SummerTime
v1.2.1

Une bibliothèque pour aider les utilisateurs à choisir des outils de résumé appropriés en fonction de leurs tâches ou besoins spécifiques. Comprend des modèles, des mesures d'évaluation et des ensembles de données.
L'architecture de la bibliothèque est la suivante:
Remarque : l'été est en développement actif, tous les commentaires utiles sont fortement encouragés, veuillez ouvrir un problème ou contacter l'un des membres de l'équipe.
# install extra dependencies first
pip install pyrouge@git+https://github.com/bheinzerling/pyrouge.git
pip install en_core_web_sm@https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.0.0/en_core_web_sm-3.0.0-py3-none-any.whl
# install summertime from PyPI
pip install summertime
pip localeAlternativement, pour profiter des fonctionnalités les plus récentes, vous pouvez installer à partir de la source:
git clone [email protected]:Yale-LILY/SummerTime
pip install -e . ROUGE (lors de l'utilisation de l'évaluation) export ROUGE_HOME=/usr/local/lib/python3.7/dist-packages/summ_eval/ROUGE-1.5.5/Importe du modèle, initialise le modèle par défaut et résume des exemples de documents.
from summertime import model
sample_model = model . summarizer ()
documents = [
""" PG&E stated it scheduled the blackouts in response to forecasts for high winds amid dry conditions.
The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were scheduled to be affected
by the shutoffs which were expected to last through at least midday tomorrow."""
]
sample_model . summarize ( documents )
# ["California's largest electricity provider has turned off power to hundreds of thousands of customers."]Veuillez également exécuter notre cahier Colab pour une démo plus pratique et d'autres exemples.
Summertime prend en charge différents modèles (par exemple, Textrank, BART, LongFormer) ainsi que des emballages de modèles pour des tâches de résumé plus complexes (par exemple, JointModel pour la résumé multi-doc, BM25 Retrielal pour la résumé basé sur les requêtes). Plusieurs modèles multilingues sont également pris en charge (MT5 et MBART).
| Modèles | À un seul doc | Multi-doc | Au dialogue | À la requête | Multilingue |
|---|---|---|---|---|---|
| Bartmodel | ✔️ | ||||
| BM25SUMMMODEL | ✔️ | ||||
| Hmnetmodel | ✔️ | ||||
| Lexrankmodel | ✔️ | ||||
| LongFormermodel | ✔️ | ||||
| Mbartmodel | ✔️ | 50 langues (liste complète ici) | |||
| Mt5model | ✔️ | 101 langues (liste complète ici) | |||
| TraductionPipelineModel | ✔️ | ~ 70 langues | |||
| Multidocjointmodel | ✔️ | ||||
| Multidocseparatemodel | ✔️ | ||||
| Pegasusmodel | ✔️ | ||||
| Textrankmodel | ✔️ | ||||
| Tfidfsummmodel | ✔️ |
Pour voir tous les modèles pris en charge, exécutez:
from summertime . model import SUPPORTED_SUMM_MODELS
print ( SUPPORTED_SUMM_MODELS ) from summertime import model
# To use a default model
default_model = model . summarizer ()
# Or a specific model
bart_model = model . BartModel ()
pegasus_model = model . PegasusModel ()
lexrank_model = model . LexRankModel ()
textrank_model = model . TextRankModel ()Les utilisateurs peuvent facilement accéder à la documentation pour aider à la sélection du modèle
default_model . show_capability ()
pegasus_model . show_capability ()
textrank_model . show_capability ()Pour utiliser un modèle pour le résumé, exécutez simplement:
documents = [
""" PG&E stated it scheduled the blackouts in response to forecasts for high winds amid dry conditions.
The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were scheduled to be affected
by the shutoffs which were expected to last through at least midday tomorrow."""
]
default_model . summarize ( documents )
# or
pegasus_model . summarize ( documents )Tous les modèles peuvent être initialisés avec les options facultatives suivantes:
def __init__ ( self ,
trained_domain : str = None ,
max_input_length : int = None ,
max_output_length : int = None ,
):Tous les modèles implémenteront les méthodes suivantes:
def summarize ( self ,
corpus : Union [ List [ str ], List [ List [ str ]]],
queries : List [ str ] = None ) -> List [ str ]:
def show_capability ( cls ) -> None :Summertime prend en charge différents ensembles de données de résumé dans différents domaines (par exemple, ensemble de données CNNDM - Article de presse Corpus, Samsum - Dialogue Corpus, QM-SUM - Corpus de dialogue basé sur la requête, Multinews - Multi-Document Corpus, ML-SUM - Corpus multi-lingual, parmi les autres.
| Ensemble de données | Domaine | # Exemples | Src. longueur | Tgt. longueur | Requête | Multi-doc | Dialogue | Multilingue |
|---|---|---|---|---|---|---|---|---|
| Arxiv | Articles scientifiques | 215K | 4.9k | 220 | ||||
| CNN / DM (3.0.0) | Nouvelles | 300k | 781 | 56 | ||||
| Mlsumdataset | Nouvelles multilingues | 1,5 m + | 632 | 34 | ✔️ | Allemand, espagnol, français, russe, turc | ||
| Multi-neuf | Nouvelles | 56k | 2.1k | 263.8 | ✔️ | |||
| Samsum | Domaine libre | 16K | 94 | 20 | ✔️ | |||
| PubMedqa | Médical | 272k | 244 | 32 | ✔️ | |||
| QMSUM | Réunions | 1K | 9.0k | 69.6 | ✔️ | ✔️ | ||
| Scisummnet | Articles scientifiques | 1K | 4.7k | 150 | ||||
| Écran | Émissions de télévision | 26,9k | 6.6k | 337.4 | ✔️ | |||
| Xsum | Nouvelles | 226K | 431 | 23.3 | ||||
| Xlsum | Nouvelles | 1,35 m | ??? | ??? | 45 langues (voir documentation) | |||
| Massiveumm | Nouvelles | 12m + | ??? | ??? | 78 Langues (voir la section de résumé multilingue de ReadMe pour plus de détails) |
Pour voir tous les ensembles de données pris en charge, exécutez:
from summertime import dataset
print ( dataset . list_all_dataset ()) from summertime import dataset
cnn_dataset = dataset . CnndmDataset ()
# or
xsum_dataset = dataset . XsumDataset ()
# ..etc Tous les ensembles de données sont des implémentations de la classe SummDataset . Leurs divisions de données sont accessibles comme suit:
dataset = dataset . CnndmDataset ()
train_data = dataset . train_set
dev_data = dataset . dev_set
test_data = dataset . test_set Pour voir les détails des ensembles de données, exécutez:
dataset = dataset . CnndmDataset ()
dataset . show_description () Les données de tous les ensembles de données sont contenues dans un objet de classe SummInstance , qui possède les propriétés suivantes:
data_instance . source = source # either `List[str]` or `str`, depending on the dataset itself, string joining may needed to fit into specific models.
data_instance . summary = summary # a string summary that serves as ground truth
data_instance . query = query # Optional, applies when a string query is present
print ( data_instance ) # to print the data instance in its entiretyLes données sont chargées à l'aide d'un générateur pour économiser sur l'espace et le temps
data_instance = next ( cnn_dataset . train_set )
print ( data_instance ) import itertools
# Get a slice from the train set generator - first 5 instances
train_set = itertools . islice ( cnn_dataset . train_set , 5 )
corpus = [ instance . source for instance in train_set ]
print ( corpus ) Vous pouvez utiliser des données personnalisées à l'aide de la classe CustomDataset qui charge les données de la classe de jeu de données d'été
from summertime . dataset import CustomDataset
''' The train_set, test_set and validation_set have the following format:
List[Dict], list of dictionaries that contain a data instance.
The dictionary is in the form:
{"source": "source_data", "summary": "summary_data", "query":"query_data"}
* source_data is either of type List[str] or str
* summary_data is of type str
* query_data is of type str
The list of dictionaries looks as follows:
[dictionary_instance_1, dictionary_instance_2, ...]
'''
# Create sample data
train_set = [
{
"source" : "source1" ,
"summary" : "summary1" ,
"query" : "query1" , # only included, if query is present
}
]
validation_set = [
{
"source" : "source2" ,
"summary" : "summary2" ,
"query" : "query2" ,
}
]
test_set = [
{
"source" : "source3" ,
"summary" : "summary3" ,
"query" : "query3" ,
}
]
# Depending on the dataset properties, you can specify the type of dataset
# i.e multi_doc, query_based, dialogue_based. If not specified, they default to false
custom_dataset = CustomDataset (
train_set = train_set ,
validation_set = validation_set ,
test_set = test_set ,
query_based = True ,
multi_doc = True
dialogue_based = False ) import itertools
from summertime import dataset , model
cnn_dataset = dataset . CnndmDataset ()
# Get a slice of the train set - first 5 instances
train_set = itertools . islice ( cnn_dataset . train_set , 5 )
corpus = [ instance . source for instance in train_set ]
# Example 1 - traditional non-neural model
# LexRank model
lexrank = model . LexRankModel ( corpus )
print ( lexrank . show_capability ())
lexrank_summary = lexrank . summarize ( corpus )
print ( lexrank_summary )
# Example 2 - A spaCy pipeline for TextRank (another non-neueral extractive summarization model)
# TextRank model
textrank = model . TextRankModel ()
print ( textrank . show_capability ())
textrank_summary = textrank . summarize ( corpus )
print ( textrank_summary )
# Example 3 - A neural model to handle large texts
# LongFormer Model
longformer = model . LongFormerModel ()
longformer . show_capability ()
longformer_summary = longformer . summarize ( corpus )
print ( longformer_summary ) La méthode summarize() des modèles multilingues vérifie automatiquement le langage du document d'entrée.
Les modèles multilingues à un seul intérêt peuvent être initialisés et utilisés de la même manière que les modèles monolingues. Ils renvoient une erreur si une langue non prise en charge par le modèle est entrée.
mbart_model = st_model . MBartModel ()
mt5_model = st_model . MT5Model ()
# load Spanish portion of MLSum dataset
mlsum = datasets . MlsumDataset ([ "es" ])
corpus = itertools . islice ( mlsum . train_set , 5 )
corpus = [ instance . source for instance in train_set ]
# mt5 model will automatically detect Spanish as the language and indicate that this is supported!
mt5_model . summarize ( corpus )Les langues suivantes sont actuellement soutenues dans notre mise en œuvre de l'ensemble de données Massivesumm: Afrikaans, Amharic, Arabe, Assamais, Aymara, Azerbaïdjanais, Bambara, Bengali, Tibetan, Bosnia, Bulgarien, Catalan, Tchèque, Welsh, Danis Gujarati, Haïtien, haoussa, hébreu, hindi, croate, hongrois, arménien, igbo, indonésien, islandais, italien, japonais, kannada, géorgien, khmer, kinyarwanda, kyrgyz Malagasy, Mongolian, Burmese, South Ndebele, Nepali, Dutch, Oriya, Oromo, Punjabi, Polish, Portuguese, Dari, Pashto, Romanian, Rundi, Russian, Sinhala, Slovak, Slovenian, Shona, Somali, Spanish, Albanian, Serbian, Swahili, Swedish, Tamil, Telugu, Tetum, Tajik, Thai, Tigrinya, Turc, Ukrainien, ourdou, ouzbek, vietnamien, Xhosa, Yoruba, Yue Chinois, Chinois, Bislama et Gaelic.
Summertime prend en charge différentes mesures d'évaluation, notamment: Bertscore, Bleu, Meteor, Rouge, Rougewe
Pour imprimer toutes les mesures prises en charge:
from summertime . evaluation import SUPPORTED_EVALUATION_METRICS
print ( SUPPORTED_EVALUATION_METRICS ) import summertime . evaluation as st_eval
bert_eval = st_eval . bertscore ()
bleu_eval = st_eval . bleu_eval ()
meteor_eval = st_eval . bleu_eval ()
rouge_eval = st_eval . rouge ()
rougewe_eval = st_eval . rougewe ()Toutes les mesures d'évaluation peuvent être initialisées avec les arguments facultatifs suivants:
def __init__ ( self , metric_name ):Tous les objets métriques d'évaluation mettent en œuvre les méthodes suivantes:
def evaluate ( self , model , data ):
def get_dict ( self , keys ):Obtenez des exemples de données de résumé
from summertime . evaluation . base_metric import SummMetric
from summertime . evaluation import Rouge , RougeWe , BertScore
import itertools
# Evaluates model on subset of cnn_dailymail
# Get a slice of the train set - first 5 instances
train_set = itertools . islice ( cnn_dataset . train_set , 5 )
corpus = [ instance for instance in train_set ]
print ( corpus )
articles = [ instance . source for instance in corpus ]
summaries = sample_model . summarize ( articles )
targets = [ instance . summary for instance in corpus ]Évaluez les données sur différentes mesures
from summertime . evaluation import BertScore , Rouge , RougeWe ,
# Calculate BertScore
bert_metric = BertScore ()
bert_score = bert_metric . evaluate ( summaries , targets )
print ( bert_score )
# Calculate Rouge
rouge_metric = Rouge ()
rouge_score = rouge_metric . evaluate ( summaries , targets )
print ( rouge_score )
# Calculate RougeWe
rougewe_metric = RougeWe ()
rougwe_score = rougewe_metric . evaluate ( summaries , targets )
print ( rougewe_score ) Compte tenu d'un ensemble de données d'été, vous pouvez utiliser la fonction pipelines.assemble_model_pipeline pour récupérer une liste de modèles d'été initialisés compatibles avec l'ensemble de données fourni.
from summertime . pipeline import assemble_model_pipeline
from summertime . dataset import CnndmDataset , QMsumDataset
single_doc_models = assemble_model_pipeline ( CnndmDataset )
# [
# (<model.single_doc.bart_model.BartModel object at 0x7fcd43aa12e0>, 'BART'),
# (<model.single_doc.lexrank_model.LexRankModel object at 0x7fcd43aa1460>, 'LexRank'),
# (<model.single_doc.longformer_model.LongformerModel object at 0x7fcd43b17670>, 'Longformer'),
# (<model.single_doc.pegasus_model.PegasusModel object at 0x7fccb84f2910>, 'Pegasus'),
# (<model.single_doc.textrank_model.TextRankModel object at 0x7fccb84f2880>, 'TextRank')
# ]
query_based_multi_doc_models = assemble_model_pipeline ( QMsumDataset )
# [
# (<model.query_based.tf_idf_model.TFIDFSummModel object at 0x7fc9c9c81e20>, 'TF-IDF (HMNET)'),
# (<model.query_based.bm25_model.BM25SummModel object at 0x7fc8b4fa8c10>, 'BM25 (HMNET)')
# ]=======
Compte tenu d'un ensemble de données d'été, vous pouvez utiliser la fonction pipelines.assemble_model_pipeline pour récupérer une liste de modèles d'été initialisés compatibles avec l'ensemble de données fourni.
# Get test data
import itertools
from summertime . dataset import XsumDataset
# Get a slice of the train set - first 5 instances
sample_dataset = XsumDataset ()
sample_data = itertools . islice ( sample_dataset . train_set , 100 )
generator1 = iter ( sample_data )
generator2 = iter ( sample_data )
bart_model = BartModel ()
pegasus_model = PegasusModel ()
models = [ bart_model , pegasus_model ]
metrics = [ metric () for metric in SUPPORTED_EVALUATION_METRICS ] from summertime . evaluation . model_selector import ModelSelector
selector = ModelSelector ( models , generator1 , metrics )
table = selector . run ()
print ( table )
visualization = selector . visualize ( table )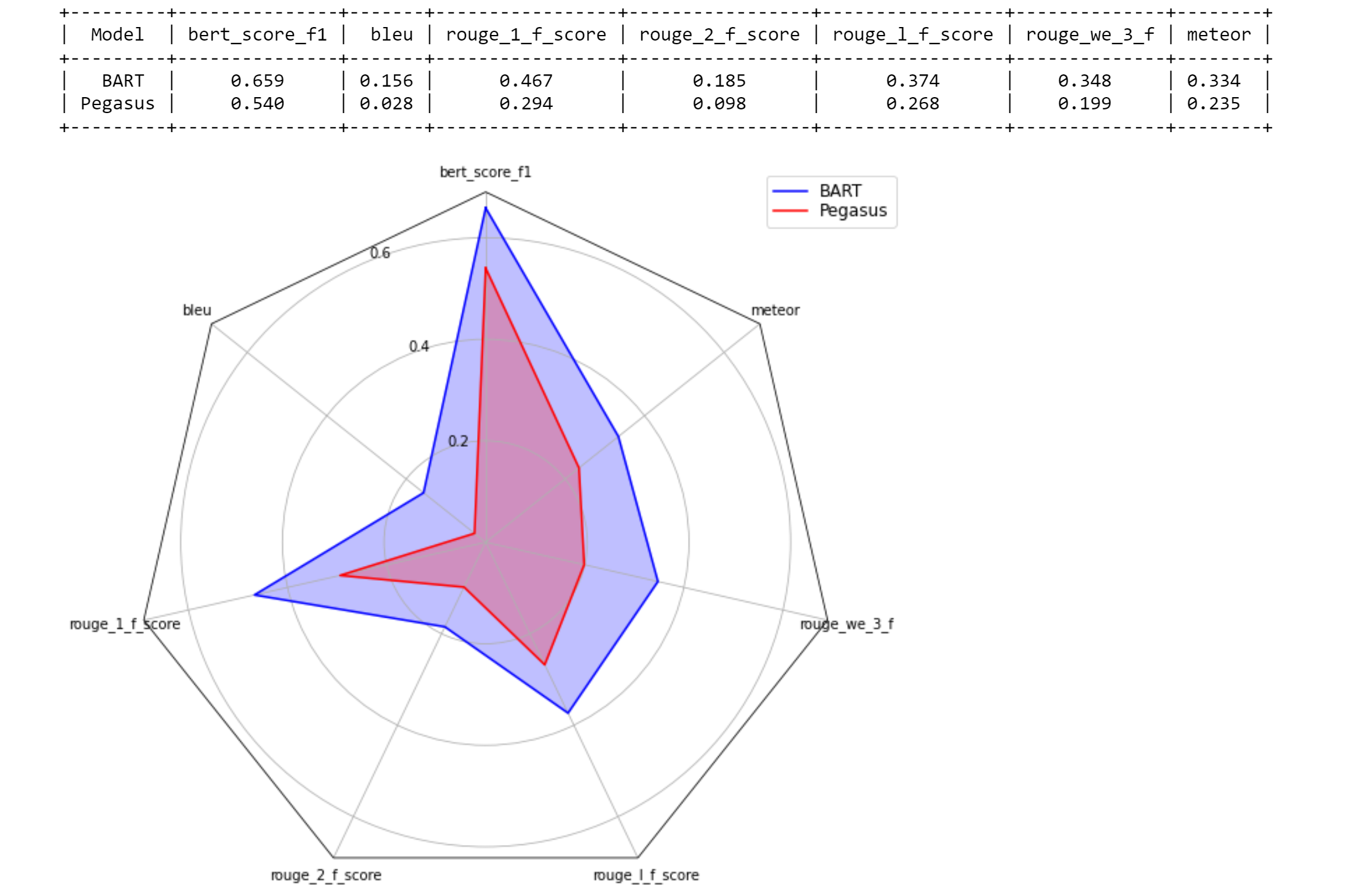
from summertime . evaluation . model_selector import ModelSelector
new_selector = ModelSelector ( models , generator2 , metrics )
smart_table = new_selector . run_halving ( min_instances = 2 , factor = 2 )
print ( smart_table )
visualization_smart = selector . visualize ( smart_table ) from summertime . evaluation . model_selector import ModelSelector
from summertime . evaluation . error_viz import scatter
keys = ( "bert_score_f1" , "bleu" , "rouge_1_f_score" , "rouge_2_f_score" , "rouge_l_f_score" , "rouge_we_3_f" , "meteor" )
scatter ( models , sample_data , metrics [ 1 : 3 ], keys = keys [ 1 : 3 ], max_instances = 5 )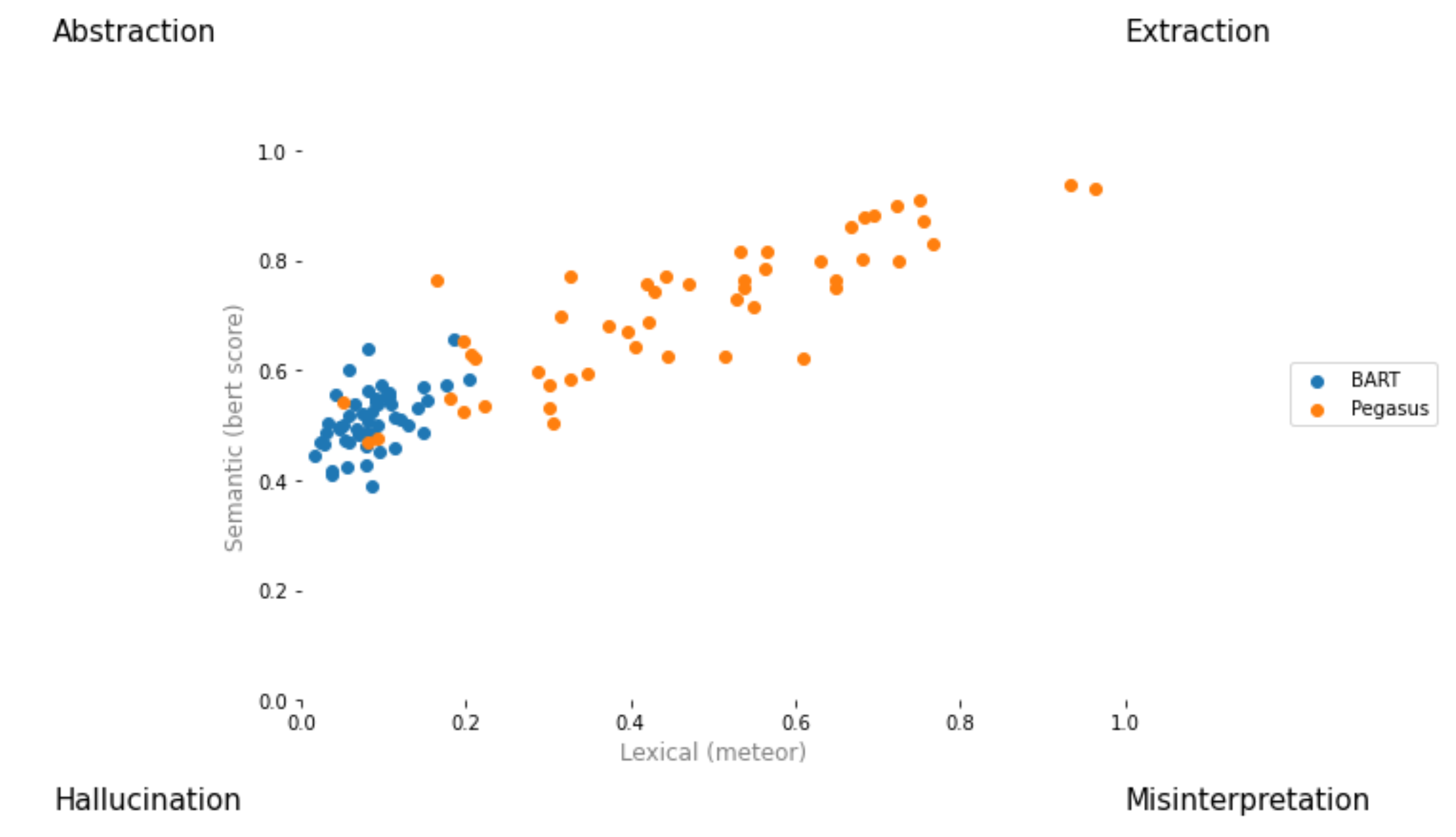
Créez une demande de pull et nommez-le [ your_gh_username ] / [ your_branch_name ]. Si nécessaire, résolvez les conflits de fusion de votre propre succursale avec Main. Ne poussez pas directement vers Main.
Si vous ne l'avez pas déjà fait, installez black et flake8 :
pip install black
pip install flake8 Avant de pousser les engagements ou de fusionner les branches, exécutez les commandes suivantes à partir de la racine du projet. Notez que black écrira dans les fichiers et que vous devez ajouter et commettre des modifications apportées par black avant de pousser:
black .
flake8 .Ou si vous souhaitez peser des fichiers spécifiques:
black path/to/specific/file.py
flake8 path/to/specific/file.py Assurez-vous que black ne reforma des fichiers et que flake8 n'imprime aucune erreur. Si vous souhaitez remplacer ou ignorer l'une des préférences ou des pratiques appliquées par black ou flake8 , veuillez laisser un commentaire dans vos relations publiques pour toutes les lignes de code qui génèrent des journaux d'avertissement ou d'erreur. Ne modifiez pas directement des fichiers de configuration tels que setup.cfg .
Voir les docs black et les documents flake8 pour la documentation sur l'installation, l'ignorance des fichiers / lignes et une utilisation avancée. De plus, ce qui suit peut être utile:
black [file.py] --diff pour prévisualiser les modifications sous forme de diffs au lieu de modifier directement les modificationsblack [file.py] --check Vérifier les modifications de prévisualisation avec les codes d'état au lieu de modifier directement les modificationsgit diff -u | flake8 --diff pour exécuter Flake8 sur les modifications de la branche de travail Notez que notre suite de tests CI comprendra invoquer black --check . et flake8 --count . Sur tous les fichiers Python non inunis et non établis, et une sortie au niveau de l'erreur zéro est requise pour que tous les tests passent.
Notre système d'intégration continue est fourni par des actions GitHub. Lorsqu'une demande de traction est créée ou mise à jour ou chaque fois que main est mis à jour, les tests unitaires du référentiel seront exécutés en tant que travaux de création sur Tangra pour cette demande de traction. Les travaux de construction passeront ou échoueront en quelques minutes, et les statuts de construction et les journaux sont visibles sous les actions. Veuillez vous assurer que le commit le plus récent dans les demandes de traction transmet tous les chèques (c'est-à-dire toutes les étapes de tous les travaux à compléter) avant de fusionner ou demander un examen. Pour sauter une construction sur un engagement particulier, ajoutez [skip ci] au message de validation. Notez que PRS avec la sous-chaîne /no-ci/ n'importe où dans le nom de la branche ne sera pas inclus dans CI.
Ce référentiel est construit par le Lily Lab de l'Université de Yale, dirigée par le professeur Dragomir Radev. Les principaux contributeurs sont Ansong Ni, Zhangir Azerbayev, Troy Feng, Murori Mutuma, Hailey Schoelkopf et Yusen Zhang (Penn State).
Si vous utilisez l'été dans votre travail, envisagez de citer:
@article{ni2021summertime,
title={SummerTime: Text Summarization Toolkit for Non-experts},
author={Ansong Ni and Zhangir Azerbayev and Mutethia Mutuma and Troy Feng and Yusen Zhang and Tao Yu and Ahmed Hassan Awadallah and Dragomir Radev},
journal={arXiv preprint arXiv:2108.12738},
year={2021}
}
Pour des commentaires et des questions, veuillez ouvrir un problème.


