FlashRank
Minor fixes

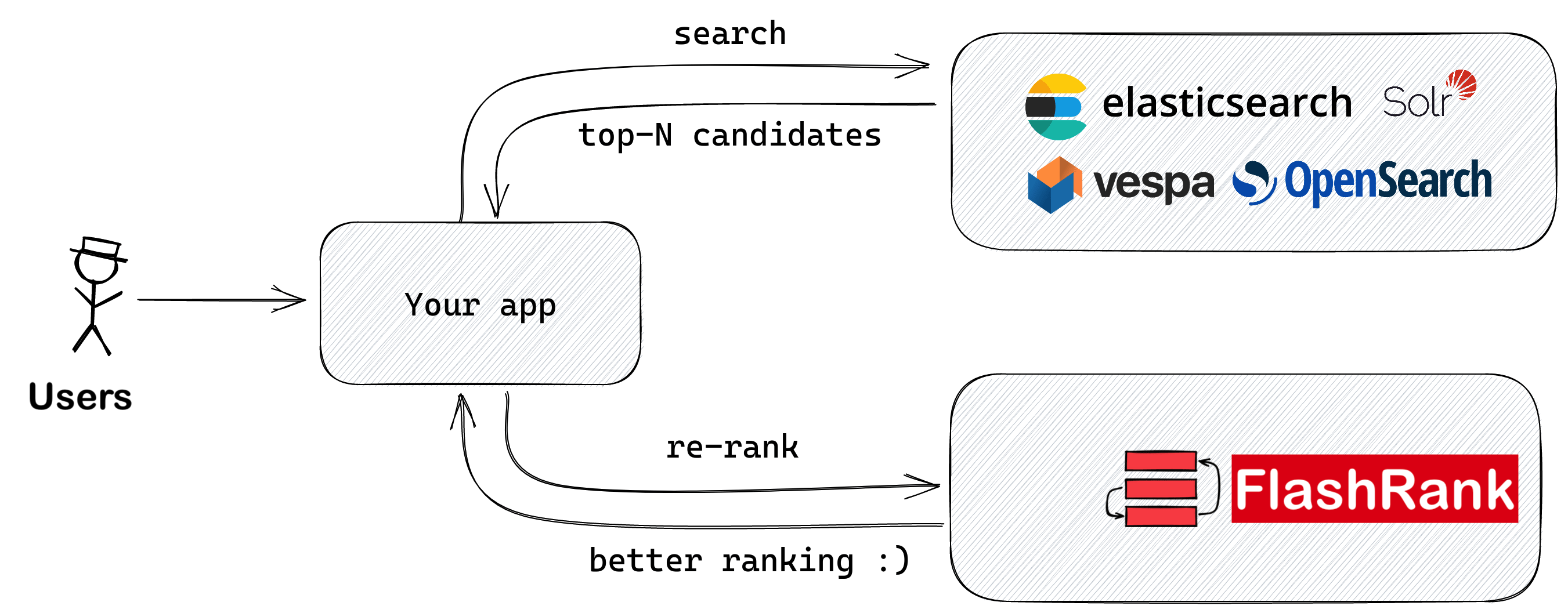
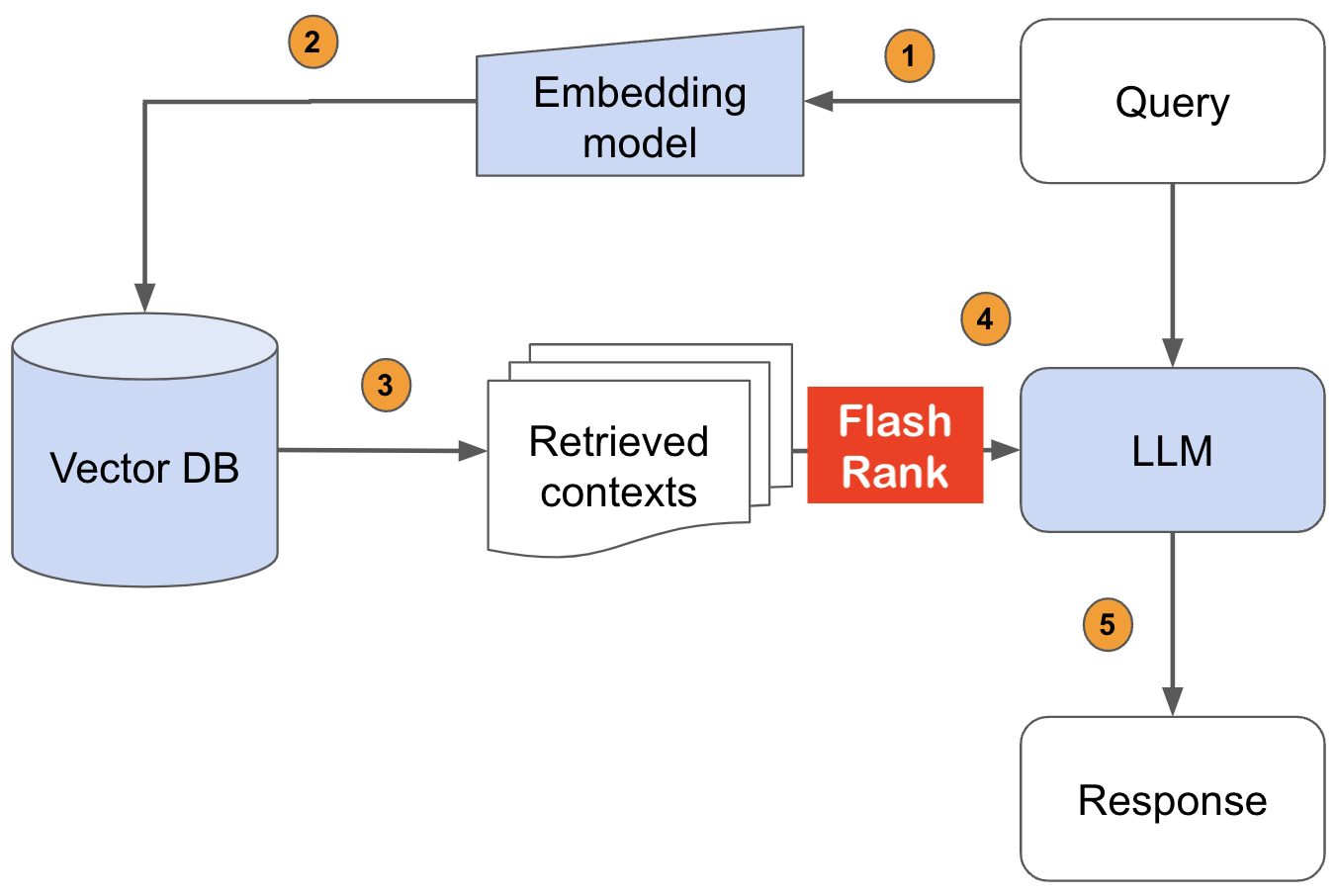
Перед тем, как подавать в свои LLMS, повторно оцените результаты поиска с помощью SOTA Pairse или Diftise Rerankers, прежде чем кормить
Ultra-Lite & Super-Fast Library Python, чтобы добавить повторную оценку в ваши существующие трубопроводы поиска и поиска. Он основан на SOTA LLMS и CrossCoders, с благодарностью всем владельцам моделей.
Поддержка:
Max tokens = 512 )Max tokens = 8192 )⚡ Ultra-Lite :
⏱ Super-Fast :

? $ incious :
Основано на кросс-кодерах SOTA и других моделях :
| Название модели | Описание | Размер | Примечания |
|---|---|---|---|
ms-marco-TinyBERT-L-2-v2 | Модель по умолчанию | ~ 4 МБ | Модель карта |
ms-marco-MiniLM-L-12-v2 | Best Cross-encoder reranker | ~ 34 МБ | Модель карта |
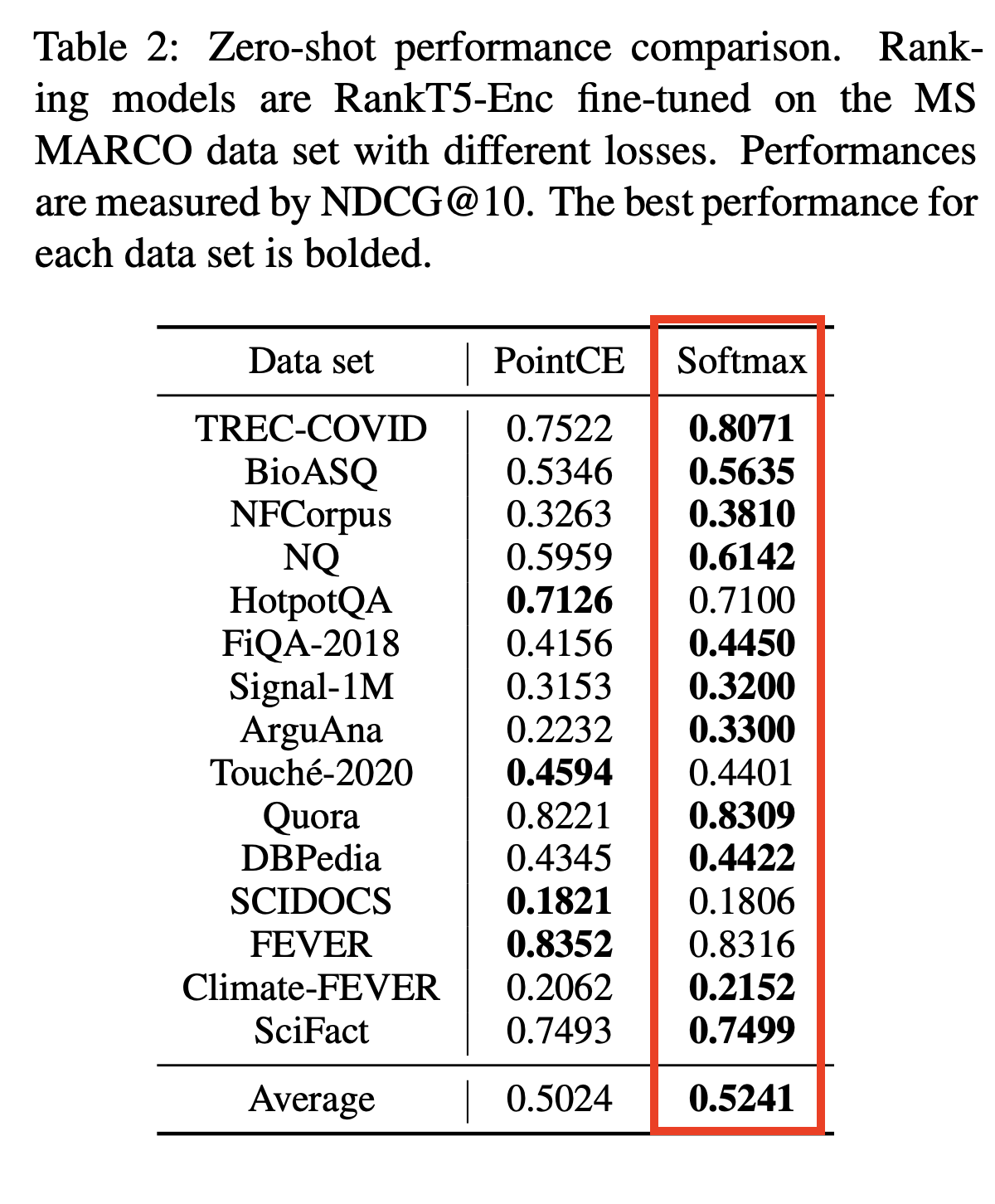
rank-T5-flan | Лучший не поперечный реранкер | ~ 110 МБ | Модель карта |
ms-marco-MultiBERT-L-12 | Многоязычный, поддерживает 100+ языков | ~ 150 МБ | Поддерживаемые языки |
ce-esci-MiniLM-L12-v2 | Настройка набора данных Amazon ESCI | - | Модель карта |
rank_zephyr_7b_v1_full | 4-битный gguf | ~ 4 ГБ | Модель карта |
miniReranker_arabic_v1 | Only dedicated Arabic Reranker | - | Модель карта |
pip install flashrank pip install flashrank [ listwise ] Значение max_length должно быть значительным, способным приспособить ваш самый длинный проход. Другими словами, если ваш самый длинный отрывок (100 токенов) + Запрос (16 токенов) Пара по оценке токена 116, то, скажем, настройка max_length = 128 - это достаточно хорошо включено для зарезервированных токенов, таких как [CLS] и [SEP]. Используйте Openai Tiktoken, как библиотеки, чтобы оценить плотность токенов, если для вас важна производительность на токен. Неважно, давая более длинное max_length , например, 512 для меньших размеров прохода, негативно повлияет на время отклика.
from flashrank import Ranker , RerankRequest
# Nano (~4MB), blazing fast model & competitive performance (ranking precision).
ranker = Ranker ( max_length = 128 )
or
# Small (~34MB), slightly slower & best performance (ranking precision).
ranker = Ranker ( model_name = "ms-marco-MiniLM-L-12-v2" , cache_dir = "/opt" )
or
# Medium (~110MB), slower model with best zeroshot performance (ranking precision) on out of domain data.
ranker = Ranker ( model_name = "rank-T5-flan" , cache_dir = "/opt" )
or
# Medium (~150MB), slower model with competitive performance (ranking precision) for 100+ languages (don't use for english)
ranker = Ranker ( model_name = "ms-marco-MultiBERT-L-12" , cache_dir = "/opt" )
or
ranker = Ranker ( model_name = "rank_zephyr_7b_v1_full" , max_length = 1024 ) # adjust max_length based on your passage length # Metadata is optional, Id can be your DB ids from your retrieval stage or simple numeric indices.
query = "How to speedup LLMs?"
passages = [
{
"id" : 1 ,
"text" : "Introduce *lookahead decoding*: - a parallel decoding algo to accelerate LLM inference - w/o the need for a draft model or a data store - linearly decreases # decoding steps relative to log(FLOPs) used per decoding step." ,
"meta" : { "additional" : "info1" }
},
{
"id" : 2 ,
"text" : "LLM inference efficiency will be one of the most crucial topics for both industry and academia, simply because the more efficient you are, the more $$$ you will save. vllm project is a must-read for this direction, and now they have just released the paper" ,
"meta" : { "additional" : "info2" }
},
{
"id" : 3 ,
"text" : "There are many ways to increase LLM inference throughput (tokens/second) and decrease memory footprint, sometimes at the same time. Here are a few methods I’ve found effective when working with Llama 2. These methods are all well-integrated with Hugging Face. This list is far from exhaustive; some of these techniques can be used in combination with each other and there are plenty of others to try. - Bettertransformer (Optimum Library): Simply call `model.to_bettertransformer()` on your Hugging Face model for a modest improvement in tokens per second. - Fp4 Mixed-Precision (Bitsandbytes): Requires minimal configuration and dramatically reduces the model's memory footprint. - AutoGPTQ: Time-consuming but leads to a much smaller model and faster inference. The quantization is a one-time cost that pays off in the long run." ,
"meta" : { "additional" : "info3" }
},
{
"id" : 4 ,
"text" : "Ever want to make your LLM inference go brrrrr but got stuck at implementing speculative decoding and finding the suitable draft model? No more pain! Thrilled to unveil Medusa, a simple framework that removes the annoying draft model while getting 2x speedup." ,
"meta" : { "additional" : "info4" }
},
{
"id" : 5 ,
"text" : "vLLM is a fast and easy-to-use library for LLM inference and serving. vLLM is fast with: State-of-the-art serving throughput Efficient management of attention key and value memory with PagedAttention Continuous batching of incoming requests Optimized CUDA kernels" ,
"meta" : { "additional" : "info5" }
}
]
rerankrequest = RerankRequest ( query = query , passages = passages )
results = ranker . rerank ( rerankrequest )
print ( results ) # Reranked output from default reranker
[
{
"id" : 4 ,
"text" : "Ever want to make your LLM inference go brrrrr but got stuck at implementing speculative decoding and finding the suitable draft model? No more pain! Thrilled to unveil Medusa, a simple framework that removes the annoying draft model while getting 2x speedup." ,
"meta" :{
"additional" : "info4"
},
"score" : 0.016847236
},
{
"id" : 5 ,
"text" : "vLLM is a fast and easy-to-use library for LLM inference and serving. vLLM is fast with: State-of-the-art serving throughput Efficient management of attention key and value memory with PagedAttention Continuous batching of incoming requests Optimized CUDA kernels" ,
"meta" :{
"additional" : "info5"
},
"score" : 0.011563735
},
{
"id" : 3 ,
"text" : "There are many ways to increase LLM inference throughput (tokens/second) and decrease memory footprint, sometimes at the same time. Here are a few methods I’ve found effective when working with Llama 2. These methods are all well-integrated with Hugging Face. This list is far from exhaustive; some of these techniques can be used in combination with each other and there are plenty of others to try. - Bettertransformer (Optimum Library): Simply call `model.to_bettertransformer()` on your Hugging Face model for a modest improvement in tokens per second. - Fp4 Mixed-Precision (Bitsandbytes): Requires minimal configuration and dramatically reduces the model's memory footprint. - AutoGPTQ: Time-consuming but leads to a much smaller model and faster inference. The quantization is a one-time cost that pays off in the long run." ,
"meta" :{
"additional" : "info3"
},
"score" : 0.00081340264
},
{
"id" : 1 ,
"text" : "Introduce *lookahead decoding*: - a parallel decoding algo to accelerate LLM inference - w/o the need for a draft model or a data store - linearly decreases # decoding steps relative to log(FLOPs) used per decoding step." ,
"meta" :{
"additional" : "info1"
},
"score" : 0.00063596206
},
{
"id" : 2 ,
"text" : "LLM inference efficiency will be one of the most crucial topics for both industry and academia, simply because the more efficient you are, the more $$$ you will save. vllm project is a must-read for this direction, and now they have just released the paper" ,
"meta" :{
"additional" : "info2"
},
"score" : 0.00024851
}
]

В AWS или других без серверных средах виртуальной машины только для чтения вам, возможно, придется создать свой собственный директор. Вы можете сделать это в своем Dockerfile и использовать его для загрузки моделей (и в конечном итоге в качестве кэша между теплыми вызовами). Вы можете сделать это во время init с параметром cache_dir.
ranker = Ranker ( model_name = "ms-marco-MiniLM-L-12-v2" , cache_dir = "/opt" )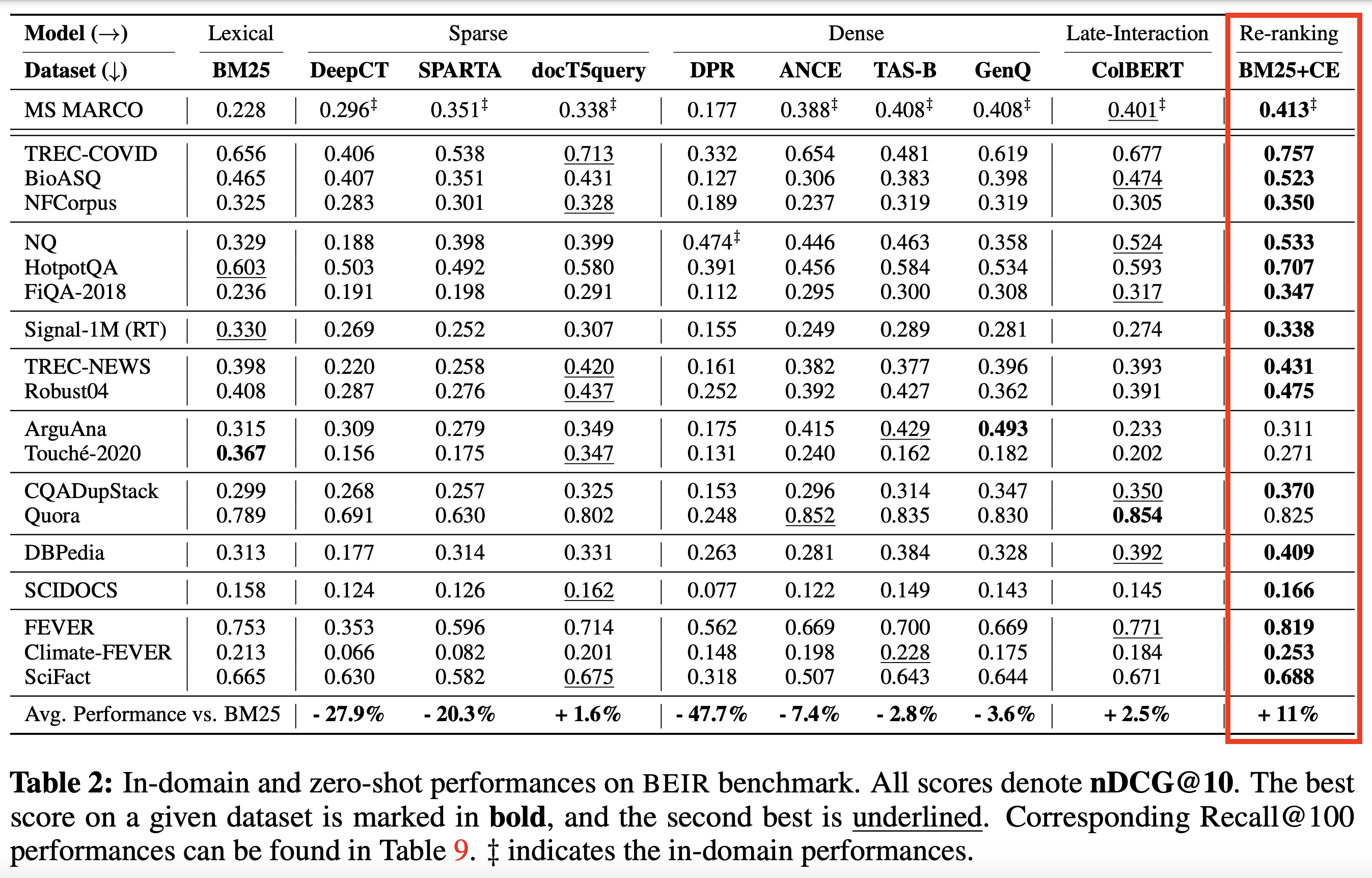
Чтобы привести этот репозиторий в своей работе, нажмите на ссылку «Стидеть этот репозиторий» на правой стороне (описания и теги Bewlow)
COS-MIX: сходство косинуса и слияние расстояния для улучшения поиска информации
Bryndza в ClimateActivism 2024: Позиция, цель и ненависть, обнаружение событий с помощью поиска GPT-4 и Llama.
Постановка и ненависть обнаружены в твитах, связанных с климатической активностью - общая задача в случае 2024
Библиотека клонов под названием Swiftrank указывает на наши модельные ведра, мы работаем над промежуточным решением, чтобы избежать этого кражи . Спасибо за терпение и понимание.
Эта проблема решена, модели сейчас в HF. Пожалуйста, обновите, чтобы продолжить установку PIP -u FlashRank. Спасибо за терпение и понимание


