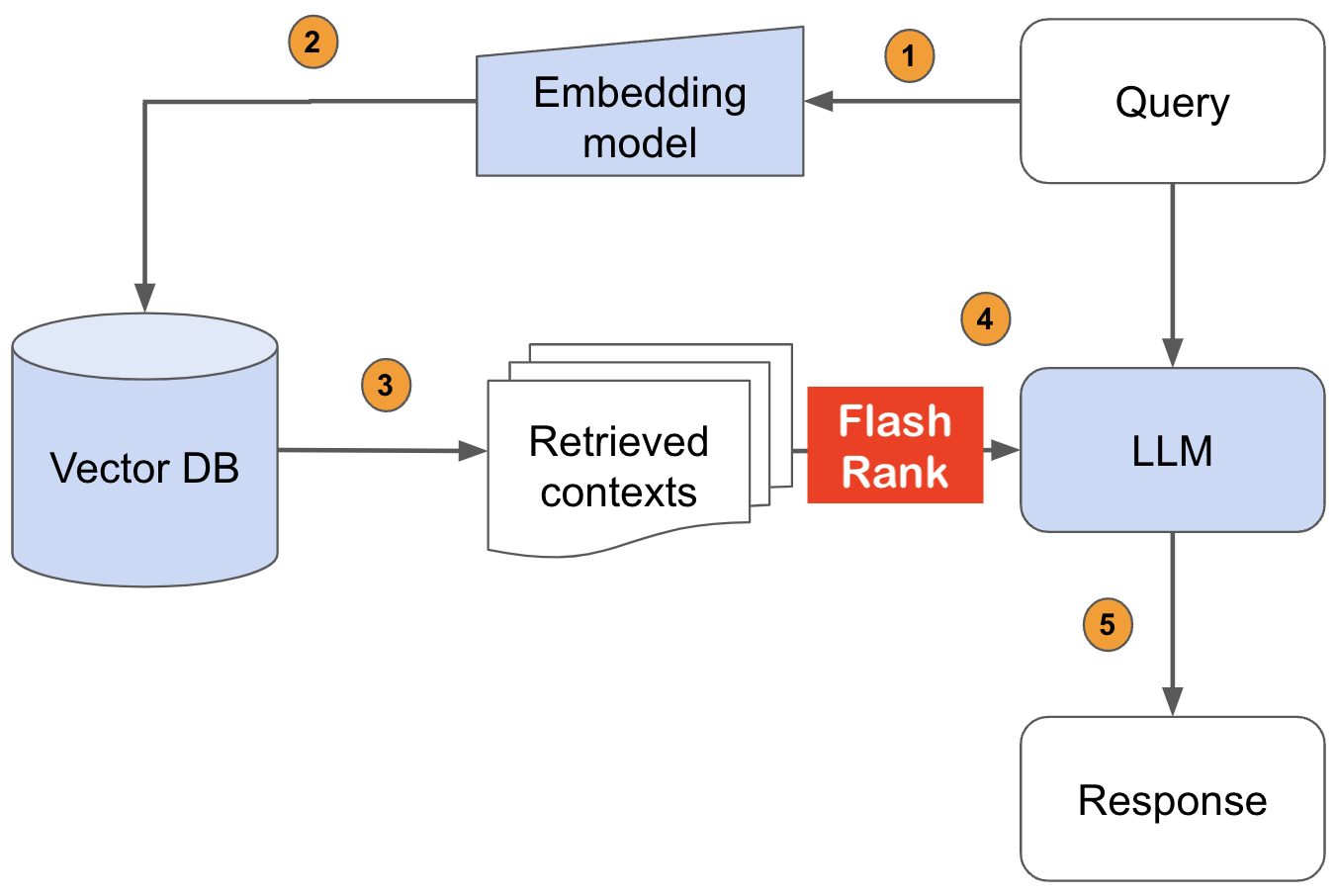

Em AWS ou outros ambientes sem servidor, toda a VM é somente leitura, você pode ter que criar seu próprio diretor personalizado. Você pode fazê -lo no seu Dockerfile e usá -lo para carregar os modelos (e eventualmente como um cache entre chamadas quentes). Você pode fazer isso durante o INIT com o parâmetro Cache_DIR.
ranker = Ranker ( model_name = "ms-marco-MiniLM-L-12-v2" , cache_dir = "/opt" )
Para citar este repositório em seu trabalho, clique no link "Cite este repositório" no lado direito (descrições e tags de repo de Bewlow)
Cos-Mix: similaridade de cosseno e fusão de distância para melhorar a recuperação de informações
BRYNDZA AT CLELETACTIVISMISMO 2024: Stance, Alvo e Detecção de Eventos de Hate via GPT-4 e Llama de recuperação GPT-4 e LLAMA
Detecção de eventos de postura e ódio em tweets relacionados ao ativismo climático - tarefa compartilhada no caso 2024
Uma biblioteca de clones chamada Swiftrank está apontando para nossos baldes modelo, estamos trabalhando em uma solução provisória para evitar esse roubo . Obrigado por paciência e compreensão.
Este problema é resolvido, os modelos estão em HF agora. Atualize para continuar o PIP Install -u FlashRank. Obrigado pela paciência e compreensão


