FlashRank
Minor fixes

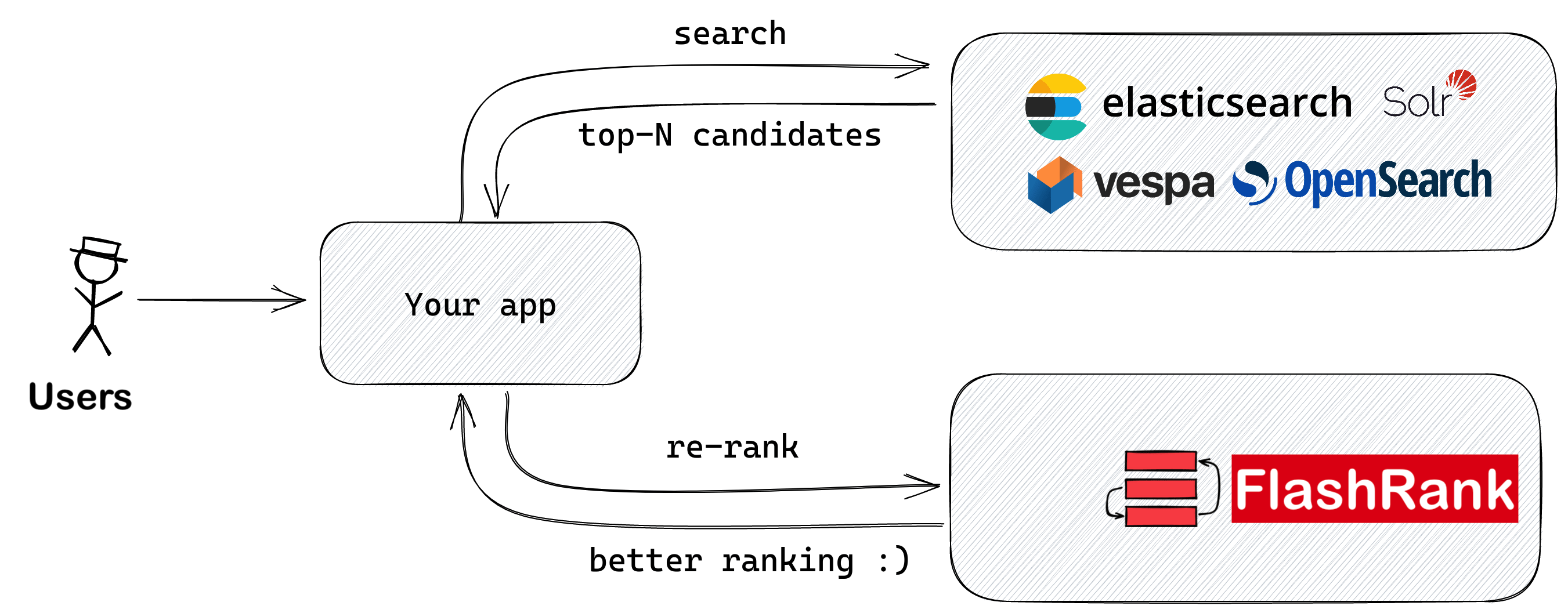
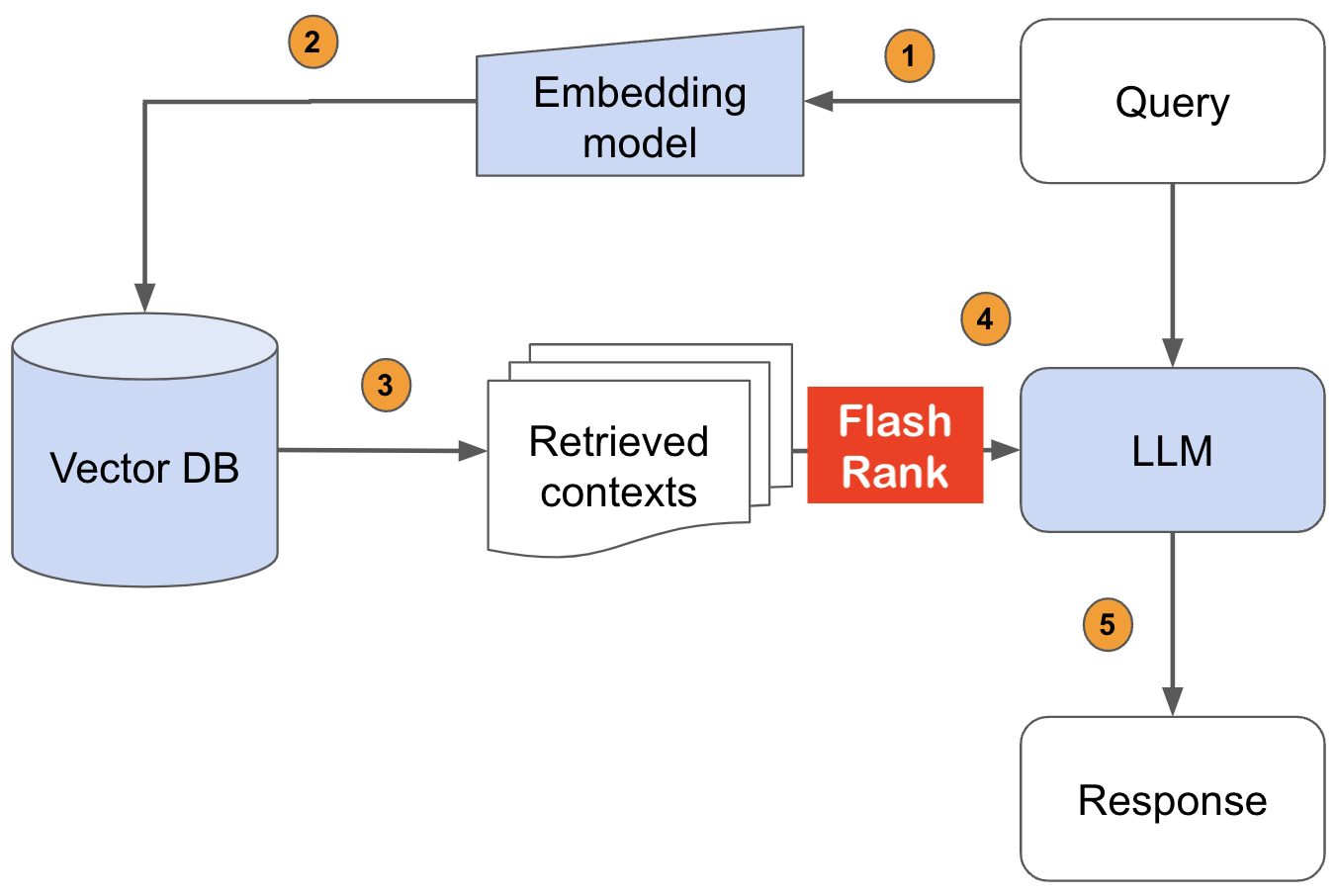
LLMに給餌する前に、SOTAペアワイズまたはリストワイズリランカーで検索結果を再ランクします
既存の検索および検索パイプラインに再ランクを追加するためのUltra-Lite&Super-Fast Pythonライブラリ。これは、すべてのモデル所有者に感謝して、Sota LLMとクロスエンコーダーに基づいています。
サポート:
Max tokens = 512 )Max tokens = 8192 )⚡ウルトラライト:
⏱️超高速:

? $ arcious :
SOTAクロスエンコーダーおよびその他のモデルに基づいています。
| モデル名 | 説明 | サイズ | メモ |
|---|---|---|---|
ms-marco-TinyBERT-L-2-v2 | デフォルトモデル | 〜4MB | モデルカード |
ms-marco-MiniLM-L-12-v2 | Best Cross-encoder reranker | 〜34MB | モデルカード |
rank-T5-flan | 最高の非クロスエンコーダーリランカー | 〜110MB | モデルカード |
ms-marco-MultiBERT-L-12 | 多言語は、100以上の言語をサポートしています | 〜150MB | サポート言語 |
ce-esci-MiniLM-L12-v2 | Amazon Esciデータセットで微調整されています | - | モデルカード |
rank_zephyr_7b_v1_full | 4ビット定量化GGUF | 〜4GB | モデルカード |
miniReranker_arabic_v1 | Only dedicated Arabic Reranker | - | モデルカード |
pip install flashrank pip install flashrank [ listwise ] max_length値は、あなたの最長の箇所を伴うことができるべきである必要があります。言い換えれば、最長の通路(100トークン) +クエリ(16トークン)ペアがトークンの推定である場合、[CLS]や[SEP]などの予約トークンのためにmax_length = 128設定は十分に継続的な部屋であると言います。トークンあたりのパフォーマンスが重要な場合は、トークン密度を推定するために、Openai Tiktokenのようなライブラリを使用してください。パッセージサイズが小さいために512のような長いmax_lengthを避けて非チャラルに与えると、応答時間に悪影響を及ぼします。
from flashrank import Ranker , RerankRequest
# Nano (~4MB), blazing fast model & competitive performance (ranking precision).
ranker = Ranker ( max_length = 128 )
or
# Small (~34MB), slightly slower & best performance (ranking precision).
ranker = Ranker ( model_name = "ms-marco-MiniLM-L-12-v2" , cache_dir = "/opt" )
or
# Medium (~110MB), slower model with best zeroshot performance (ranking precision) on out of domain data.
ranker = Ranker ( model_name = "rank-T5-flan" , cache_dir = "/opt" )
or
# Medium (~150MB), slower model with competitive performance (ranking precision) for 100+ languages (don't use for english)
ranker = Ranker ( model_name = "ms-marco-MultiBERT-L-12" , cache_dir = "/opt" )
or
ranker = Ranker ( model_name = "rank_zephyr_7b_v1_full" , max_length = 1024 ) # adjust max_length based on your passage length # Metadata is optional, Id can be your DB ids from your retrieval stage or simple numeric indices.
query = "How to speedup LLMs?"
passages = [
{
"id" : 1 ,
"text" : "Introduce *lookahead decoding*: - a parallel decoding algo to accelerate LLM inference - w/o the need for a draft model or a data store - linearly decreases # decoding steps relative to log(FLOPs) used per decoding step." ,
"meta" : { "additional" : "info1" }
},
{
"id" : 2 ,
"text" : "LLM inference efficiency will be one of the most crucial topics for both industry and academia, simply because the more efficient you are, the more $$$ you will save. vllm project is a must-read for this direction, and now they have just released the paper" ,
"meta" : { "additional" : "info2" }
},
{
"id" : 3 ,
"text" : "There are many ways to increase LLM inference throughput (tokens/second) and decrease memory footprint, sometimes at the same time. Here are a few methods I’ve found effective when working with Llama 2. These methods are all well-integrated with Hugging Face. This list is far from exhaustive; some of these techniques can be used in combination with each other and there are plenty of others to try. - Bettertransformer (Optimum Library): Simply call `model.to_bettertransformer()` on your Hugging Face model for a modest improvement in tokens per second. - Fp4 Mixed-Precision (Bitsandbytes): Requires minimal configuration and dramatically reduces the model's memory footprint. - AutoGPTQ: Time-consuming but leads to a much smaller model and faster inference. The quantization is a one-time cost that pays off in the long run." ,
"meta" : { "additional" : "info3" }
},
{
"id" : 4 ,
"text" : "Ever want to make your LLM inference go brrrrr but got stuck at implementing speculative decoding and finding the suitable draft model? No more pain! Thrilled to unveil Medusa, a simple framework that removes the annoying draft model while getting 2x speedup." ,
"meta" : { "additional" : "info4" }
},
{
"id" : 5 ,
"text" : "vLLM is a fast and easy-to-use library for LLM inference and serving. vLLM is fast with: State-of-the-art serving throughput Efficient management of attention key and value memory with PagedAttention Continuous batching of incoming requests Optimized CUDA kernels" ,
"meta" : { "additional" : "info5" }
}
]
rerankrequest = RerankRequest ( query = query , passages = passages )
results = ranker . rerank ( rerankrequest )
print ( results ) # Reranked output from default reranker
[
{
"id" : 4 ,
"text" : "Ever want to make your LLM inference go brrrrr but got stuck at implementing speculative decoding and finding the suitable draft model? No more pain! Thrilled to unveil Medusa, a simple framework that removes the annoying draft model while getting 2x speedup." ,
"meta" :{
"additional" : "info4"
},
"score" : 0.016847236
},
{
"id" : 5 ,
"text" : "vLLM is a fast and easy-to-use library for LLM inference and serving. vLLM is fast with: State-of-the-art serving throughput Efficient management of attention key and value memory with PagedAttention Continuous batching of incoming requests Optimized CUDA kernels" ,
"meta" :{
"additional" : "info5"
},
"score" : 0.011563735
},
{
"id" : 3 ,
"text" : "There are many ways to increase LLM inference throughput (tokens/second) and decrease memory footprint, sometimes at the same time. Here are a few methods I’ve found effective when working with Llama 2. These methods are all well-integrated with Hugging Face. This list is far from exhaustive; some of these techniques can be used in combination with each other and there are plenty of others to try. - Bettertransformer (Optimum Library): Simply call `model.to_bettertransformer()` on your Hugging Face model for a modest improvement in tokens per second. - Fp4 Mixed-Precision (Bitsandbytes): Requires minimal configuration and dramatically reduces the model's memory footprint. - AutoGPTQ: Time-consuming but leads to a much smaller model and faster inference. The quantization is a one-time cost that pays off in the long run." ,
"meta" :{
"additional" : "info3"
},
"score" : 0.00081340264
},
{
"id" : 1 ,
"text" : "Introduce *lookahead decoding*: - a parallel decoding algo to accelerate LLM inference - w/o the need for a draft model or a data store - linearly decreases # decoding steps relative to log(FLOPs) used per decoding step." ,
"meta" :{
"additional" : "info1"
},
"score" : 0.00063596206
},
{
"id" : 2 ,
"text" : "LLM inference efficiency will be one of the most crucial topics for both industry and academia, simply because the more efficient you are, the more $$$ you will save. vllm project is a must-read for this direction, and now they have just released the paper" ,
"meta" :{
"additional" : "info2"
},
"score" : 0.00024851
}
]

AWSまたはその他のサーバーレス環境では、VM全体が読み取り専用です。独自のカスタムディレクトリを作成する必要があります。 DockerFileでこれを行い、モデルのロードに使用することができます(最終的には温かい通話の間のキャッシュとして)。 cache_dirパラメーターを使用してinit中に行うことができます。
ranker = Ranker ( model_name = "ms-marco-MiniLM-L-12-v2" , cache_dir = "/opt" )
作業でこのリポジトリを引用するには、右側の「このリポジトリを引用」リンクをクリックしてください(Bewlow Repoの説明とタグ)
cos-mix:改善された情報検索のためのコサインの類似性と距離融合
Climateactivism 2024のBryndza:検索されたGPT-4およびLLAMAを介したスタンス、ターゲット、および憎悪イベント検出
気候活動に関連するツイートでのスタンスと憎悪のイベントの検出 - ケース2024での共有タスク
Swiftrankと呼ばれるクローンライブラリは、モデルバケットを指しています。この盗みを避けるための暫定ソリューションに取り組んでいます。忍耐と理解をありがとう。
この問題は解決され、モデルは現在HFにあります。アップグレードして、PIPインストール-U Flashrankを続行してください。忍耐と理解をありがとう


