FlashRank
Minor fixes

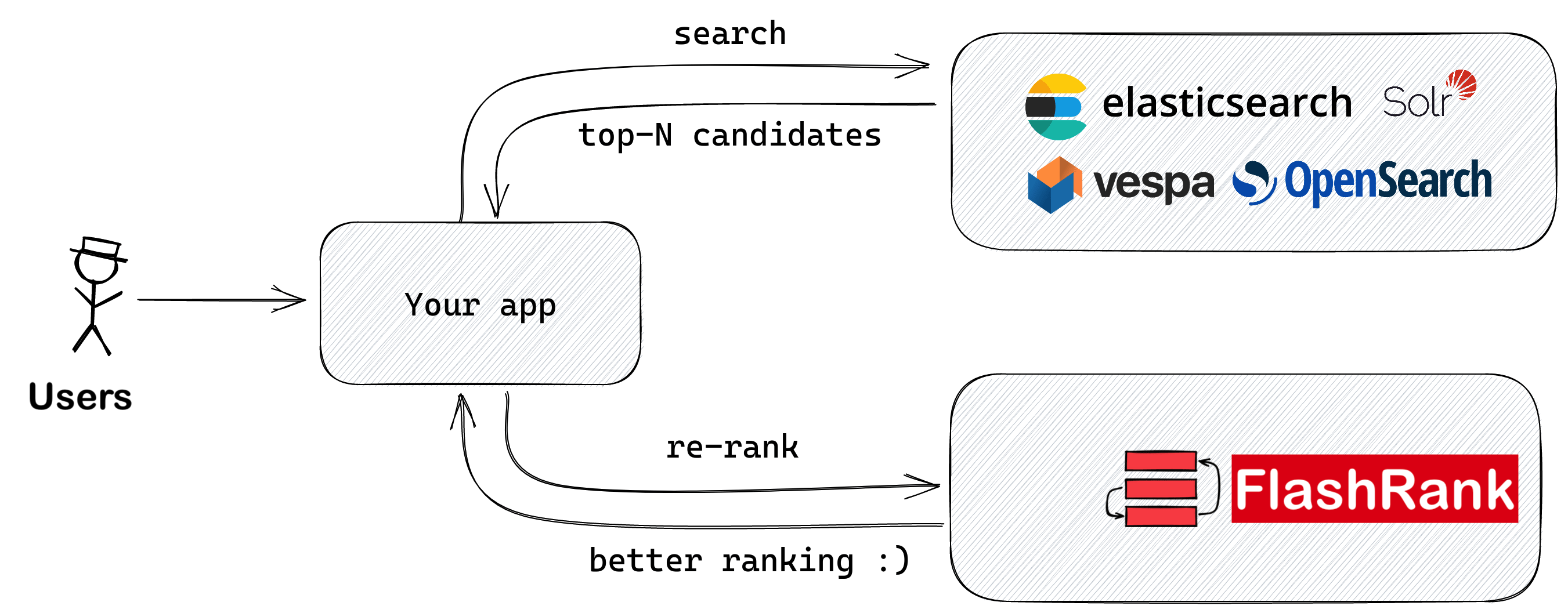
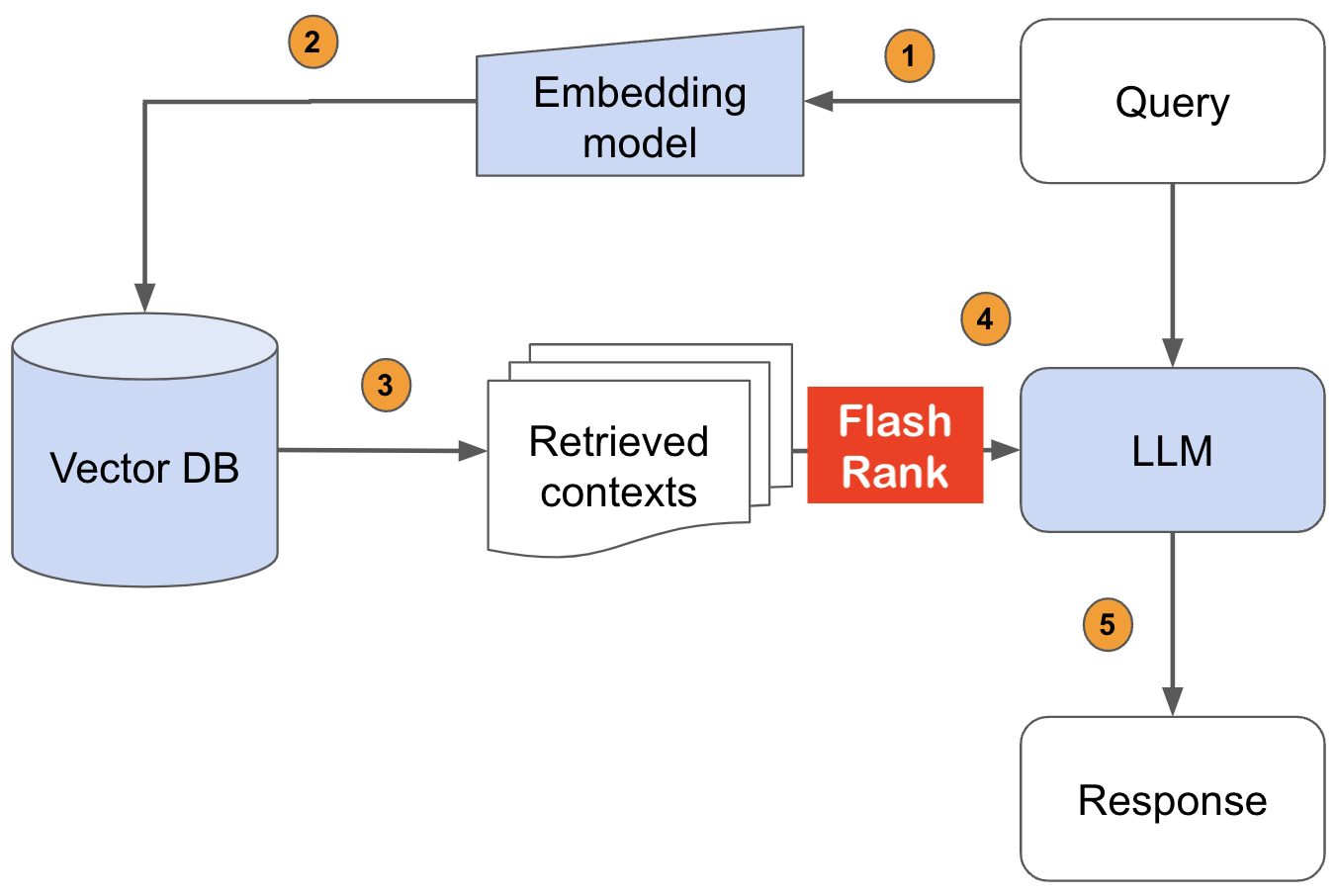
จัดอันดับผลการค้นหาของคุณอีกครั้งด้วย sota pairwise หรือ rearankers listwise ก่อนที่จะป้อนเข้าสู่ LLM ของคุณ
ไลบรารี Python Ultra-Lite & Super-Fast เพื่อเพิ่มการจัดอันดับใหม่ให้กับการค้นหาและการดึงข้อมูลที่มีอยู่ของคุณ มันขึ้นอยู่กับ SOTA LLMS และ cross-encoders โดยมีความกตัญญูต่อเจ้าของโมเดลทุกคน
สนับสนุน:
Max tokens = 512 )Max tokens = 8192 )⚡ Ultra-Lite :
⏱ เร็วมาก :

- $ concious :
ขึ้นอยู่กับการเข้ารหัสข้าม SOTA และรุ่นอื่น ๆ :
| ชื่อนางแบบ | คำอธิบาย | ขนาด | หมายเหตุ |
|---|---|---|---|
ms-marco-TinyBERT-L-2-v2 | รุ่นเริ่มต้น | ~ 4MB | การ์ดรุ่น |
ms-marco-MiniLM-L-12-v2 | Best Cross-encoder reranker | ~ 34MB | การ์ดรุ่น |
rank-T5-flan | Reranker ที่ไม่ได้เข้ารหัสที่ดีที่สุด | ~ 110MB | การ์ดรุ่น |
ms-marco-MultiBERT-L-12 | หลายภาษารองรับ 100 ภาษา | ~ 150MB | ภาษาที่รองรับ |
ce-esci-MiniLM-L12-v2 | ปรับแต่งในชุดข้อมูล Amazon Esci | - | การ์ดรุ่น |
rank_zephyr_7b_v1_full | GGUF แบบ 4 บิต | ~ 4GB | การ์ดรุ่น |
miniReranker_arabic_v1 | Only dedicated Arabic Reranker | - | การ์ดรุ่น |
pip install flashrank pip install flashrank [ listwise ] ค่า max_length ควรมีขนาดใหญ่สามารถรองรับทางเดินที่ยาวที่สุดของคุณได้ กล่าวอีกนัยหนึ่งถ้าข้อความที่ยาวที่สุดของคุณ (100 โทเค็น) + เคียวรี (16 โทเค็น) คู่โดยประมาณการโทเค็นคือ 116 จากนั้นบอกว่าการตั้งค่า max_length = 128 เป็นห้องที่ดีพอสำหรับโทเค็นที่สงวนไว้เช่น [CLS] และ [SEP] ใช้ openai tiktoken เช่นห้องสมุดเพื่อประเมินความหนาแน่นของโทเค็นหากประสิทธิภาพต่อโทเค็นเป็นสิ่งสำคัญสำหรับคุณ การไม่ให้ max_length ที่ยาวขึ้นเช่น 512 สำหรับขนาดที่เล็กกว่าจะส่งผลเสียต่อเวลาตอบสนอง
from flashrank import Ranker , RerankRequest
# Nano (~4MB), blazing fast model & competitive performance (ranking precision).
ranker = Ranker ( max_length = 128 )
or
# Small (~34MB), slightly slower & best performance (ranking precision).
ranker = Ranker ( model_name = "ms-marco-MiniLM-L-12-v2" , cache_dir = "/opt" )
or
# Medium (~110MB), slower model with best zeroshot performance (ranking precision) on out of domain data.
ranker = Ranker ( model_name = "rank-T5-flan" , cache_dir = "/opt" )
or
# Medium (~150MB), slower model with competitive performance (ranking precision) for 100+ languages (don't use for english)
ranker = Ranker ( model_name = "ms-marco-MultiBERT-L-12" , cache_dir = "/opt" )
or
ranker = Ranker ( model_name = "rank_zephyr_7b_v1_full" , max_length = 1024 ) # adjust max_length based on your passage length # Metadata is optional, Id can be your DB ids from your retrieval stage or simple numeric indices.
query = "How to speedup LLMs?"
passages = [
{
"id" : 1 ,
"text" : "Introduce *lookahead decoding*: - a parallel decoding algo to accelerate LLM inference - w/o the need for a draft model or a data store - linearly decreases # decoding steps relative to log(FLOPs) used per decoding step." ,
"meta" : { "additional" : "info1" }
},
{
"id" : 2 ,
"text" : "LLM inference efficiency will be one of the most crucial topics for both industry and academia, simply because the more efficient you are, the more $$$ you will save. vllm project is a must-read for this direction, and now they have just released the paper" ,
"meta" : { "additional" : "info2" }
},
{
"id" : 3 ,
"text" : "There are many ways to increase LLM inference throughput (tokens/second) and decrease memory footprint, sometimes at the same time. Here are a few methods I’ve found effective when working with Llama 2. These methods are all well-integrated with Hugging Face. This list is far from exhaustive; some of these techniques can be used in combination with each other and there are plenty of others to try. - Bettertransformer (Optimum Library): Simply call `model.to_bettertransformer()` on your Hugging Face model for a modest improvement in tokens per second. - Fp4 Mixed-Precision (Bitsandbytes): Requires minimal configuration and dramatically reduces the model's memory footprint. - AutoGPTQ: Time-consuming but leads to a much smaller model and faster inference. The quantization is a one-time cost that pays off in the long run." ,
"meta" : { "additional" : "info3" }
},
{
"id" : 4 ,
"text" : "Ever want to make your LLM inference go brrrrr but got stuck at implementing speculative decoding and finding the suitable draft model? No more pain! Thrilled to unveil Medusa, a simple framework that removes the annoying draft model while getting 2x speedup." ,
"meta" : { "additional" : "info4" }
},
{
"id" : 5 ,
"text" : "vLLM is a fast and easy-to-use library for LLM inference and serving. vLLM is fast with: State-of-the-art serving throughput Efficient management of attention key and value memory with PagedAttention Continuous batching of incoming requests Optimized CUDA kernels" ,
"meta" : { "additional" : "info5" }
}
]
rerankrequest = RerankRequest ( query = query , passages = passages )
results = ranker . rerank ( rerankrequest )
print ( results ) # Reranked output from default reranker
[
{
"id" : 4 ,
"text" : "Ever want to make your LLM inference go brrrrr but got stuck at implementing speculative decoding and finding the suitable draft model? No more pain! Thrilled to unveil Medusa, a simple framework that removes the annoying draft model while getting 2x speedup." ,
"meta" :{
"additional" : "info4"
},
"score" : 0.016847236
},
{
"id" : 5 ,
"text" : "vLLM is a fast and easy-to-use library for LLM inference and serving. vLLM is fast with: State-of-the-art serving throughput Efficient management of attention key and value memory with PagedAttention Continuous batching of incoming requests Optimized CUDA kernels" ,
"meta" :{
"additional" : "info5"
},
"score" : 0.011563735
},
{
"id" : 3 ,
"text" : "There are many ways to increase LLM inference throughput (tokens/second) and decrease memory footprint, sometimes at the same time. Here are a few methods I’ve found effective when working with Llama 2. These methods are all well-integrated with Hugging Face. This list is far from exhaustive; some of these techniques can be used in combination with each other and there are plenty of others to try. - Bettertransformer (Optimum Library): Simply call `model.to_bettertransformer()` on your Hugging Face model for a modest improvement in tokens per second. - Fp4 Mixed-Precision (Bitsandbytes): Requires minimal configuration and dramatically reduces the model's memory footprint. - AutoGPTQ: Time-consuming but leads to a much smaller model and faster inference. The quantization is a one-time cost that pays off in the long run." ,
"meta" :{
"additional" : "info3"
},
"score" : 0.00081340264
},
{
"id" : 1 ,
"text" : "Introduce *lookahead decoding*: - a parallel decoding algo to accelerate LLM inference - w/o the need for a draft model or a data store - linearly decreases # decoding steps relative to log(FLOPs) used per decoding step." ,
"meta" :{
"additional" : "info1"
},
"score" : 0.00063596206
},
{
"id" : 2 ,
"text" : "LLM inference efficiency will be one of the most crucial topics for both industry and academia, simply because the more efficient you are, the more $$$ you will save. vllm project is a must-read for this direction, and now they have just released the paper" ,
"meta" :{
"additional" : "info2"
},
"score" : 0.00024851
}
]

ใน AWS หรือสภาพแวดล้อมที่ไม่มีเซิร์ฟเวอร์อื่น ๆ VM ทั้งหมดเป็นแบบอ่านอย่างเดียวคุณอาจต้องสร้าง DIR ที่กำหนดเองของคุณเอง คุณสามารถทำได้ใน DockerFile ของคุณและใช้สำหรับการโหลดโมเดล (และในที่สุดก็เป็นแคชระหว่างการโทรที่อบอุ่น) คุณสามารถทำได้ในระหว่างการเริ่มต้นด้วยพารามิเตอร์ CACHE_DIR
ranker = Ranker ( model_name = "ms-marco-MiniLM-L-12-v2" , cache_dir = "/opt" )
หากต้องการอ้างถึงที่เก็บข้อมูลนี้ในงานของคุณโปรดคลิกลิงก์ "อ้างอิงที่เก็บนี้" ทางด้านขวา (คำอธิบายและแท็ก repo ของ Bewlow)
cos-mix: ความคล้ายคลึงกันของโคไซน์และระยะทางฟิวชั่นสำหรับการปรับปรุงข้อมูลที่ได้รับการปรับปรุง
Bryndza ที่ ClimateActivism 2024: ท่าทางการตรวจจับเหตุการณ์และความเกลียดชังผ่านการค้นพบ GPT-4 และ Llama
การตรวจจับเหตุการณ์ท่าทางและความเกลียดชังในทวีตที่เกี่ยวข้องกับการเคลื่อนไหวของสภาพภูมิอากาศ - งานที่ใช้ร่วมกันในกรณีปี 2024
ห้องสมุดโคลนที่เรียกว่า Swiftrank กำลังชี้ไปที่ถังโมเดลของเราเรากำลังทำงานกับโซลูชันชั่วคราวเพื่อหลีกเลี่ยงการขโมยนี้ ขอบคุณสำหรับความอดทนและความเข้าใจ
ปัญหานี้ได้รับการแก้ไขโมเดลอยู่ใน HF ในขณะนี้ กรุณาอัพเกรดเพื่อดำเนินการ ติดตั้ง PIP ต่อ -U Flashrank ขอบคุณสำหรับความอดทนและความเข้าใจ


