FlashRank
Minor fixes

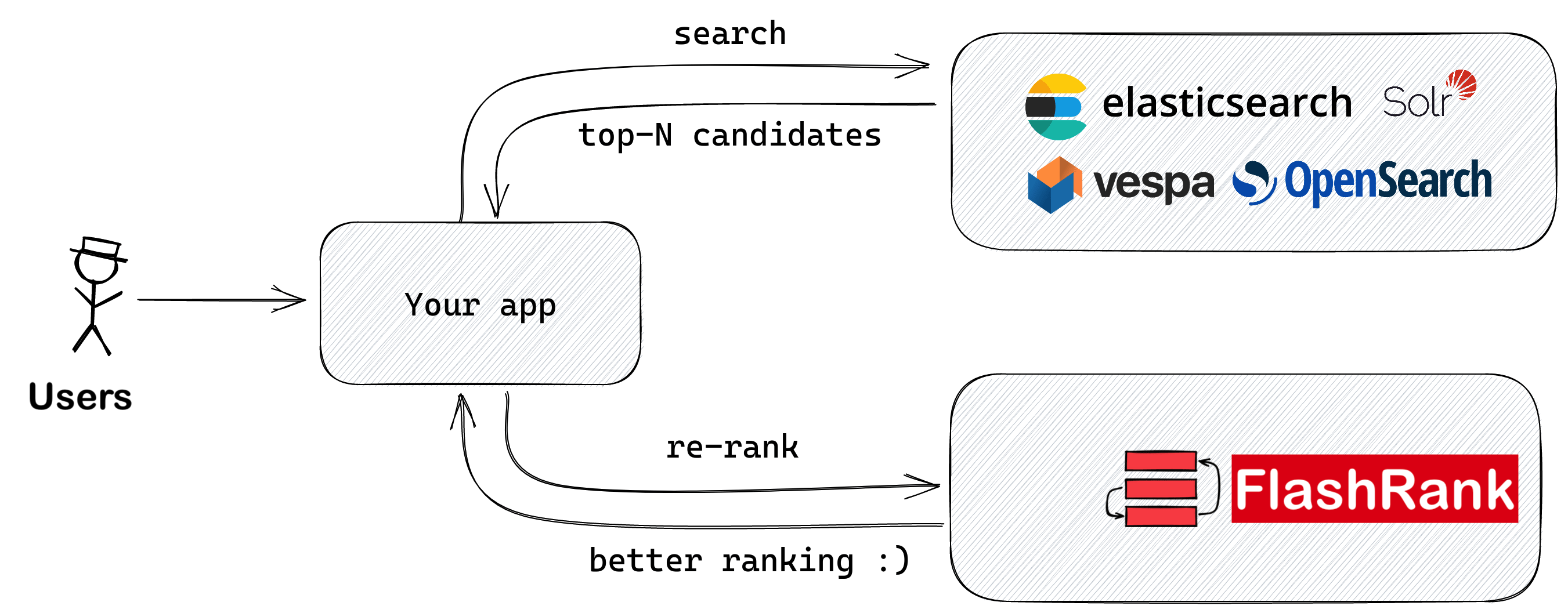
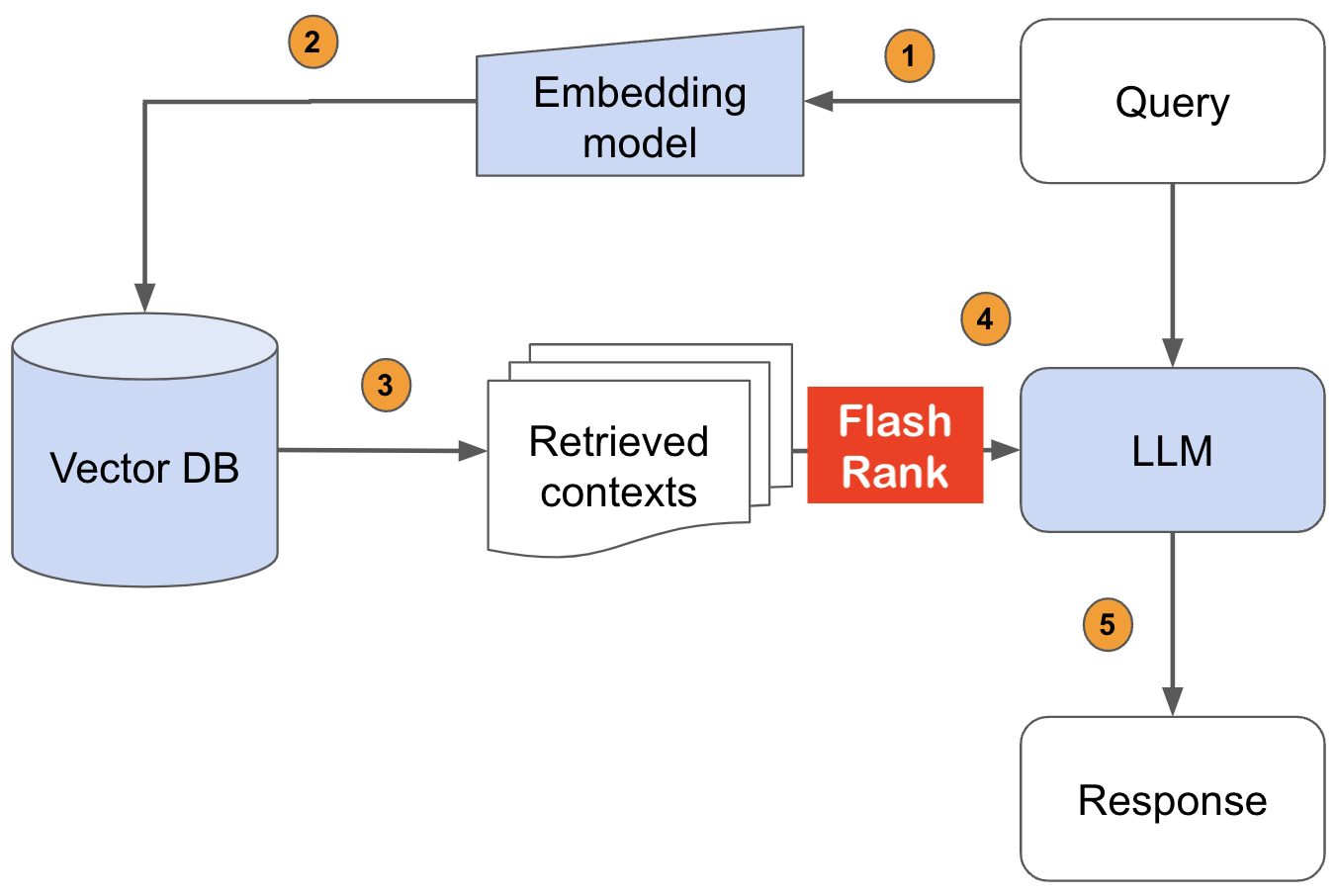
Re-classez vos résultats de recherche avec Sota Pairwise ou Rerrankers Avant de vous nourrir de votre LLMS
Bibliothèque Python ultra-lite et super-rapide pour ajouter de la relance à vos pipelines de recherche et de récupération existants. Il est basé sur SOTA LLMS et Cross-Encoders, avec gratitude à tous les propriétaires de modèles.
Supports:
Max tokens = 512 )Max tokens = 8192 )⚡ Ultra-lite :
⏱️ Super-rapide :

? $ concieux :
Basé sur des encodeurs SOTA et d'autres modèles :
| Nom du modèle | Description | Taille | Notes |
|---|---|---|---|
ms-marco-TinyBERT-L-2-v2 | Modèle par défaut | ~ 4 Mo | Carte modèle |
ms-marco-MiniLM-L-12-v2 | Best Cross-encoder reranker | ~ 34 Mo | Carte modèle |
rank-T5-flan | Meilleur re-recordant non transversal | ~ 110 Mo | Carte modèle |
ms-marco-MultiBERT-L-12 | Multi-lingual, prend en charge plus de 100 langues | ~ 150 Mo | Langues prises en charge |
ce-esci-MiniLM-L12-v2 | Toned sur le jeu de données Amazon ESCI | - | Carte modèle |
rank_zephyr_7b_v1_full | GGUF qualifié 4 bits | ~ 4 Go | Carte modèle |
miniReranker_arabic_v1 | Only dedicated Arabic Reranker | - | Carte modèle |
pip install flashrank pip install flashrank [ listwise ] La valeur max_length devrait être grande en mesure d'accueillir votre plus long passage. En d'autres termes, si votre paire le plus long passage (100 jetons) + requête (16 jetons) par estimation des jetons est 116, alors disons que le réglage max_length = 128 est assez bon, y compris la place pour les jetons réservés comme [CLS] et [Sep]. Utilisez Openai tiktoken comme des bibliothèques pour estimer la densité de jetons, si les performances par jeton sont essentielles pour vous. Donnant nonchalamment un max_length plus long comme 512 pour les tailles de passage plus petites affectera négativement le temps de réponse.
from flashrank import Ranker , RerankRequest
# Nano (~4MB), blazing fast model & competitive performance (ranking precision).
ranker = Ranker ( max_length = 128 )
or
# Small (~34MB), slightly slower & best performance (ranking precision).
ranker = Ranker ( model_name = "ms-marco-MiniLM-L-12-v2" , cache_dir = "/opt" )
or
# Medium (~110MB), slower model with best zeroshot performance (ranking precision) on out of domain data.
ranker = Ranker ( model_name = "rank-T5-flan" , cache_dir = "/opt" )
or
# Medium (~150MB), slower model with competitive performance (ranking precision) for 100+ languages (don't use for english)
ranker = Ranker ( model_name = "ms-marco-MultiBERT-L-12" , cache_dir = "/opt" )
or
ranker = Ranker ( model_name = "rank_zephyr_7b_v1_full" , max_length = 1024 ) # adjust max_length based on your passage length # Metadata is optional, Id can be your DB ids from your retrieval stage or simple numeric indices.
query = "How to speedup LLMs?"
passages = [
{
"id" : 1 ,
"text" : "Introduce *lookahead decoding*: - a parallel decoding algo to accelerate LLM inference - w/o the need for a draft model or a data store - linearly decreases # decoding steps relative to log(FLOPs) used per decoding step." ,
"meta" : { "additional" : "info1" }
},
{
"id" : 2 ,
"text" : "LLM inference efficiency will be one of the most crucial topics for both industry and academia, simply because the more efficient you are, the more $$$ you will save. vllm project is a must-read for this direction, and now they have just released the paper" ,
"meta" : { "additional" : "info2" }
},
{
"id" : 3 ,
"text" : "There are many ways to increase LLM inference throughput (tokens/second) and decrease memory footprint, sometimes at the same time. Here are a few methods I’ve found effective when working with Llama 2. These methods are all well-integrated with Hugging Face. This list is far from exhaustive; some of these techniques can be used in combination with each other and there are plenty of others to try. - Bettertransformer (Optimum Library): Simply call `model.to_bettertransformer()` on your Hugging Face model for a modest improvement in tokens per second. - Fp4 Mixed-Precision (Bitsandbytes): Requires minimal configuration and dramatically reduces the model's memory footprint. - AutoGPTQ: Time-consuming but leads to a much smaller model and faster inference. The quantization is a one-time cost that pays off in the long run." ,
"meta" : { "additional" : "info3" }
},
{
"id" : 4 ,
"text" : "Ever want to make your LLM inference go brrrrr but got stuck at implementing speculative decoding and finding the suitable draft model? No more pain! Thrilled to unveil Medusa, a simple framework that removes the annoying draft model while getting 2x speedup." ,
"meta" : { "additional" : "info4" }
},
{
"id" : 5 ,
"text" : "vLLM is a fast and easy-to-use library for LLM inference and serving. vLLM is fast with: State-of-the-art serving throughput Efficient management of attention key and value memory with PagedAttention Continuous batching of incoming requests Optimized CUDA kernels" ,
"meta" : { "additional" : "info5" }
}
]
rerankrequest = RerankRequest ( query = query , passages = passages )
results = ranker . rerank ( rerankrequest )
print ( results ) # Reranked output from default reranker
[
{
"id" : 4 ,
"text" : "Ever want to make your LLM inference go brrrrr but got stuck at implementing speculative decoding and finding the suitable draft model? No more pain! Thrilled to unveil Medusa, a simple framework that removes the annoying draft model while getting 2x speedup." ,
"meta" :{
"additional" : "info4"
},
"score" : 0.016847236
},
{
"id" : 5 ,
"text" : "vLLM is a fast and easy-to-use library for LLM inference and serving. vLLM is fast with: State-of-the-art serving throughput Efficient management of attention key and value memory with PagedAttention Continuous batching of incoming requests Optimized CUDA kernels" ,
"meta" :{
"additional" : "info5"
},
"score" : 0.011563735
},
{
"id" : 3 ,
"text" : "There are many ways to increase LLM inference throughput (tokens/second) and decrease memory footprint, sometimes at the same time. Here are a few methods I’ve found effective when working with Llama 2. These methods are all well-integrated with Hugging Face. This list is far from exhaustive; some of these techniques can be used in combination with each other and there are plenty of others to try. - Bettertransformer (Optimum Library): Simply call `model.to_bettertransformer()` on your Hugging Face model for a modest improvement in tokens per second. - Fp4 Mixed-Precision (Bitsandbytes): Requires minimal configuration and dramatically reduces the model's memory footprint. - AutoGPTQ: Time-consuming but leads to a much smaller model and faster inference. The quantization is a one-time cost that pays off in the long run." ,
"meta" :{
"additional" : "info3"
},
"score" : 0.00081340264
},
{
"id" : 1 ,
"text" : "Introduce *lookahead decoding*: - a parallel decoding algo to accelerate LLM inference - w/o the need for a draft model or a data store - linearly decreases # decoding steps relative to log(FLOPs) used per decoding step." ,
"meta" :{
"additional" : "info1"
},
"score" : 0.00063596206
},
{
"id" : 2 ,
"text" : "LLM inference efficiency will be one of the most crucial topics for both industry and academia, simply because the more efficient you are, the more $$$ you will save. vllm project is a must-read for this direction, and now they have just released the paper" ,
"meta" :{
"additional" : "info2"
},
"score" : 0.00024851
}
]

Dans AWS ou d'autres environnements sans serveur, la machine virtuelle entière est en lecture seule, vous devrez peut-être créer votre propre Dir personnalisé. Vous pouvez le faire dans votre dockerfile et l'utiliser pour charger les modèles (et éventuellement comme cache entre les appels chauds). Vous pouvez le faire pendant le paramètre init avec cache_dir.
ranker = Ranker ( model_name = "ms-marco-MiniLM-L-12-v2" , cache_dir = "/opt" )
Pour citer ce référentiel dans votre travail, veuillez cliquer sur le lien "citer ce référentiel" sur le côté droit (descriptions et balises de Rewlow Repo)
COS-MIX: similitude en cosinus et fusion de distance pour une meilleure récupération d'informations
Bryndza à ClimateActivism 2024: position, cible et détection d'événements de haine via la récupération GPT-4 et LLAMA
Position et détection d'événements de haine dans les tweets liés à l'activisme climatique - tâche partagée dans le cas 2024
Une bibliothèque de clones appelée Swiftrank pointe vers nos seaux de modèle, nous travaillons sur une solution provisoire pour éviter ce vol . Merci pour la patience et la compréhension.
Ce problème est résolu, les modèles sont maintenant en hf. Veuillez mettre à jour pour continuer PIP Installer -U FlashRank. Merci pour la patience et la compréhension


