SummerTime
v1.2.1

ユーザーが特定のタスクまたはニーズに基づいて適切な要約ツールを選択できるようにするライブラリ。モデル、評価メトリック、およびデータセットが含まれます。
ライブラリアーキテクチャは次のとおりです。
注:Summertimeは積極的な開発中です。有益なコメントは強くお勧めします。問題を開いたり、チームメンバーに連絡してください。
# install extra dependencies first
pip install pyrouge@git+https://github.com/bheinzerling/pyrouge.git
pip install en_core_web_sm@https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.0.0/en_core_web_sm-3.0.0-py3-none-any.whl
# install summertime from PyPI
pip install summertime
pipインストールまたは、最新の機能を楽しむには、ソースからインストールできます。
git clone [email protected]:Yale-LILY/SummerTime
pip install -e . ROUGE (評価を使用する場合) export ROUGE_HOME=/usr/local/lib/python3.7/dist-packages/summ_eval/ROUGE-1.5.5/モデルをインポートし、デフォルトモデルを初期化し、サンプルドキュメントを要約します。
from summertime import model
sample_model = model . summarizer ()
documents = [
""" PG&E stated it scheduled the blackouts in response to forecasts for high winds amid dry conditions.
The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were scheduled to be affected
by the shutoffs which were expected to last through at least midday tomorrow."""
]
sample_model . summarize ( documents )
# ["California's largest electricity provider has turned off power to hundreds of thousands of customers."]また、より実践的なデモなどの例については、Colabノートブックを実行してください。
Summertimeは、より複雑な要約タスク(例、マルチドック要約のジョイントモデル、クエリベースの要約のためのBM25検索)のモデルラッパーと同様に、さまざまなモデル(例えば、テキストラン、バート、ロングフォーカー)とモデルラッパーをサポートします。いくつかの多言語モデルもサポートされています(MT5およびMBART)。
| モデル | シングルドック | マルチドック | 対話ベース | クエリベース | 多言語 |
|---|---|---|---|---|---|
| バートモデル | ✔✔️ | ||||
| BM25SUMMMODEL | ✔✔️ | ||||
| hmnetmodel | ✔✔️ | ||||
| lexrankmodel | ✔✔️ | ||||
| longformermodel | ✔✔️ | ||||
| mbartmodel | ✔✔️ | 50言語(ここに完全なリスト) | |||
| mt5model | ✔✔️ | 101言語(ここに完全なリスト) | |||
| TranslationPipelineModel | ✔✔️ | 〜70言語 | |||
| MultidocjointModel | ✔✔️ | ||||
| MultidocseParateModel | ✔✔️ | ||||
| PegasusModel | ✔✔️ | ||||
| textrankmodel | ✔✔️ | ||||
| tfidfsummmodel | ✔✔️ |
サポートされているすべてのモデルを表示するには、実行してください。
from summertime . model import SUPPORTED_SUMM_MODELS
print ( SUPPORTED_SUMM_MODELS ) from summertime import model
# To use a default model
default_model = model . summarizer ()
# Or a specific model
bart_model = model . BartModel ()
pegasus_model = model . PegasusModel ()
lexrank_model = model . LexRankModel ()
textrank_model = model . TextRankModel ()ユーザーはドキュメントに簡単にアクセスしてモデルの選択を支援できます
default_model . show_capability ()
pegasus_model . show_capability ()
textrank_model . show_capability ()要約にモデルを使用するには、単純に実行します。
documents = [
""" PG&E stated it scheduled the blackouts in response to forecasts for high winds amid dry conditions.
The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were scheduled to be affected
by the shutoffs which were expected to last through at least midday tomorrow."""
]
default_model . summarize ( documents )
# or
pegasus_model . summarize ( documents )すべてのモデルは、次のオプションオプションで初期化できます。
def __init__ ( self ,
trained_domain : str = None ,
max_input_length : int = None ,
max_output_length : int = None ,
):すべてのモデルが次の方法を実装します。
def summarize ( self ,
corpus : Union [ List [ str ], List [ List [ str ]]],
queries : List [ str ] = None ) -> List [ str ]:
def show_capability ( cls ) -> None :サマータイムは、さまざまなドメインのさまざまな要約データセットをサポートしています(例:CNNDMデータセット - ニュース記事コーパス、サムスム - ダイアログコーパス、QMサム - クエリベースのダイアログコーパス、マルチドキュメントコーパス、ML -sum -Sum -Multiningual Corpus、Pubqa -domain、Arxiv -Science Paper
| データセット | ドメイン | #例 | SRC。長さ | TGT。長さ | クエリ | マルチドック | 対話 | 多言語 |
|---|---|---|---|---|---|---|---|---|
| arxiv | 科学記事 | 215K | 4.9k | 220 | ||||
| CNN/DM(3.0.0) | ニュース | 300k | 781 | 56 | ||||
| mlsumdataset | 多言語ニュース | 1.5m+ | 632 | 34 | ✔✔️ | ドイツ語、スペイン語、フランス語、ロシア語、トルコ語 | ||
| マルチニュース | ニュース | 56K | 2.1k | 263.8 | ✔✔️ | |||
| サムスム | オープンドメイン | 16K | 94 | 20 | ✔✔️ | |||
| PubMedqa | 医学 | 272K | 244 | 32 | ✔✔️ | |||
| QMSUM | 会議 | 1k | 9.0k | 69.6 | ✔✔️ | ✔✔️ | ||
| scisummnet | 科学記事 | 1k | 4.7k | 150 | ||||
| サムスクリーン | テレビ番組 | 26.9k | 6.6k | 337.4 | ✔✔️ | |||
| xsum | ニュース | 226K | 431 | 23.3 | ||||
| xlsum | ニュース | 1.35m | ??? | ??? | 45言語(ドキュメントを参照) | |||
| Massivesumm | ニュース | 12m+ | ??? | ??? | 78言語(詳細については、READMEの多言語要約セクションを参照) |
サポートされているすべてのデータセットを表示するには、実行してください。
from summertime import dataset
print ( dataset . list_all_dataset ()) from summertime import dataset
cnn_dataset = dataset . CnndmDataset ()
# or
xsum_dataset = dataset . XsumDataset ()
# ..etc すべてのデータセットは、 SummDatasetクラスの実装です。彼らのデータ分裂は次のようにアクセスできます。
dataset = dataset . CnndmDataset ()
train_data = dataset . train_set
dev_data = dataset . dev_set
test_data = dataset . test_set データセットの詳細を確認するには、実行してください。
dataset = dataset . CnndmDataset ()
dataset . show_description ()すべてのデータセットのデータは、次のプロパティがあるSummInstanceクラスオブジェクトに含まれています。
data_instance . source = source # either `List[str]` or `str`, depending on the dataset itself, string joining may needed to fit into specific models.
data_instance . summary = summary # a string summary that serves as ground truth
data_instance . query = query # Optional, applies when a string query is present
print ( data_instance ) # to print the data instance in its entiretyデータは、発電機を使用して空間と時間を節約するためにロードされます
data_instance = next ( cnn_dataset . train_set )
print ( data_instance ) import itertools
# Get a slice from the train set generator - first 5 instances
train_set = itertools . islice ( cnn_dataset . train_set , 5 )
corpus = [ instance . source for instance in train_set ]
print ( corpus )Summertime DatasetクラスにデータをロードするCustomDatasetクラスを使用してカスタムデータを使用できます
from summertime . dataset import CustomDataset
''' The train_set, test_set and validation_set have the following format:
List[Dict], list of dictionaries that contain a data instance.
The dictionary is in the form:
{"source": "source_data", "summary": "summary_data", "query":"query_data"}
* source_data is either of type List[str] or str
* summary_data is of type str
* query_data is of type str
The list of dictionaries looks as follows:
[dictionary_instance_1, dictionary_instance_2, ...]
'''
# Create sample data
train_set = [
{
"source" : "source1" ,
"summary" : "summary1" ,
"query" : "query1" , # only included, if query is present
}
]
validation_set = [
{
"source" : "source2" ,
"summary" : "summary2" ,
"query" : "query2" ,
}
]
test_set = [
{
"source" : "source3" ,
"summary" : "summary3" ,
"query" : "query3" ,
}
]
# Depending on the dataset properties, you can specify the type of dataset
# i.e multi_doc, query_based, dialogue_based. If not specified, they default to false
custom_dataset = CustomDataset (
train_set = train_set ,
validation_set = validation_set ,
test_set = test_set ,
query_based = True ,
multi_doc = True
dialogue_based = False ) import itertools
from summertime import dataset , model
cnn_dataset = dataset . CnndmDataset ()
# Get a slice of the train set - first 5 instances
train_set = itertools . islice ( cnn_dataset . train_set , 5 )
corpus = [ instance . source for instance in train_set ]
# Example 1 - traditional non-neural model
# LexRank model
lexrank = model . LexRankModel ( corpus )
print ( lexrank . show_capability ())
lexrank_summary = lexrank . summarize ( corpus )
print ( lexrank_summary )
# Example 2 - A spaCy pipeline for TextRank (another non-neueral extractive summarization model)
# TextRank model
textrank = model . TextRankModel ()
print ( textrank . show_capability ())
textrank_summary = textrank . summarize ( corpus )
print ( textrank_summary )
# Example 3 - A neural model to handle large texts
# LongFormer Model
longformer = model . LongFormerModel ()
longformer . show_capability ()
longformer_summary = longformer . summarize ( corpus )
print ( longformer_summary )多言語モデルのsummarize()メソッドは、入力ドキュメント言語を自動的にチェックします。
単一言語モデルと同じ方法で、単一ドック多言語モデルを初期化して使用できます。モデルでサポートされていない言語が入力されている場合、エラーを返します。
mbart_model = st_model . MBartModel ()
mt5_model = st_model . MT5Model ()
# load Spanish portion of MLSum dataset
mlsum = datasets . MlsumDataset ([ "es" ])
corpus = itertools . islice ( mlsum . train_set , 5 )
corpus = [ instance . source for instance in train_set ]
# mt5 model will automatically detect Spanish as the language and indicate that this is supported!
mt5_model . summarize ( corpus )Massivesumm Datasetの実装では現在、次の言語がサポートされています:アフリカ人、アフリック、アラビア語、アッサム、アイマラ、アゼルバイジャン、バンバラ、ベンガル語、チベット、ボスニア、ブルガリア語、カタロニア、チェコ、ウェールシュ、ダニッシュ、ドイツ語、ギリシャ語、イギリス、イギリス、イギリス、イギリス、イギリス、イギリス、イギリス、イギリス、イギリス、イギリス、グジャラート語、ハイチ人、ハウサ、ヘブライ語、ヒンディー語、クロアチア語、ハンガリー語、アルメニア語、イゴ、インドネシア語、アイスランド語、イタリア語、日本語、カンナダ語、ジョージア語、クメール、キニャルワンダモンゴル人、ビルマ人、南ヌデベレ、ネパール、オランダ、オリヤ、オロモ、パンジャブ、ポーランド、ポルトガル人、ダリ、パシュ、ルーマニア人、ランディ、ロシア、シンハラ、スロバキア、スロバニア、ショナ、ソマリ、スペイン人、セルビアン、セルビアン、スワヒリ、スワヒリ、町タジク、タイ、ティグリニャ、トルコ語、ウクライナ人、ウルドゥー語、ウズベック、ベトナム、Xhosa、ヨルバ、ユエ中国語、中国語、ビスラマ、ゲーリック。
サマータイムは、Bertscore、Bleu、Meteor、Rouge、Rougeweなど、さまざまな評価メトリックをサポートしています。
サポートされているすべてのメトリックを印刷するには:
from summertime . evaluation import SUPPORTED_EVALUATION_METRICS
print ( SUPPORTED_EVALUATION_METRICS ) import summertime . evaluation as st_eval
bert_eval = st_eval . bertscore ()
bleu_eval = st_eval . bleu_eval ()
meteor_eval = st_eval . bleu_eval ()
rouge_eval = st_eval . rouge ()
rougewe_eval = st_eval . rougewe ()すべての評価メトリックは、次のオプションの引数で初期化できます。
def __init__ ( self , metric_name ):すべての評価メトリックオブジェクトは、次の方法を実装します。
def evaluate ( self , model , data ):
def get_dict ( self , keys ):サンプルの概要データを取得します
from summertime . evaluation . base_metric import SummMetric
from summertime . evaluation import Rouge , RougeWe , BertScore
import itertools
# Evaluates model on subset of cnn_dailymail
# Get a slice of the train set - first 5 instances
train_set = itertools . islice ( cnn_dataset . train_set , 5 )
corpus = [ instance for instance in train_set ]
print ( corpus )
articles = [ instance . source for instance in corpus ]
summaries = sample_model . summarize ( articles )
targets = [ instance . summary for instance in corpus ]さまざまなメトリックのデータを評価します
from summertime . evaluation import BertScore , Rouge , RougeWe ,
# Calculate BertScore
bert_metric = BertScore ()
bert_score = bert_metric . evaluate ( summaries , targets )
print ( bert_score )
# Calculate Rouge
rouge_metric = Rouge ()
rouge_score = rouge_metric . evaluate ( summaries , targets )
print ( rouge_score )
# Calculate RougeWe
rougewe_metric = RougeWe ()
rougwe_score = rougewe_metric . evaluate ( summaries , targets )
print ( rougewe_score )夏のデータセットが与えられた場合、 pipelines.assemble_model_pipeline関数を使用して、提供されたデータセットと互換性のある初期化されたサマータイムモデルのリストを取得できます。
from summertime . pipeline import assemble_model_pipeline
from summertime . dataset import CnndmDataset , QMsumDataset
single_doc_models = assemble_model_pipeline ( CnndmDataset )
# [
# (<model.single_doc.bart_model.BartModel object at 0x7fcd43aa12e0>, 'BART'),
# (<model.single_doc.lexrank_model.LexRankModel object at 0x7fcd43aa1460>, 'LexRank'),
# (<model.single_doc.longformer_model.LongformerModel object at 0x7fcd43b17670>, 'Longformer'),
# (<model.single_doc.pegasus_model.PegasusModel object at 0x7fccb84f2910>, 'Pegasus'),
# (<model.single_doc.textrank_model.TextRankModel object at 0x7fccb84f2880>, 'TextRank')
# ]
query_based_multi_doc_models = assemble_model_pipeline ( QMsumDataset )
# [
# (<model.query_based.tf_idf_model.TFIDFSummModel object at 0x7fc9c9c81e20>, 'TF-IDF (HMNET)'),
# (<model.query_based.bm25_model.BM25SummModel object at 0x7fc8b4fa8c10>, 'BM25 (HMNET)')
# ]=======
夏のデータセットが与えられた場合、pipelines.assemble_model_pipeline関数を使用して、提供されたデータセットと互換性のある初期化されたサマータイムモデルのリストを取得できます。
# Get test data
import itertools
from summertime . dataset import XsumDataset
# Get a slice of the train set - first 5 instances
sample_dataset = XsumDataset ()
sample_data = itertools . islice ( sample_dataset . train_set , 100 )
generator1 = iter ( sample_data )
generator2 = iter ( sample_data )
bart_model = BartModel ()
pegasus_model = PegasusModel ()
models = [ bart_model , pegasus_model ]
metrics = [ metric () for metric in SUPPORTED_EVALUATION_METRICS ] from summertime . evaluation . model_selector import ModelSelector
selector = ModelSelector ( models , generator1 , metrics )
table = selector . run ()
print ( table )
visualization = selector . visualize ( table )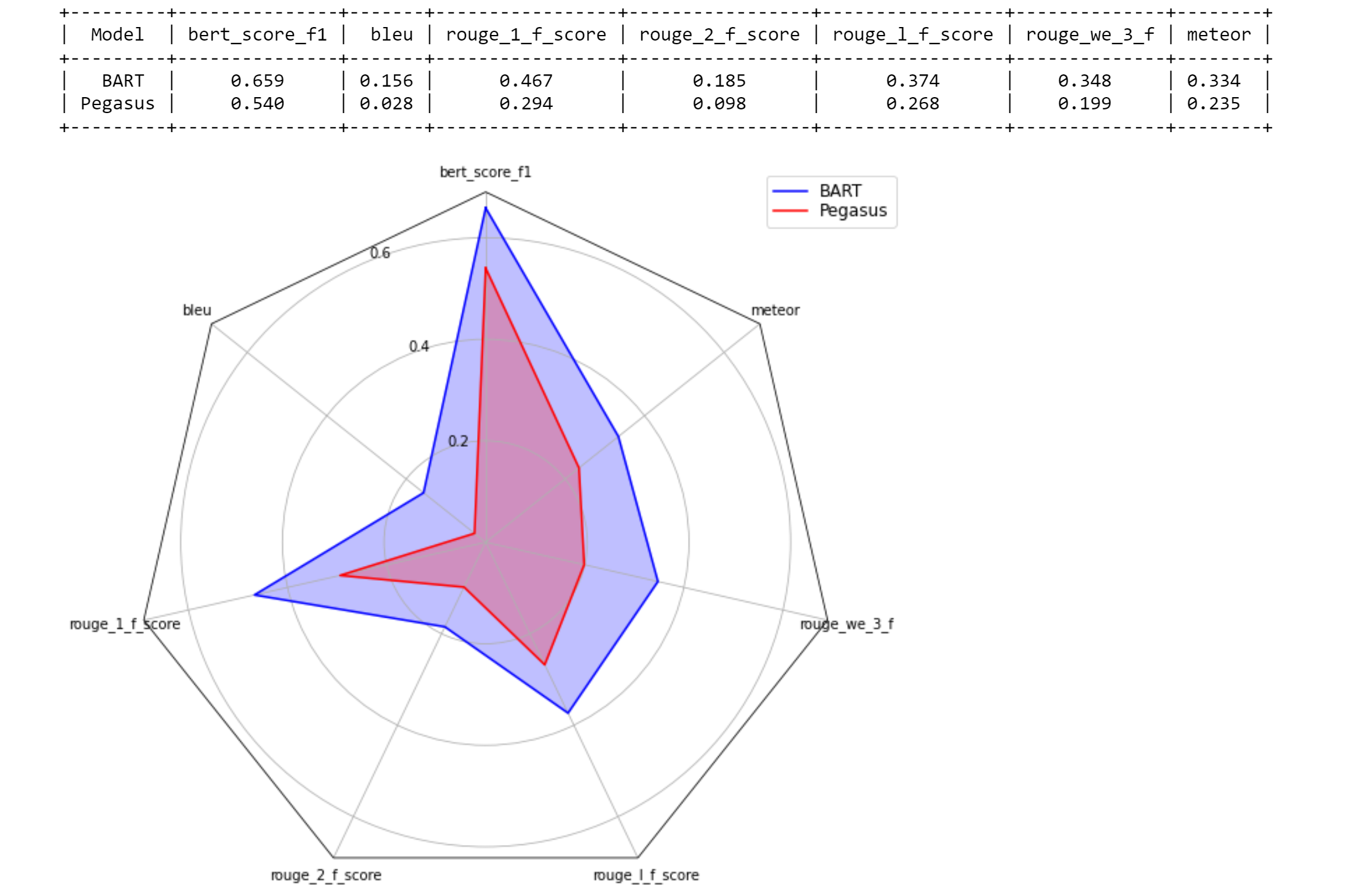
from summertime . evaluation . model_selector import ModelSelector
new_selector = ModelSelector ( models , generator2 , metrics )
smart_table = new_selector . run_halving ( min_instances = 2 , factor = 2 )
print ( smart_table )
visualization_smart = selector . visualize ( smart_table ) from summertime . evaluation . model_selector import ModelSelector
from summertime . evaluation . error_viz import scatter
keys = ( "bert_score_f1" , "bleu" , "rouge_1_f_score" , "rouge_2_f_score" , "rouge_l_f_score" , "rouge_we_3_f" , "meteor" )
scatter ( models , sample_data , metrics [ 1 : 3 ], keys = keys [ 1 : 3 ], max_instances = 5 )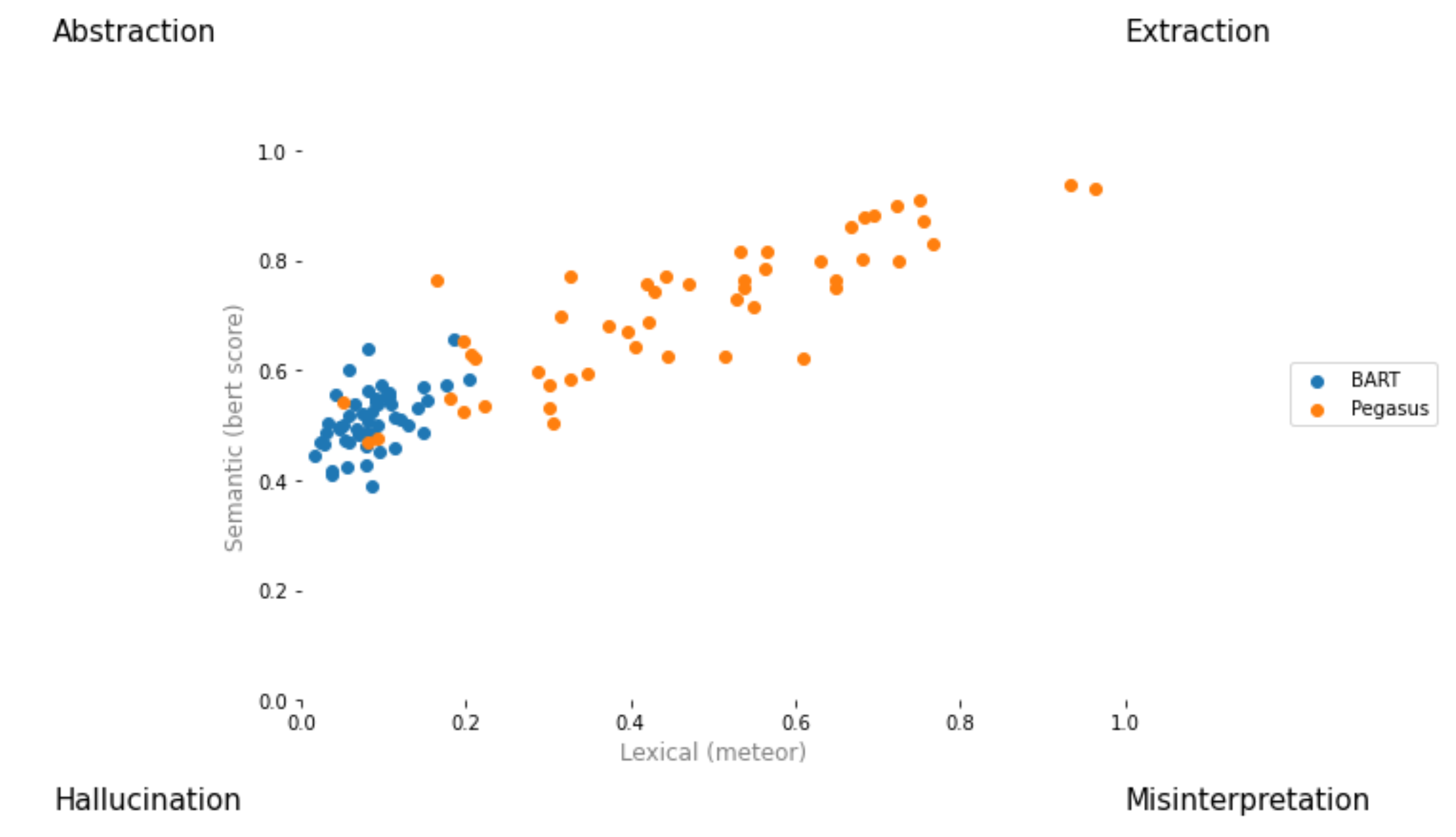
プルリクエストを作成して、[ your_gh_username ]/[ your_branch_name ]に名前を付けます。必要に応じて、メインとの自分のブランチのマージの競合を解決します。メインに直接プッシュしないでください。
まだ行っていない場合は、 blackとflake8をインストールしてください。
pip install black
pip install flake8コミットを押したり、ブランチをマージしたりする前に、プロジェクトルートから次のコマンドを実行します。 blackはファイルに書き込み、プッシュする前にblackによって変更された変更を追加およびコミットする必要があることに注意してください。
black .
flake8 .または、特定のファイルを並べたい場合は:
black path/to/specific/file.py
flake8 path/to/specific/file.py blackファイルを再フォーマットせず、 flake8がエラーを印刷しないことを確認してください。 blackまたはflake8によって施行された設定またはプラクティスをオーバーライドまたは無視したい場合は、警告またはエラーログを生成するコードの行についてコメントをPRに残してください。 setup.cfgなどの構成ファイルを直接編集しないでください。
インストール、ファイル/行の無視、高度な使用に関するドキュメントについては、 blackドキュメントとflake8ドキュメントを参照してください。さらに、以下が役立つ場合があります。
black [file.py] --diffblack [file.py] --check変更する代わりにステータスコードで変更をプレビューするためにチェックgit diff -u | flake8 --diff作業ブランチの変更でflake8のみを実行するためにディフCIテストスイートにはblack --check .およびflake8 --count .すべての非接着および非セットアップPythonファイルで、すべてのテストに合格するにはゼロエラーレベルの出力が必要です。
継続的な統合システムは、GitHubアクションを通じて提供されます。プルリクエストが作成または更新される場合、またはmainが更新されるときはいつでも、リポジトリのユニットテストは、そのプルリクエストのためにタングラのビルドジョブとして実行されます。ビルドジョブは数分以内に合格または失敗し、アクションの下でステータスとログをビルドすることが表示されます。プルリクエストでの最新のコミットがすべてのチェック(つまり、すべてのジョブのすべてのステップが完了する)に合格するか、マージする前に確認するか、レビューをリクエストしてください。特定のコミットに基づいてビルドをスキップするには、 [skip ci]コミットメッセージに追加します。支店名のサブストリング/no-ci/ whypheryを備えたPRSはCIに含まれないことに注意してください。
このリポジトリは、イェール大学のリリーラボによって建設され、ドラゴミールラデフ教授が率いています。主な貢献者は、Ansong Ni、Zhangir Azerbayev、Troy Feng、Murori Mutuma、Hailey Schoelkopf、およびYusen Zhang(ペンシルベニア州)です。
仕事で夏を使用する場合は、引用することを検討してください。
@article{ni2021summertime,
title={SummerTime: Text Summarization Toolkit for Non-experts},
author={Ansong Ni and Zhangir Azerbayev and Mutethia Mutuma and Troy Feng and Yusen Zhang and Tao Yu and Ahmed Hassan Awadallah and Dragomir Radev},
journal={arXiv preprint arXiv:2108.12738},
year={2021}
}
コメントと質問については、問題を開いてください。


