SummerTime
v1.2.1

库可帮助用户根据其特定任务或需求选择适当的摘要工具。包括模型,评估指标和数据集。
图书馆架构如下:
注意:夏季有积极发展,强烈鼓励任何有用的评论,请打开问题或与任何团队成员接触。
# install extra dependencies first
pip install pyrouge@git+https://github.com/bheinzerling/pyrouge.git
pip install en_core_web_sm@https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.0.0/en_core_web_sm-3.0.0-py3-none-any.whl
# install summertime from PyPI
pip install summertime
pip安装另外,要享受最新功能,您可以从来源安装:
git clone [email protected]:Yale-LILY/SummerTime
pip install -e . ROUGE (使用评估时) export ROUGE_HOME=/usr/local/lib/python3.7/dist-packages/summ_eval/ROUGE-1.5.5/导入模型,初始化默认模型并总结样本文档。
from summertime import model
sample_model = model . summarizer ()
documents = [
""" PG&E stated it scheduled the blackouts in response to forecasts for high winds amid dry conditions.
The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were scheduled to be affected
by the shutoffs which were expected to last through at least midday tomorrow."""
]
sample_model . summarize ( documents )
# ["California's largest electricity provider has turned off power to hundreds of thousands of customers."]另外,请运行我们的COLAB笔记本,以进行更多的动手演示和更多示例。
夏季支持不同的模型(例如Textrank,Bart,Longformer)以及用于更复杂的摘要任务的模型包装器(例如,用于多doc摘要的关节模型,基于查询的摘要的BM25检索)。还支持几种多语言模型(MT5和MBART)。
| 型号 | 单次 | 多分子 | 基于对话 | 基于查询 | 多种语言 |
|---|---|---|---|---|---|
| Bartmodel | ✔️ | ||||
| BM25SummModel | ✔️ | ||||
| hmnetmodel | ✔️ | ||||
| Lexrankmodel | ✔️ | ||||
| longformermodel | ✔️ | ||||
| mbartmodel | ✔️ | 50种语言(此处完整列表) | |||
| MT5模型 | ✔️ | 101语言(在此处列表) | |||
| Translation PipeLineModel | ✔️ | 〜70种语言 | |||
| MultidocjointModel | ✔️ | ||||
| 多尾paratemodel | ✔️ | ||||
| Pegasusmodel | ✔️ | ||||
| TextrankModel | ✔️ | ||||
| tfidfsummmodel | ✔️ |
要查看所有受支持的模型,请运行:
from summertime . model import SUPPORTED_SUMM_MODELS
print ( SUPPORTED_SUMM_MODELS ) from summertime import model
# To use a default model
default_model = model . summarizer ()
# Or a specific model
bart_model = model . BartModel ()
pegasus_model = model . PegasusModel ()
lexrank_model = model . LexRankModel ()
textrank_model = model . TextRankModel ()用户可以轻松地访问文档以协助模型选择
default_model . show_capability ()
pegasus_model . show_capability ()
textrank_model . show_capability ()要使用模型进行总结,只需运行:
documents = [
""" PG&E stated it scheduled the blackouts in response to forecasts for high winds amid dry conditions.
The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were scheduled to be affected
by the shutoffs which were expected to last through at least midday tomorrow."""
]
default_model . summarize ( documents )
# or
pegasus_model . summarize ( documents )所有模型都可以使用以下可选选项初始化:
def __init__ ( self ,
trained_domain : str = None ,
max_input_length : int = None ,
max_output_length : int = None ,
):所有模型将实现以下方法:
def summarize ( self ,
corpus : Union [ List [ str ], List [ List [ str ]]],
queries : List [ str ] = None ) -> List [ str ]:
def show_capability ( cls ) -> None :夏季支持跨不同域的不同汇总数据集(例如,CNNDM数据集 - 新闻文章,Samsum,Samsum-对话语料库,QM -SUM-基于查询的对话语料库,Multinews-多文件 - 多文件语料库,ML -SUM,ML -SUM,ML -SUM-多语言语料库 - 多语言语料库,PubMedqa -Medical Domain,Arxiv -Arxiv -Science Paperers domain,其他。
| 数据集 | 领域 | #示例 | src。长度 | TGT。长度 | 询问 | 多分子 | 对话 | 多种语言 |
|---|---|---|---|---|---|---|---|---|
| arxiv | 科学文章 | 215k | 4.9k | 220 | ||||
| CNN/DM(3.0.0) | 消息 | 300k | 781 | 56 | ||||
| mlsumdataset | 多语言新闻 | 1.5m+ | 632 | 34 | ✔️ | 德国,西班牙,法语,俄罗斯,土耳其语 | ||
| 多新的 | 消息 | 56k | 2.1k | 263.8 | ✔️ | |||
| Samsum | 开放域 | 16K | 94 | 20 | ✔️ | |||
| PubMedqa | 医疗的 | 272k | 244 | 32 | ✔️ | |||
| QMSUM | 会议 | 1k | 9.0k | 69.6 | ✔️ | ✔️ | ||
| Scisummnet | 科学文章 | 1k | 4.7k | 150 | ||||
| summscreen | 电视节目 | 26.9k | 6.6k | 337.4 | ✔️ | |||
| XSUM | 消息 | 226k | 431 | 23.3 | ||||
| xlsum | 消息 | 135m | ??? | ??? | 45种语言(请参阅文档) | |||
| 大规模 | 消息 | 12m+ | ??? | ??? | 78种语言(有关详细信息,请参见README的多语言摘要部分) |
要查看所有受支持的数据集,请运行:
from summertime import dataset
print ( dataset . list_all_dataset ()) from summertime import dataset
cnn_dataset = dataset . CnndmDataset ()
# or
xsum_dataset = dataset . XsumDataset ()
# ..etc 所有数据集都是SummDataset类的实现。他们的数据拆分可以访问如下:
dataset = dataset . CnndmDataset ()
train_data = dataset . train_set
dev_data = dataset . dev_set
test_data = dataset . test_set 要查看数据集的详细信息,请运行:
dataset = dataset . CnndmDataset ()
dataset . show_description ()所有数据集中的数据都包含在SummInstance类对象中,该对象具有以下属性:
data_instance . source = source # either `List[str]` or `str`, depending on the dataset itself, string joining may needed to fit into specific models.
data_instance . summary = summary # a string summary that serves as ground truth
data_instance . query = query # Optional, applies when a string query is present
print ( data_instance ) # to print the data instance in its entirety使用发电机加载数据以节省空间和时间
data_instance = next ( cnn_dataset . train_set )
print ( data_instance ) import itertools
# Get a slice from the train set generator - first 5 instances
train_set = itertools . islice ( cnn_dataset . train_set , 5 )
corpus = [ instance . source for instance in train_set ]
print ( corpus )您可以使用定制数据使用CustomDataset数据,该类将数据加载到夏季数据集类别中
from summertime . dataset import CustomDataset
''' The train_set, test_set and validation_set have the following format:
List[Dict], list of dictionaries that contain a data instance.
The dictionary is in the form:
{"source": "source_data", "summary": "summary_data", "query":"query_data"}
* source_data is either of type List[str] or str
* summary_data is of type str
* query_data is of type str
The list of dictionaries looks as follows:
[dictionary_instance_1, dictionary_instance_2, ...]
'''
# Create sample data
train_set = [
{
"source" : "source1" ,
"summary" : "summary1" ,
"query" : "query1" , # only included, if query is present
}
]
validation_set = [
{
"source" : "source2" ,
"summary" : "summary2" ,
"query" : "query2" ,
}
]
test_set = [
{
"source" : "source3" ,
"summary" : "summary3" ,
"query" : "query3" ,
}
]
# Depending on the dataset properties, you can specify the type of dataset
# i.e multi_doc, query_based, dialogue_based. If not specified, they default to false
custom_dataset = CustomDataset (
train_set = train_set ,
validation_set = validation_set ,
test_set = test_set ,
query_based = True ,
multi_doc = True
dialogue_based = False ) import itertools
from summertime import dataset , model
cnn_dataset = dataset . CnndmDataset ()
# Get a slice of the train set - first 5 instances
train_set = itertools . islice ( cnn_dataset . train_set , 5 )
corpus = [ instance . source for instance in train_set ]
# Example 1 - traditional non-neural model
# LexRank model
lexrank = model . LexRankModel ( corpus )
print ( lexrank . show_capability ())
lexrank_summary = lexrank . summarize ( corpus )
print ( lexrank_summary )
# Example 2 - A spaCy pipeline for TextRank (another non-neueral extractive summarization model)
# TextRank model
textrank = model . TextRankModel ()
print ( textrank . show_capability ())
textrank_summary = textrank . summarize ( corpus )
print ( textrank_summary )
# Example 3 - A neural model to handle large texts
# LongFormer Model
longformer = model . LongFormerModel ()
longformer . show_capability ()
longformer_summary = longformer . summarize ( corpus )
print ( longformer_summary )多语言模型的summarize()方法自动检查输入文档语言。
单大型多语言模型可以以与单语模型相同的方式初始化和使用。如果模型不支持的语言输入,他们会返回错误。
mbart_model = st_model . MBartModel ()
mt5_model = st_model . MT5Model ()
# load Spanish portion of MLSum dataset
mlsum = datasets . MlsumDataset ([ "es" ])
corpus = itertools . islice ( mlsum . train_set , 5 )
corpus = [ instance . source for instance in train_set ]
# mt5 model will automatically detect Spanish as the language and indicate that this is supported!
mt5_model . summarize ( corpus )目前在我们实施Massiveumm数据集中支持以下语言:Amharic,Amharic,Arabic,Assamese,Asmare,Amymara,Azerbaijani,Bambara,Bambara,Bengali,Bengali,Bosnian,Bosnian,Bosnian,Pulgarian,Pulgarian,Catalan,Catalan,Catalan,Czech,捷克 Gujarati, Haitian, Hausa, Hebrew, Hindi, Croatian, Hungarian, Armenian,Igbo, Indonesian, Icelandic, Italian, Japanese, Kannada, Georgian, Khmer, Kinyarwanda, Kyrgyz, Korean, Kurdish, Lao, Latvian, Lingala, Lithuanian, Malayalam, Marathi, Macedonian,马尔加斯加斯,蒙古人,缅甸,南恩德贝尔,尼泊尔,荷兰人,奥里亚,奥里莫,旁遮普,波兰,波兰语,葡萄牙语,达里(Dari塔吉克,泰国,蒂格里尼亚,土耳其语,乌克兰,乌尔都语,乌兹别克,越南,Xhosa,Yoruba,Yue Chinese,中文,中文,Bislama和Gaelic。
夏季支持不同的评估指标,包括:Bertscore,Bleu,Meteor,Rouge,Rougewe
打印所有支持的指标:
from summertime . evaluation import SUPPORTED_EVALUATION_METRICS
print ( SUPPORTED_EVALUATION_METRICS ) import summertime . evaluation as st_eval
bert_eval = st_eval . bertscore ()
bleu_eval = st_eval . bleu_eval ()
meteor_eval = st_eval . bleu_eval ()
rouge_eval = st_eval . rouge ()
rougewe_eval = st_eval . rougewe ()所有评估指标都可以通过以下可选参数初始化:
def __init__ ( self , metric_name ):所有评估指标对象实现以下方法:
def evaluate ( self , model , data ):
def get_dict ( self , keys ):获取样本摘要数据
from summertime . evaluation . base_metric import SummMetric
from summertime . evaluation import Rouge , RougeWe , BertScore
import itertools
# Evaluates model on subset of cnn_dailymail
# Get a slice of the train set - first 5 instances
train_set = itertools . islice ( cnn_dataset . train_set , 5 )
corpus = [ instance for instance in train_set ]
print ( corpus )
articles = [ instance . source for instance in corpus ]
summaries = sample_model . summarize ( articles )
targets = [ instance . summary for instance in corpus ]评估不同指标的数据
from summertime . evaluation import BertScore , Rouge , RougeWe ,
# Calculate BertScore
bert_metric = BertScore ()
bert_score = bert_metric . evaluate ( summaries , targets )
print ( bert_score )
# Calculate Rouge
rouge_metric = Rouge ()
rouge_score = rouge_metric . evaluate ( summaries , targets )
print ( rouge_score )
# Calculate RougeWe
rougewe_metric = RougeWe ()
rougwe_score = rougewe_metric . evaluate ( summaries , targets )
print ( rougewe_score )给定夏季数据集,您可以使用pipelines.assemble_model_pipeline函数来检索与提供的数据集兼容的初始化夏季模型的列表。
from summertime . pipeline import assemble_model_pipeline
from summertime . dataset import CnndmDataset , QMsumDataset
single_doc_models = assemble_model_pipeline ( CnndmDataset )
# [
# (<model.single_doc.bart_model.BartModel object at 0x7fcd43aa12e0>, 'BART'),
# (<model.single_doc.lexrank_model.LexRankModel object at 0x7fcd43aa1460>, 'LexRank'),
# (<model.single_doc.longformer_model.LongformerModel object at 0x7fcd43b17670>, 'Longformer'),
# (<model.single_doc.pegasus_model.PegasusModel object at 0x7fccb84f2910>, 'Pegasus'),
# (<model.single_doc.textrank_model.TextRankModel object at 0x7fccb84f2880>, 'TextRank')
# ]
query_based_multi_doc_models = assemble_model_pipeline ( QMsumDataset )
# [
# (<model.query_based.tf_idf_model.TFIDFSummModel object at 0x7fc9c9c81e20>, 'TF-IDF (HMNET)'),
# (<model.query_based.bm25_model.BM25SummModel object at 0x7fc8b4fa8c10>, 'BM25 (HMNET)')
# ]=======
给定夏季数据集,您可以使用pipelines.assemble_model_pipeline函数来检索与提供的数据集兼容的初始化夏季模型的列表。
# Get test data
import itertools
from summertime . dataset import XsumDataset
# Get a slice of the train set - first 5 instances
sample_dataset = XsumDataset ()
sample_data = itertools . islice ( sample_dataset . train_set , 100 )
generator1 = iter ( sample_data )
generator2 = iter ( sample_data )
bart_model = BartModel ()
pegasus_model = PegasusModel ()
models = [ bart_model , pegasus_model ]
metrics = [ metric () for metric in SUPPORTED_EVALUATION_METRICS ] from summertime . evaluation . model_selector import ModelSelector
selector = ModelSelector ( models , generator1 , metrics )
table = selector . run ()
print ( table )
visualization = selector . visualize ( table )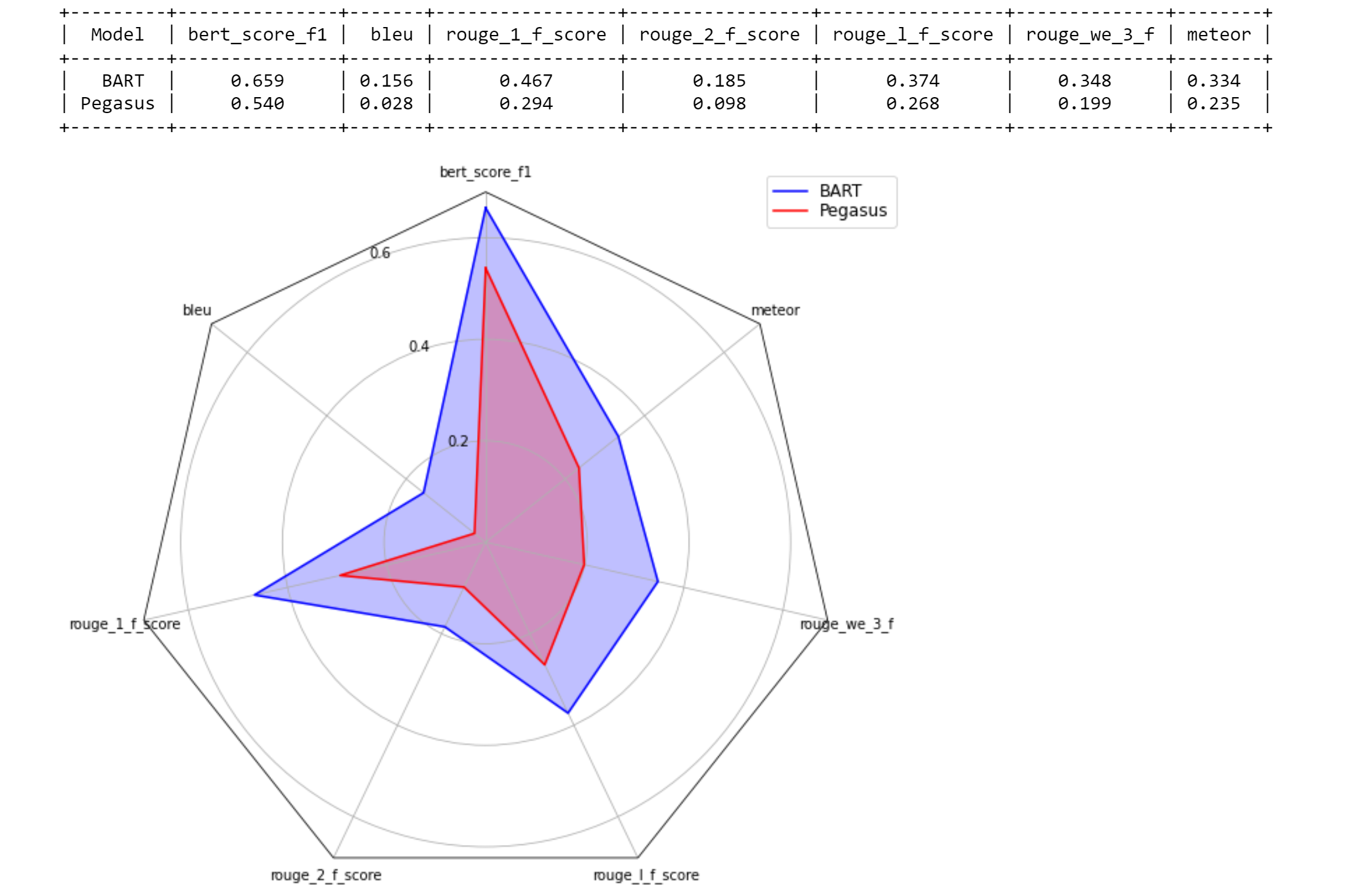
from summertime . evaluation . model_selector import ModelSelector
new_selector = ModelSelector ( models , generator2 , metrics )
smart_table = new_selector . run_halving ( min_instances = 2 , factor = 2 )
print ( smart_table )
visualization_smart = selector . visualize ( smart_table ) from summertime . evaluation . model_selector import ModelSelector
from summertime . evaluation . error_viz import scatter
keys = ( "bert_score_f1" , "bleu" , "rouge_1_f_score" , "rouge_2_f_score" , "rouge_l_f_score" , "rouge_we_3_f" , "meteor" )
scatter ( models , sample_data , metrics [ 1 : 3 ], keys = keys [ 1 : 3 ], max_instances = 5 )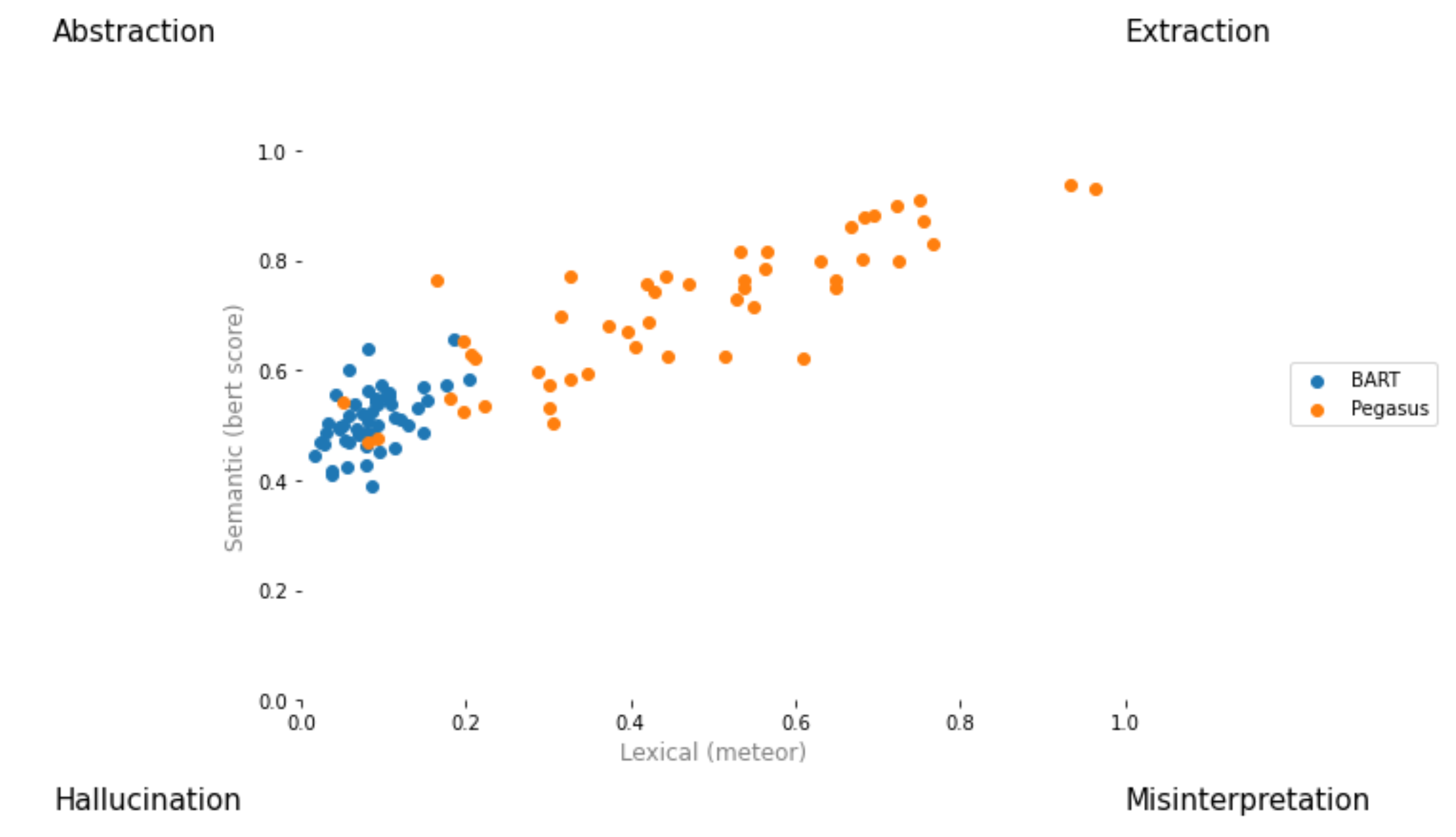
创建一个拉请求并将其命名[ your_gh_username ]/[ your_branch_name ]。如果需要,请解决您自己的分支机构与MAIN的合并冲突。不要直接推到主。
如果还没有,请安装black和flake8 :
pip install black
pip install flake8在推动提交或合并分支之前,请从项目根部运行以下命令。请注意, black将写入文件,并且您应该在推动之前添加并提交black做出的更改:
black .
flake8 .或者,如果您想提起特定的文件:
black path/to/specific/file.py
flake8 path/to/specific/file.py确保black不会重新格式化任何文件,并且flake8不会打印任何错误。如果您想覆盖或忽略black或flake8强制执行的任何偏好或实践,请在PR中发表评论,以获取生成警告或错误日志的任何代码行。不要直接编辑配置文件,例如setup.cfg 。
有关安装的文档,忽略文件/行和高级用法,请参见black文档和flake8文档。另外,以下可能很有用:
black [file.py] --diff以差异为diff而不是直接进行更改black [file.py] --check以使用状态代码预览更改而不是直接进行更改git diff -u | flake8 --diff仅在工作分支上仅运行flake8的木请注意,我们的CI测试套件将包括调用black --check .和flake8 --count .在所有非计算和非设定的Python文件上,所有测试都需要零错误级输出。
我们的连续集成系统是通过GitHub动作提供的。当创建或更新任何拉动请求或每当更新main时,存储库的单元测试将作为tangra上的作业运行,以供该拉动请求。构建作业将在几分钟内通过或失败,并且在操作下可见构建状态和日志。请确保在合并之前,请确保所有支票都通过所有支票(即所有作业运行到完成的所有步骤),或者请求审查。要跳过任何特定的提交中的构建,请将[skip ci]附加到提交消息。请注意,CI中不包含带有子字符串/no-ci/分支名称中任何地方的PR。
该存储库由Dragomir Radev教授领导的耶鲁大学的Lily Lab建造。主要贡献者是Ansong Ni,Zhangir Azerbayev,Troy Feng,Murori Mutuma,Hailey Schoelkopf和Yusen Zhang(Penn State)。
如果您在工作中使用夏季,请考虑引用:
@article{ni2021summertime,
title={SummerTime: Text Summarization Toolkit for Non-experts},
author={Ansong Ni and Zhangir Azerbayev and Mutethia Mutuma and Troy Feng and Yusen Zhang and Tao Yu and Ahmed Hassan Awadallah and Dragomir Radev},
journal={arXiv preprint arXiv:2108.12738},
year={2021}
}
有关评论和问题,请打开一个问题。


